
Anthropic封杀48小时,逼出OpenClaw最强反击!龙虾首次会生视频了
Anthropic封杀48小时,逼出OpenClaw最强反击!龙虾首次会生视频了太突然了!Anthropic深夜发布封杀令,切断OpenClaw免费接口。龙虾之父霸气回怼,直接上线2026.4.5王炸更新:AI原生支持视频生成,还装上了一套模拟人类的「睡眠记忆」系统。
来自主题: AI资讯
8165 点击 2026-04-07 15:23
 搜索
搜索
太突然了!Anthropic深夜发布封杀令,切断OpenClaw免费接口。龙虾之父霸气回怼,直接上线2026.4.5王炸更新:AI原生支持视频生成,还装上了一套模拟人类的「睡眠记忆」系统。
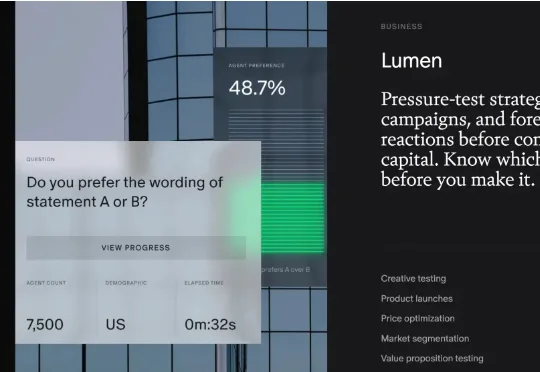
Aaru是一家2024年成立的美国AI智能体初创公司,其核心业务是通过整合人口统计与心理特征数据构建模型,生成精准用户画像,并利用数千个AI智能体模拟人类行为反应,目前已被应用于产品开发、定价策略、新客拓展以及政治民调等多个领域。

马斯克「Macrohard」(巨硬)黑幕曝光!xAI工程师爆料:AI智能体将8倍速模拟人类,或取代亿万白领岗位。

中山大学等机构推出SpatialDreamer,通过主动心理想象和空间推理,显著提升了复杂空间任务的性能。模拟人类主动探索、想象和推理的过程,解决了现有模型在视角变换等任务中的局限,为人工智能的空间智能发展开辟了新路径。
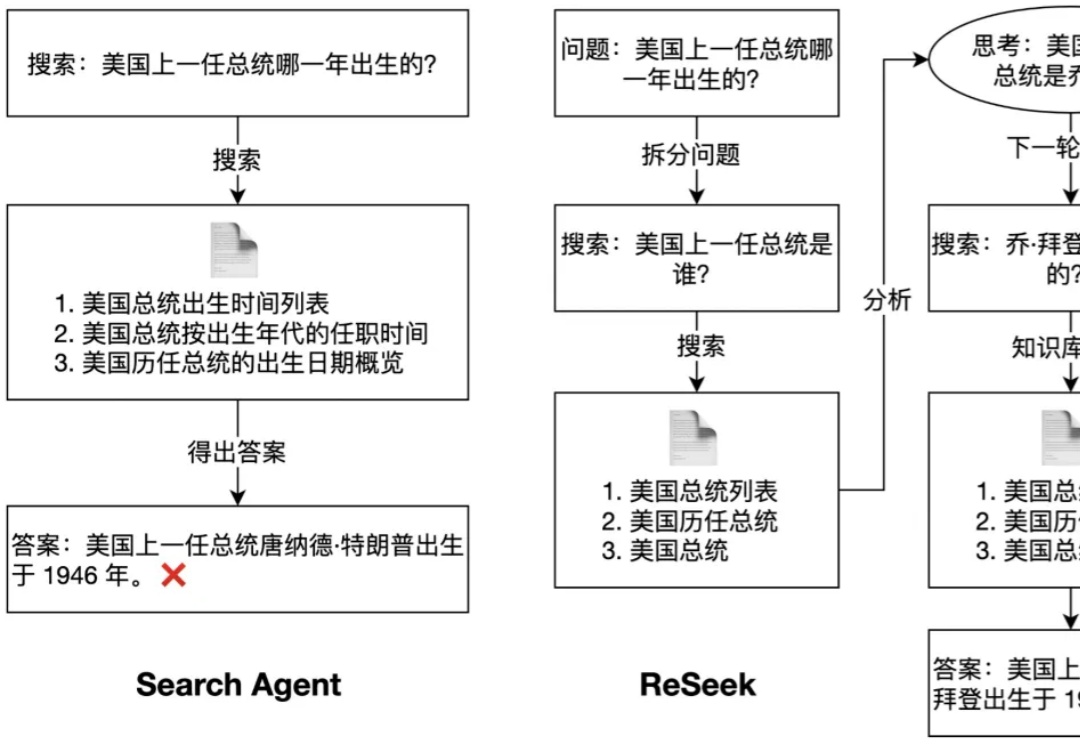
为了同时解决知识的实时性和推理的复杂性这两大挑战,搜索智能体(Search Agent)应运而生。它与 RAG 的核心区别在于,Search Agent 能够通过与实时搜索引擎进行多轮交互来分解并执行复杂任务。这种能力在人物画像构建,偏好搜索等任务中至关重要,因为它能模拟人类专家进行深度、实时的资料挖掘。

时隔两月,Baichuan-M2 Plus重磅出世!成为业内首个循证增强的医疗大模型,幻觉要比DeepSeek-R1低3倍,可信度比肩资深临床专家。新模型将「循证医学」理念深度融入训练和推理,通过首创「六源循证范式」,模拟人类医生思维,有效辨别不同层级医学证据、评估其可靠性,并在回答中优先引用高等级证据。
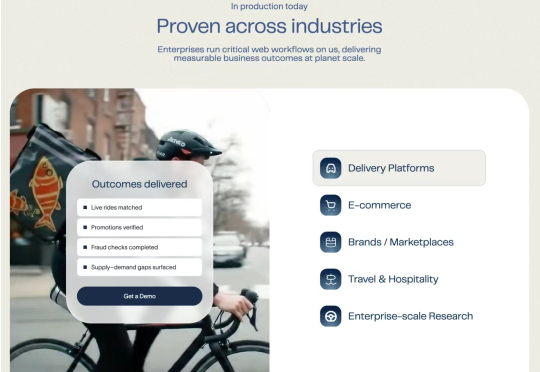
当我看到TinyFish刚刚完成4700万美元A轮融资的消息时,我意识到这不仅是一轮融资,而是一个全新时代的开始——企业级Web Agent时代。我一直在思考AI agent的商业化应用,但TinyFish的方法让我看到了一个更加现实且具有颠覆性的方向:让AI agent不是简单地模拟人类浏览网页,而是以企业级的规模、可靠性和合规性要求来执行复杂的业务工作流程。

当前最强大的大语言模型(LLM)虽然代码能力飞速发展,但在解决真实、复杂的机器学习工程(MLE)任务时,仍像是在进行一场“闭卷考试”。它们可以在单次尝试中生成代码,却无法模拟人类工程师那样,在反复的实验、调试、反馈和优化中寻找最优解的真实工作流。

7月2日,一个跨国团队在Nature杂志发表了一项开创性研究,宣称其推出的AI系统能够“模拟人类心智”。该系统在实验中可以“扮演”人类,生成逼真的人类行为。
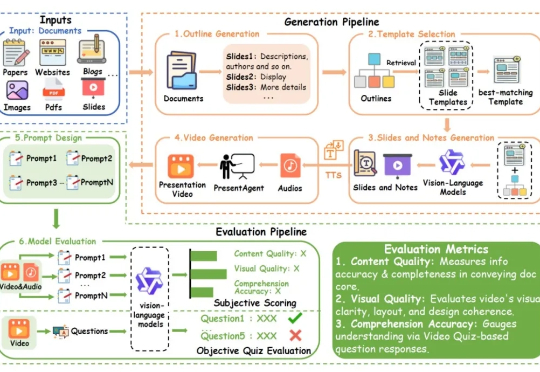
我们提出了 PresentAgent,一个能够将长篇文档转化为带解说的演示视频、多模态智能体。现有方法大多局限于生成静态幻灯片或文本摘要,而我们的方案突破了这些限制,能够生成高度同步的视觉内容和语音解说,逼真模拟人类风格的演示。