
狂拿大模型明星订单,一家清华系HPC-AI Infra公司浮出水面
狂拿大模型明星订单,一家清华系HPC-AI Infra公司浮出水面不靠囤算力,拿下数家大模型明星公司订单。
来自主题: AI资讯
9263 点击 2025-07-29 16:52
 搜索
搜索
不靠囤算力,拿下数家大模型明星公司订单。

2025年7月20日,2025基础科学与人工智能论坛在中关村展示中心会议中心举行。

WAIC大会上,这个机器人凭惊艳实力引起了层层围观!叠衣服、分拣物品、听指令取货,他们研发的Mech-GPT多模态大模型和「眼脑手」系统,让机器人的高难度操作性能暴增。现在,这家公司已经成为市占率连续五年的行业冠军了。

2017年6月,清华创投的活动室里,武彬第一次见到金沙江创投的合伙人朱啸虎。短暂交流十几分钟后,朱啸虎抛出一个让他愕然的提议:“我们投给你500万。”武彬当时25岁,正在清华大学人工智能实验室读研二,3个月前才注册了一家叫极睿科技的公司。公司没有产品,没有团队,没有商业闭环,只有大胆的构想:用AI变革整个服饰行业。

不要只盯着明星AI研究员!为了打造ASI,Meta、贝索斯等狂砸百亿,招聘专家当AI的「老师」。在此背景下,数据标注员的角色逐渐从基础任务转向更高技能的领域,门槛水涨船高。
就在刚刚,Meta 宣布,清华校友赵晟佳(Shengjia Zhao)将正式担任其超级智能实验室( MSL)首席科学家。

机器人能通过普通视频来学会实际物理操作了! 来看效果,对于所有没见过的物品,它能精准识别并按照指令完成动作。

如何理解大模型推理能力?现在有来自谷歌DeepMind推理负责人Denny Zhou的分享了。 就是那位和清华姚班马腾宇等人证明了只要思维链足够长,Transformer就能解决任何问题的Google Brain推理团队创建者。 Denny Zhou围绕大模型推理过程和方法,在斯坦福大学CS25上讲了一堂“LLM推理”课。
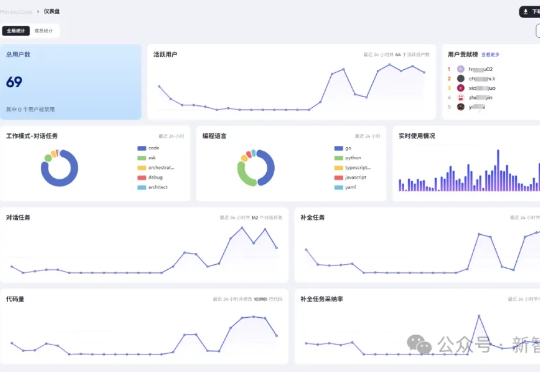
Cursor突然断供,码农AI Coding就像被砍掉了手脚!如今,清华系最强平替MonkeyCode站在了C位,不仅性能炸裂、成本超低,还能应对复杂编程任务,首发支持Kimi K2和Qwen3。
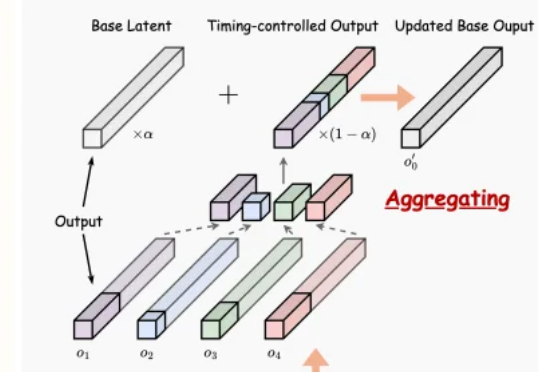
文生音频系统最新突破,实现精确时间控制与90秒长时音频生成!