
模型小,还高效!港大最新推荐系统EasyRec:零样本文本推荐能力超越OpenAI、Bert
模型小,还高效!港大最新推荐系统EasyRec:零样本文本推荐能力超越OpenAI、BertEasyRec利用语言模型的语义理解能力和协同过滤技术,提升了在零样本学习场景下的推荐性能。通过整合用户和物品的文本描述,EasyRec能够生成高质量的语义嵌入,实现个性化且适应性强的推荐。
来自主题: AI技术研报
7327 点击 2024-08-28 15:21
 搜索
搜索
EasyRec利用语言模型的语义理解能力和协同过滤技术,提升了在零样本学习场景下的推荐性能。通过整合用户和物品的文本描述,EasyRec能够生成高质量的语义嵌入,实现个性化且适应性强的推荐。

来自复旦大学视觉与学习实验室的研究者们提出了一种新型的面向视频模型的对抗攻击方法 - 基于扩散模型的视频非限制迁移攻击(ReToMe-VA)。该方法采用逐时间步对抗隐变量优化策略,以实现生成对抗样本的空间不可感知性;同时,在生成对抗帧的去噪过程中引入了递归 token 合并策略,通过匹配及合并视频帧之间的自注意力 token,显著提升了对抗视频的迁移性和时序一致性。
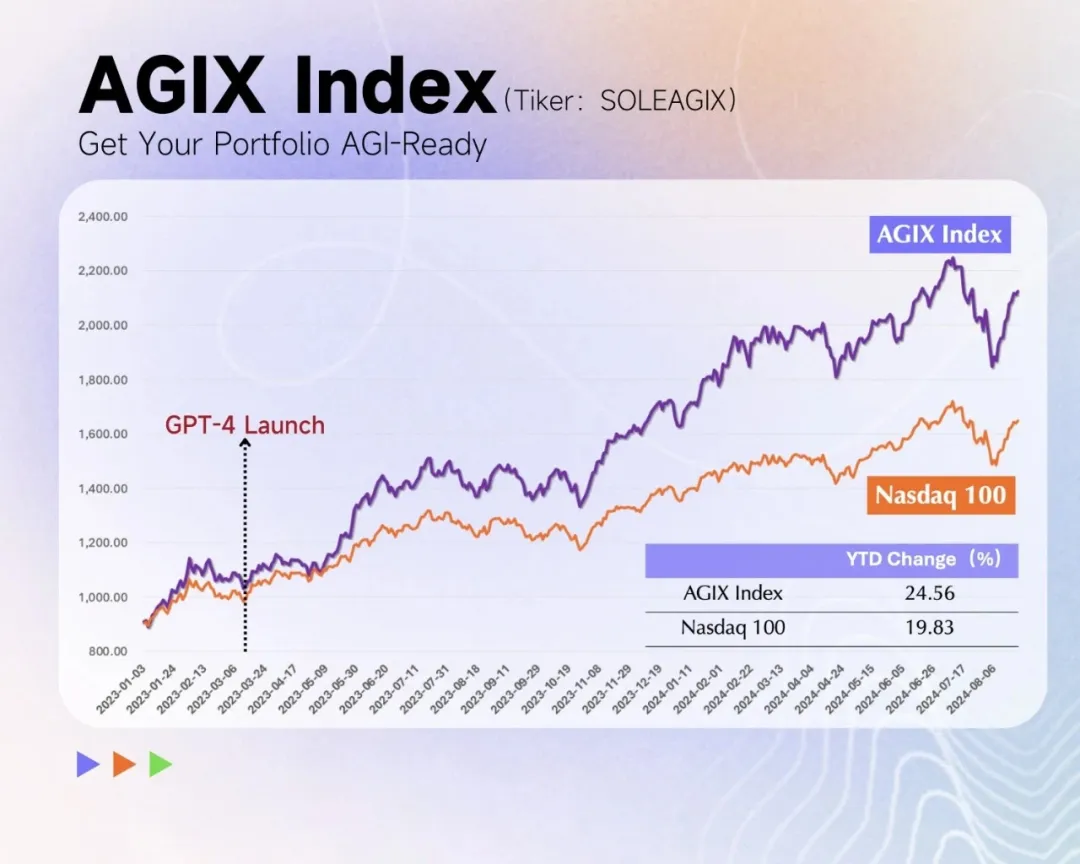
AGI 正在迎来新范式,RL 是 LLM 的秘密武器。

计算机是二进制的世界,所以浮点数也是用二进制来表示的,与整型不同的是,浮点数通过3个区间来表示:
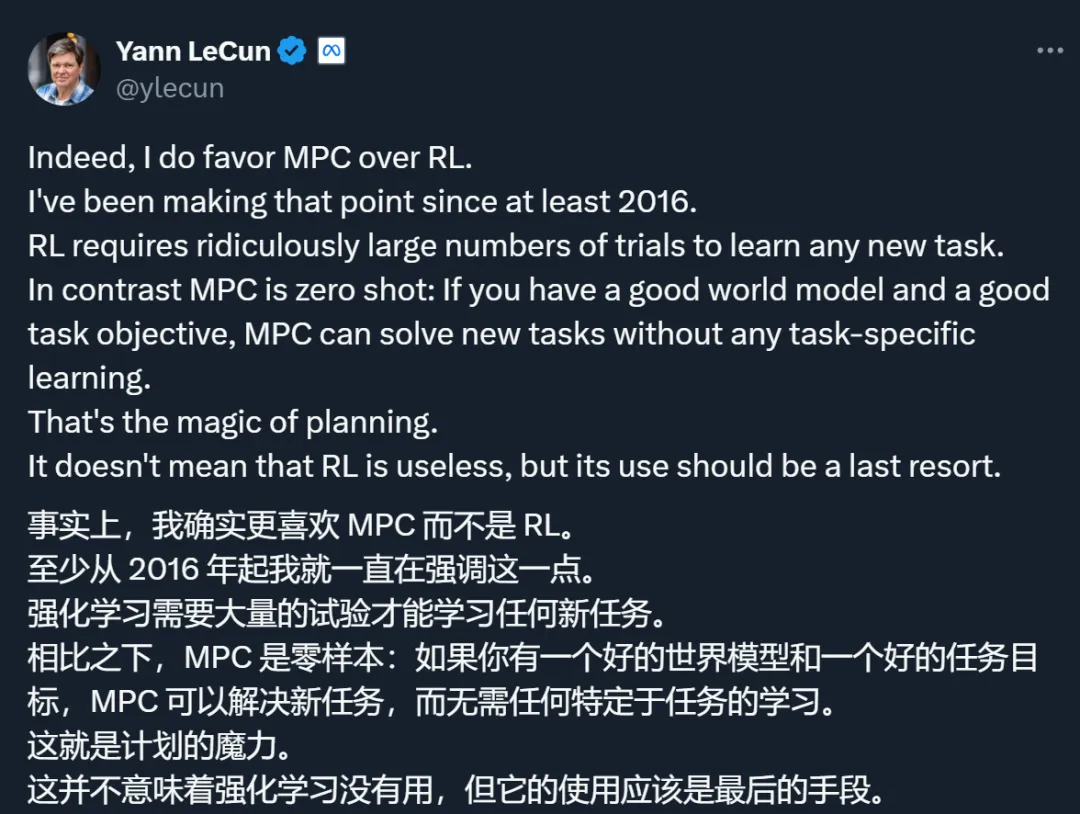
「相比于强化学习(RL),我确实更喜欢模型预测控制(MPC)。至少从 2016 年起,我就一直在强调这一点。强化学习在学习任何新任务时都需要进行极其大量的尝试。相比之下,模型预测控制是零样本的:如果你有一个良好的世界模型和一个良好的任务目标,模型预测控制就可以在不需要任何特定任务学习的情况下解决新任务。这就是规划的魔力。这并不意味着强化学习是无用的,但它的使用应该是最后的手段。」
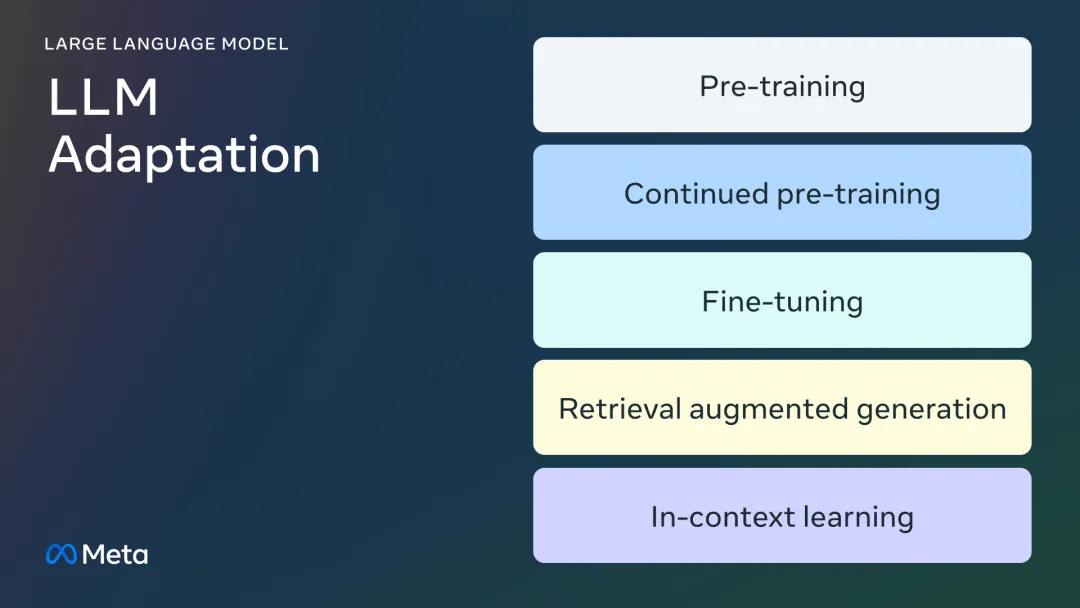
微调的所有门道,都在这里了。

随着LLM不断迭代,偏好和评估数据中大量的人工标注逐渐成为模型扩展的显著障碍之一。Meta FAIR的团队最近提出了一种使用迭代式方法「自学成才」的评估模型训练方法,让70B参数的Llama-3-Instruct模型分数超过了Llama 3.1-405B。

让AI绘画模型变“乖”,现在仅需3秒调整模型参数。

最近 ACL 2024 论文放榜,扫了下,SMoE(稀疏混合专家)的论文不算多,这里就仔细梳理一下,包括动机、方法、有趣的发现,方便大家不看论文也能了解的七七八八,剩下只需要感兴趣再看就好。

在人工智能领域,图像生成技术一直是一个备受关注的话题。近年来,扩散模型(Diffusion Model)在生成逼真且复杂的图像方面取得了令人瞩目的进展。然而,技术的发展也引发了潜在的安全隐患,比如生成有害内容和侵犯数据版权。这不仅可能对用户造成困扰,还可能涉及法律和伦理问题。