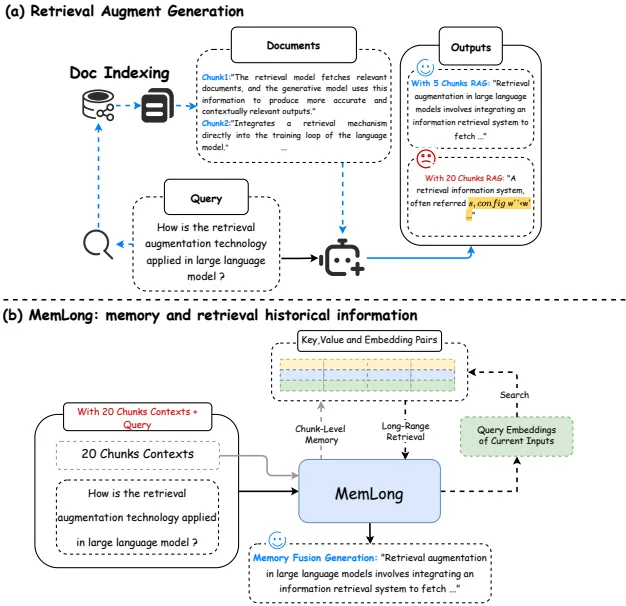
MemLong: 长文本的新记忆大师,可将上下文长度从4k提升到80k!
MemLong: 长文本的新记忆大师,可将上下文长度从4k提升到80k!这篇文章介绍了一个名为MemLong的模型,它通过使用外部检索器来增强长文本建模的能力。
来自主题: AI技术研报
8531 点击 2024-09-05 16:33
 搜索
搜索
这篇文章介绍了一个名为MemLong的模型,它通过使用外部检索器来增强长文本建模的能力。

近日,Mamba方面又搞出了有意思的研究:来自康奈尔、普林斯顿等机构的研究人员成功将Llama提炼成了Mamba模型,并且设计了新的推测解码算法,加速了模型的推理。

训练数据的质量优劣,直接影响人工智能(AI)大模型的能力水平。

近年来,大模型在人工智能领域掀起了一场革命,各种文本、图像、多模态大模型层出不穷,已经深深地改变了人们的工作和生活方式。

论文的审稿模式想必大家都不会陌生,一篇论文除了分配多个评审,最后还将由PC综合评估各位审稿人的reviews撰写meta-review。

说好的AI给人类打工呢? 为了拿到新数据、训练AI大模型,字节等互联网大厂正在亲自下场,以单次300元不等的价格招募“AI录音员”,定制语料库。
ChatGPT的出现引发了一场AI革命,它展示了通过简单对话就能完成各种任务的强大能力,并且将不同的 AI 功能整合到一个统一的平台上。还记得小编第一次使用 ChatGPT 的时候给我带来极大震撼。

中国首个拥有真正意义多任务连续泛化具身模型的机器人,诞生了!这个机器人,是真正由模型训练出来的,据了解,截止目前除了Figure 01,国内似乎还没有第二家能做到这种级别的泛化能力,即使被百般刁难,都能完成任务。清华校友下场创业,才4个月就已融资近2亿。

单元测试是软件开发流程中的一个关键环节,主要用于验证软件中的最小可测试单元,函数或模块是否按预期工作。单元测试的目标是确保每个独立的代码片段都能正确执行其功能,对于提高软件质量和开发效率具有重要意义。
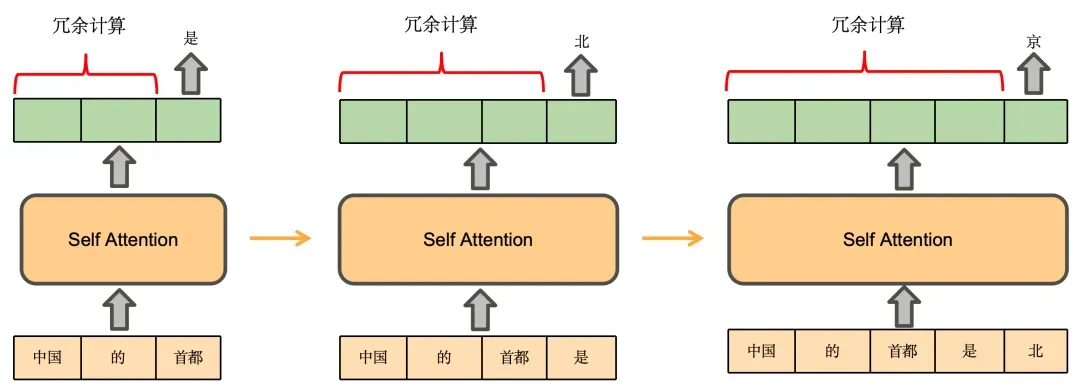
KV Cache 是大模型推理性能优化的一个常用技术,该技术可以在不影响任何计算精度的前提下,通过空间换时间的思想,提高推理性能。