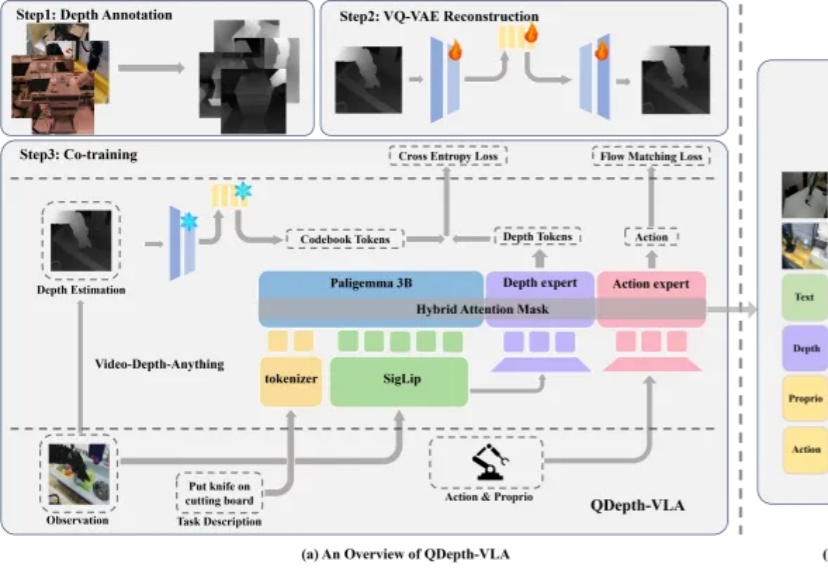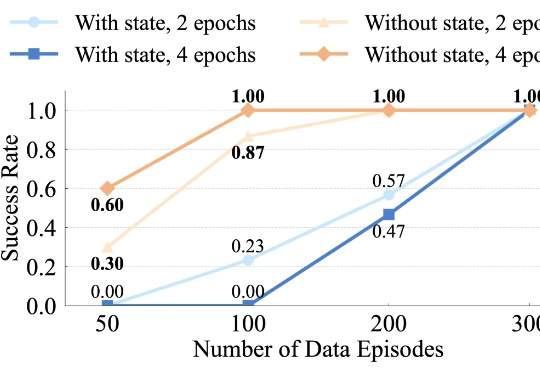
AIGC检测为何频频“看走眼”?腾讯优图揭秘:问题可能出在数据源头
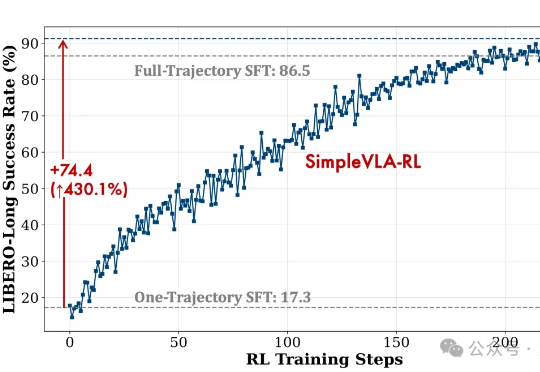
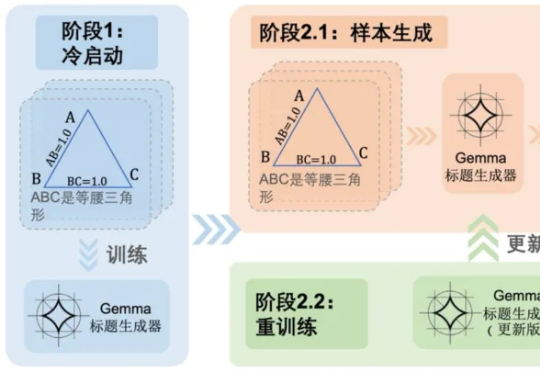
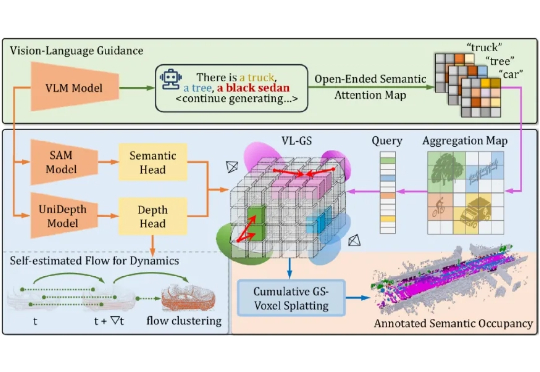
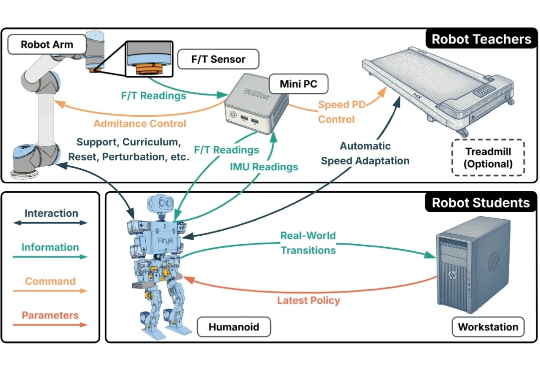
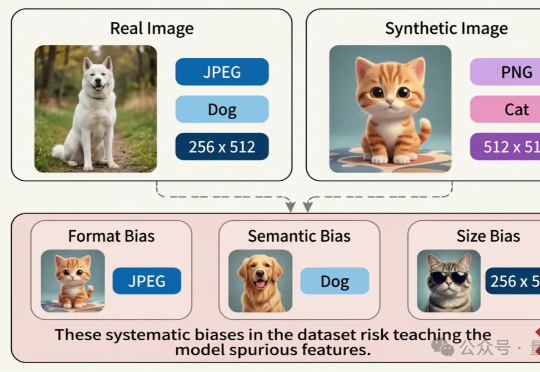
AIGC检测为何频频“看走眼”?腾讯优图揭秘:问题可能出在数据源头近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队在A生成图像检测(AI-Generated Image Detection)泛化问题上展开研究,提出Dual Data Alignment(双重数据对齐,DDA)方法,从数据层面系统性抑制“偏差特征”,显著提升检测器在跨模型、跨数据域场景下的泛化能力。
来自主题: AI技术研报
7698 点击 2025-11-30 15:10