
对话2004年生世界模型创业者陈博远:我不是天才|新皮层
对话2004年生世界模型创业者陈博远:我不是天才|新皮层Yann LeCun的JEPA架构很可能不会work,但至少证明了隐空间比像素或文本空间具备更强的泛化能力;
来自主题: AI资讯
9038 点击 2026-07-01 15:39
 搜索
搜索
Yann LeCun的JEPA架构很可能不会work,但至少证明了隐空间比像素或文本空间具备更强的泛化能力;
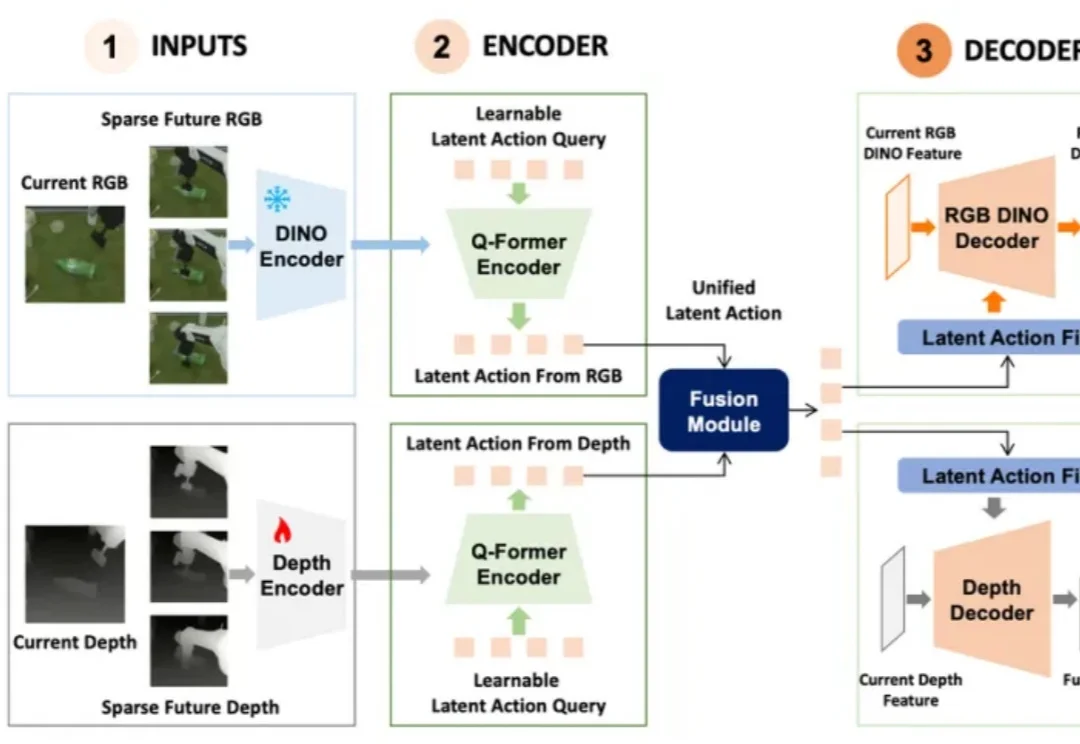
当前,物理 AI 正面临着关于泛化能力的普遍质疑。当模型缺乏对真实物理规律的深度认知、难以跨越复杂多变的开放场景时,如何让机器人真正理解物理世界并精准规划决策,已成为具身智能破局的关键。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

具身智能正以前所未有的速度发展,VLA 模型展现出越来越强的动作和泛化能力。然而,当我们真正把 VLA 模型部署到物理世界时,一个核心挑战浮出水面:实时性。
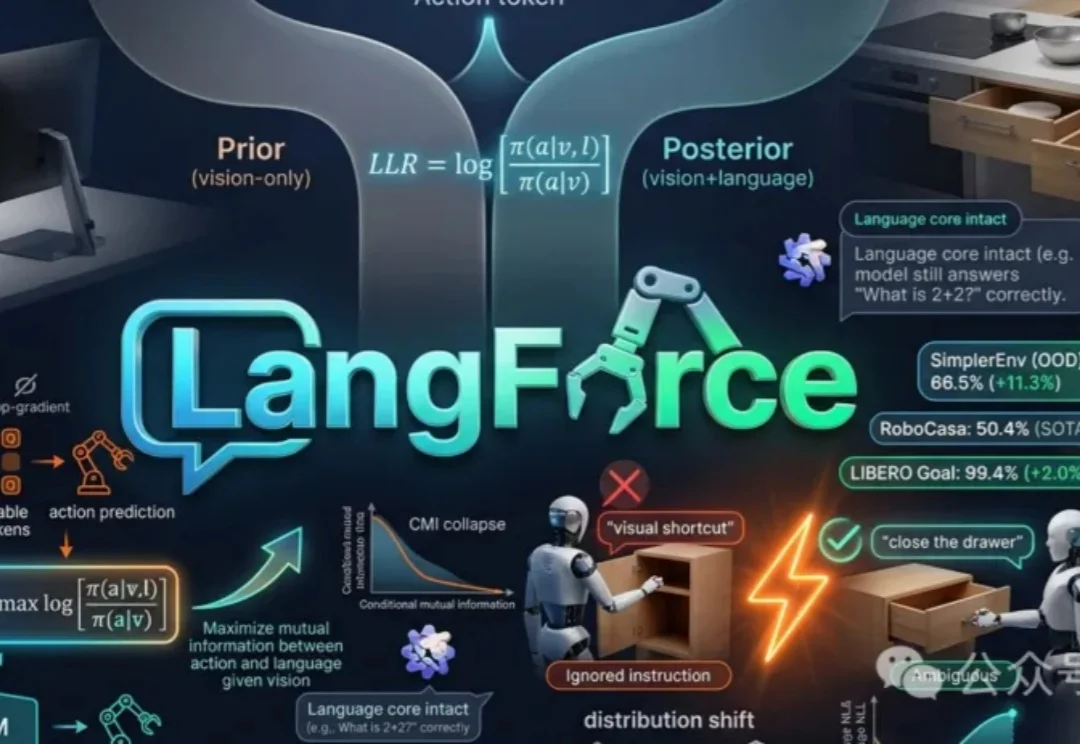
当前VLA模型常依赖视觉线索而非语言指令,导致在新场景下表现不佳。论文提出LangForce方法,通过引入对数似然比损失,强化模型对语言的依赖,提升其在分布外环境中的泛化能力,并保留语言核心功能。

研究者用特制雨伞干扰无人机视觉系统,让其误判目标在远去,从而失控俯冲。FlyTrap攻击无需信号干扰,仅靠物理图案就能欺骗多款商用无人机,实现静默捕获或击毁。实验显示,物理闭环攻击成功率超60%,且对新人物、新场景均有强泛化能力。这项研究揭示了AI感知系统的重大安全隐患,警示我们:视觉安全正成为智能设备的阿喀琉斯之踵。
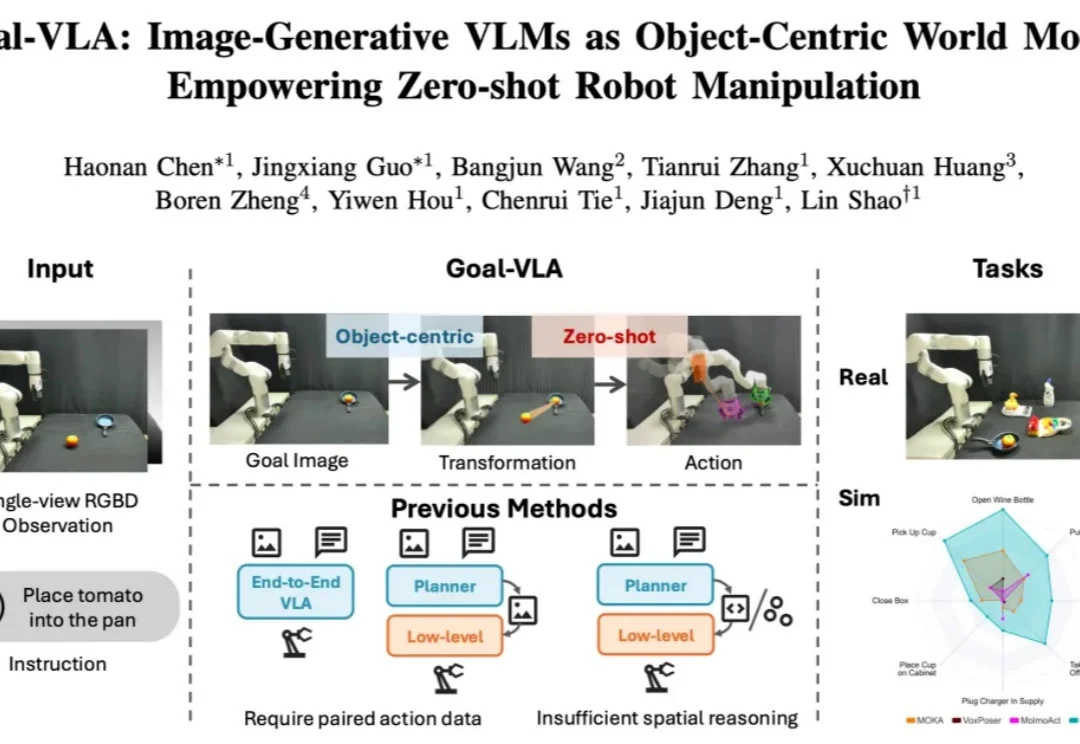
在具身智能领域,机器人操作的泛化能力一直是一个核心挑战。当前,视觉 - 语言 - 动作(VLA)模型主要分为两大范式:端到端模型与分层模型。端到端 VLA 模型(如 RT-2 [1], OpenVLA [2])严重依赖海量的 “指令 - 视觉 - 动作” 成对数据,获取成本极高,导致其在面对新任务或新场景时零样本泛化能力受限。

在大模型后训练阶段,监督微调(SFT)和强化学习(RL)是两根不可或缺的支柱。SFT 利用高质量的离线(Off-policy)数据快速注入知识,但受限于静态数据分布,泛化能力往往容易触及天花板并带来灾难性遗忘;RL 则允许模型在探索中不断自我迭代,产生与当前策略同分布(On-policy)的数据,上限极高,但往往伴随着训练极度不稳定、计算资源消耗巨大的痛点。
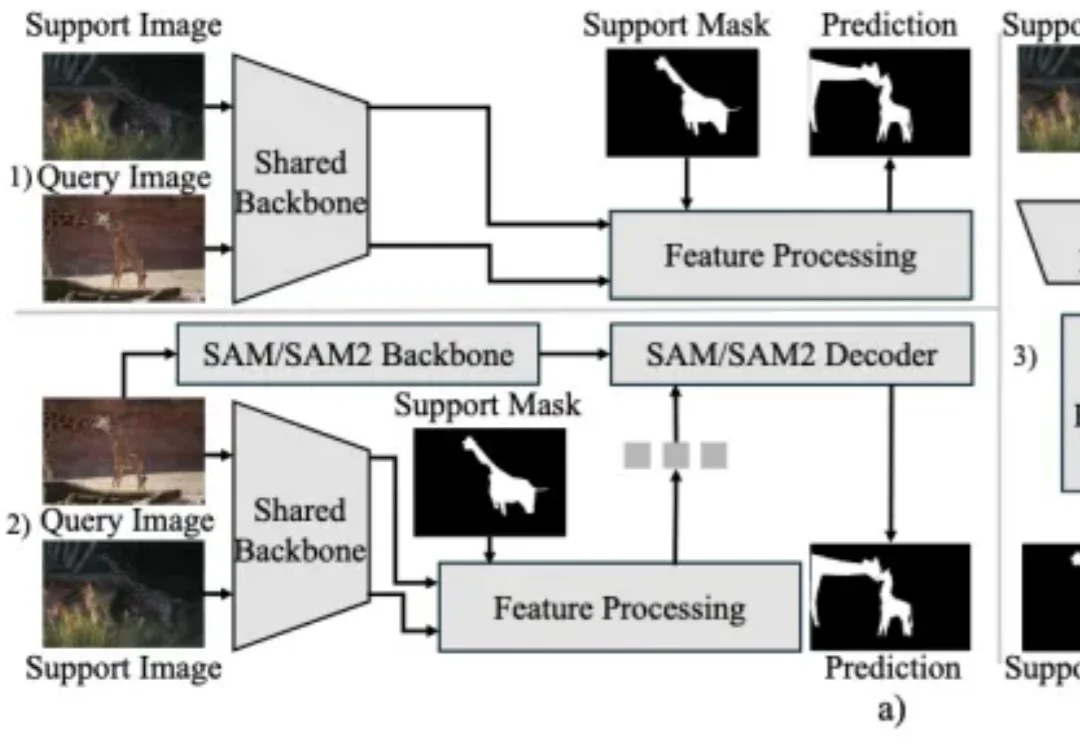
上下文分割(In-Context Segmentation)旨在通过参考示例指导模型实现对特定目标的自动化分割。尽管 SAM 凭借卓越的零样本泛化能力为此提供了强大的基础,但将其应用于此仍受限于提示(如点或框)构建,这样的需求不仅制约了批量推理的自动化效率,更使得模型在处理复杂的连续视频时,难以维持时空一致性。

北航刘偲教授团队提出首个大规模真实星座调度基准AEOS-Bench,更创新性地将Transformer模型的泛化能力与航天工程的专业需求深度融合,训练内嵌时间约束的调度模型AEOS-Former。这一组合为未来的“AI星座规划”奠定了新的技术基准。