# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
智源统一图像生成模型OmniGen2发布后,立刻在AI图像生成领域掀起巨响,多模态技术生态进一步打通。才一周,GitHub星标就已经破了2000,X上的话题浏览数直接破数十万。
刚刚,统一图像生成模型OmniGen2携重大升级震撼登场。
2024年9月,智源首次放出OmniGen,凭借高度通用性和简洁架构,深受AI社区广泛好评。
凭借单一模型,它不仅支持文本生图像、图像编辑、主题驱动图像生成等多种任务,彻底颠覆了传统多模态模型的复杂设计。
如今,全新4B版OmniGen2在继承简洁架构的基础上,大幅提升了上下文理解与指令遵循能力,在图像生成质量实现了质的飞跃。
Github:https://github.com/VectorSpaceLab/OmniGen2/
论文:https://arxiv.org/abs/2506.18871
模型:https://huggingface.co/BAAI/OmniGen2
它深度融合基座多模态大模型的强大能力,支持图像与文字的无缝集成,彻底打破了多模态技术生态。
更令人振奋的是,OmniGen2模型权重、训练代码、训练数据全面开源。
仅发布一周,其在GitHub星标突破2000,X上相关话题浏览量数十万。
OmniGen2将为全球开发者提供无限可能,加速统一图像生成模型从前沿构想迈向广泛应用的现实。
在实际测试中,OmniGen2有多惊艳?
OmniGen2的玩法简单,只需要输入提示词,就能解锁丰富的图像编辑与生成能力。
现在,科研体验版已开放,可抢先尝试图像编辑、上下文参照的图像生成等特色能力。

科研体验版链接:https://genai.baai.ac.cn
「动嘴」编辑图像
OmniGen2可以通过自然语言指令,实现编辑图片的功能,以及局部修改操作。
其中包括,物体增删、颜色调整、人物表情修改、背景替换等等。
它可以给太乙真人上个「挥手」动作,让黄色裙子变成蓝色,甚至,还能为二次元老婆换上教室背景图。

当你说一句,「移除猫」,猫就消失了。

如下,还有更多的demo示例。


注:图片仅为科研使用,如有任何问题请与智源研究院联系
多模态上下文参考
更令人惊艳的是,OmniGen2还可以从输入图像中提取指定元素,并基于此生成新图像。
如下图所示,提供两张参考图,AI可以瞬间将其无缝合成一张,毫无违和感。

再比如,将第一张图中苹果,替换成第二张图片中的猫,OmniGen2瞬间完成。

顺便提一句,当前OmniGen2更擅长保持物体相似度,而不是人脸相似度。

注:图片仅为科研使用,如有任何问题请与智源研究院联系
此外,OmniGen2还能生成任意比例的图片,1:1、2:1、3:2等任意比例均可以。

可以看到,OmniGen2在AI图像编辑达到了一个全新高度。它能够取得如此惊艳的表现,离不开背后独创核心技术架构。
分离式架构与双编码器策略
OmniGen2采取了分离式架构解耦文本和图像,同时采用了ViT和VAE的双编码器策略。
不同于其他研究,ViT和VAE独立作用于MLLM和Diffusion Transformer中,提高图像一致性的同时保证原有的文字生成能力。

数据生成流程重构
OmniGen2也在探索解决阻碍领域发展的基础数据和评估方面的难题。
相关的开源数据集大多存在固有的质量缺陷,尤其是在图像编辑任务中,图像质量和质量准确度都不高。
而对于图片上下文参考生成任务,社区中缺乏相应的大规模多样化的训练数据。
这些缺陷极大地导致了开源模型和商业模型之间显著的性能差距。
为了解决这个问题,OmniGen2开发了一个从视频数据和图像数据中生成图像编辑和上下文参考数据的构造流程。

图像生成反思机制
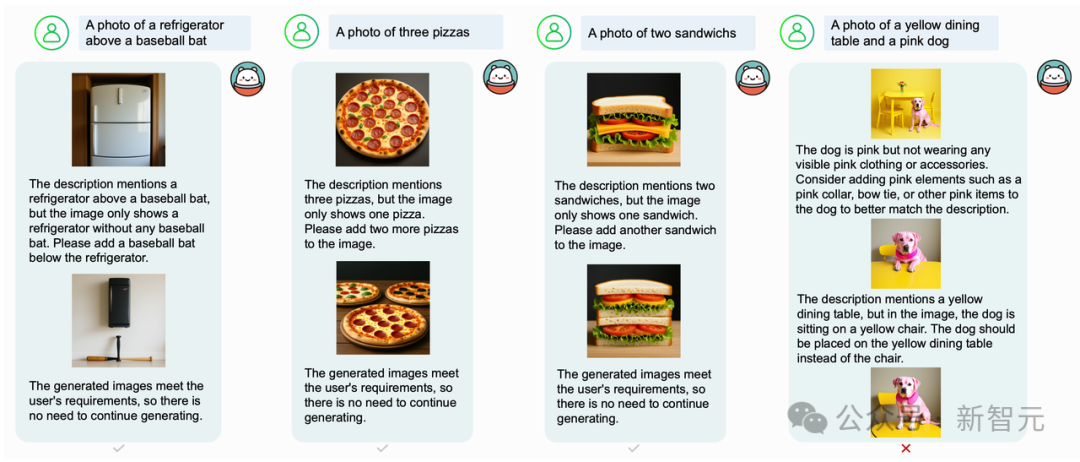
受到大型语言模型自我反思能力的启发,OmniGen2还探索了将反思能力整合到多模态生成模型中的策略。
基于OmniGen2的基础模型构建了面对图像生成的反思数据。
反思数据由文本和图像的交错序列组成,首先是一个用户指令,接着是多模态模型生成的图像,然后是针对之前生成输出的逐步反思。
每条反思都涉及两个关键方面:
1)对与原始指令相关的缺陷或未满足要求的分析;
2)为解决前一幅图像的局限性而提出的解决方案。

经过训练的模型具备初步的反思能力,未来目标是进一步使用强化学习进行训练。
OmniGen2在已有基准上取得了颇具竞争力的结果,包括文生图,图像编辑。
然而,对于图片上下文参考生成(in-context generation)任务,目前还缺乏完善的公共基准来系统地评估和比较不同模型的关键能力。
现有的上下文图像生成基准在捕获实际应用场景方面存在不足。
它们不考虑具有多个输入图像的场景,并且受到上下文类型和任务类型的限制。同时,先前的基准使用CLIP-I和DINO指标来评估上下文生成的图像的质量。
这些指标依赖于输入和输出之间的图像级相似性,这使得它们不适用于涉及多个主题的场景,并且缺乏可解释性。
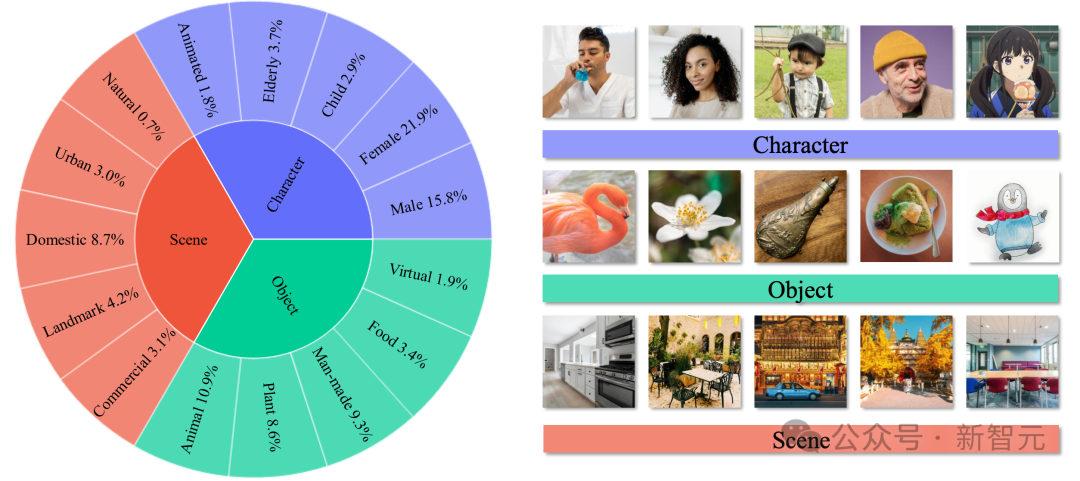
为了解决这一限制,智源引入了OmniContext基准,其中包括8个任务类别,专门用于评估个人、物体和场景的一致性。
数据的构建采用多模态大语言模型初筛和人类专家手工标注相结合的混合方法。
OmniGen2依托智源研究院自研的大模型训练推理并行框架FlagScale,开展推理部署优化工作。
通过深度重构模型推理链路,并融合TeaCache缓存加速策略,实现32%的推理效率提升,大幅缩短响应时间并强化服务效能。同时,框架支持一键式跨机多实例弹性部署,有效提升集群资源整体利用率。
团队将持续推进软硬协同优化,构建高效推理部署能力体系。
OmniGen2的模型权重、训练代码及训练数据将全面开源,为开发者提供优化与扩展的新基础,推动统一图像生成模型从构想加速迈向现实。
文章来自于微信公众号“新智元”。


【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
