
科研数据不再碎片化!一张可计算图,连起整个科研世界
科研数据不再碎片化!一张可计算图,连起整个科研世界UIUC研究团队打造ResearchArcade,将ArXiv论文、OpenReview评审、图表代码等碎片数据连接成动态知识图谱。模型可直接学习引用关系、修改轨迹与审稿互动,让AI更好辅助科研写作、修订与预测,为下一代科研智能体奠定统一数据基础。
来自主题: AI技术研报
7992 点击 2026-03-24 16:30
 搜索
搜索
UIUC研究团队打造ResearchArcade,将ArXiv论文、OpenReview评审、图表代码等碎片数据连接成动态知识图谱。模型可直接学习引用关系、修改轨迹与审稿互动,让AI更好辅助科研写作、修订与预测,为下一代科研智能体奠定统一数据基础。
在自动驾驶、具身智能、AR/VR应用中做3D重建,大家都想解决一个终极问题: 模型能不能像人一样,一边往前看,一边持续构建三维世界?

近年来,随着 Sora、Seedance 等文本到视频(T2V)扩散模型的飞速发展,AI 视频生成在视觉保真度与动态表现上已取得突破性进展。特别是近期备受瞩目的 Seedance 2.0,展现出了极其强大的多镜头叙事与复杂分镜控制能力。

您用OpenClaw或CC时有没有这样的感受?Skill越装越多,Agent解决问题的能力却没有越变越强。
AI最强幻觉,原来不是不会,而是太会「装会」。 「你是专家」这句咒语,可能骗了整个AI圈一年。
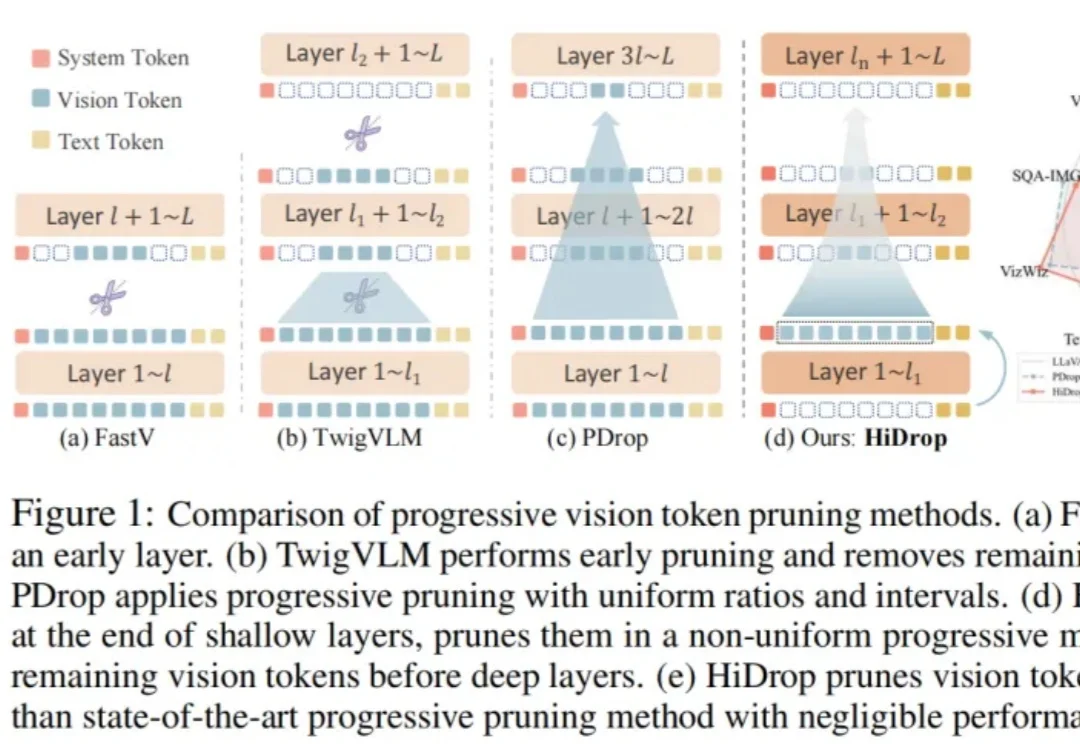
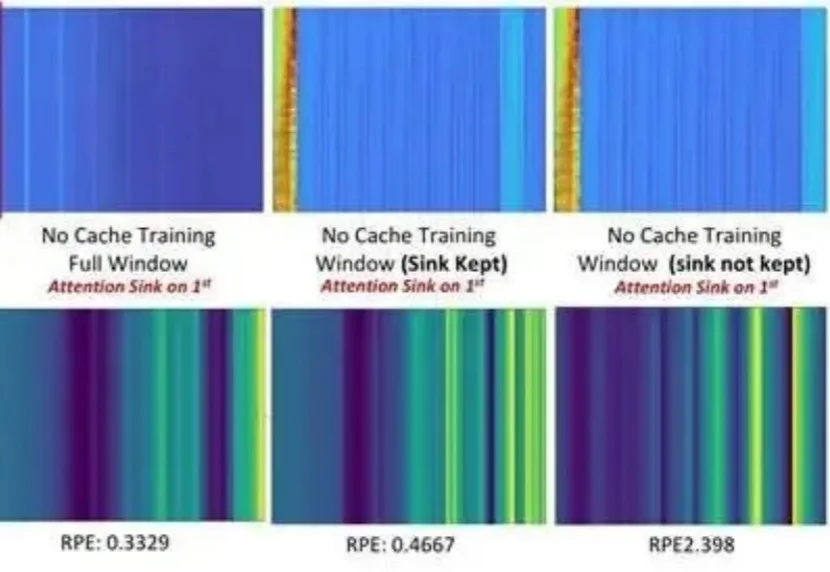
随着多模态大语言模型(MLLM)支持更长上下文,高分辨率图像和长视频会产生远多于文本的视觉 Token,在自注意力二次复杂度下迅速成为效率瓶颈。
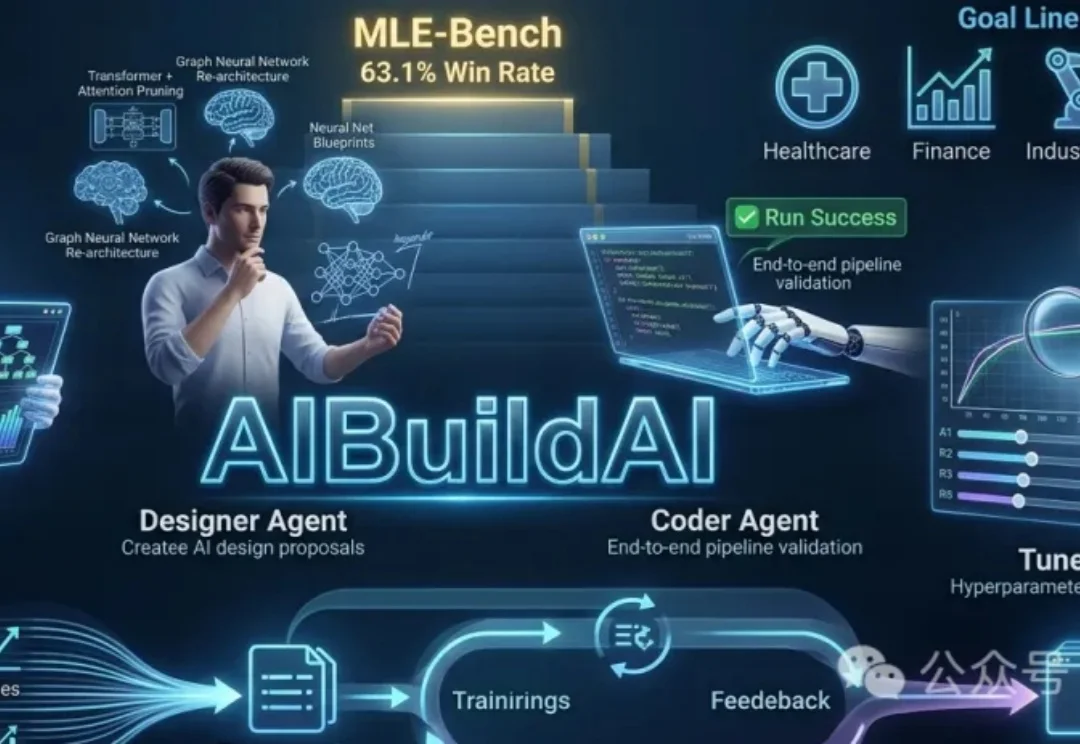
UCSD团队推出AIBuildAI智能体,无需编程,仅用自然语言描述任务,即可自动设计、编码、训练、调参并优化AI模型,分工协作,端到端完成AI开发。在OpenAI MLE-Bench测试中,AIBuildAI以63.1%的获奖率位居第一,性能媲美人类专家,推动AI开发迈向全自动化新时代。
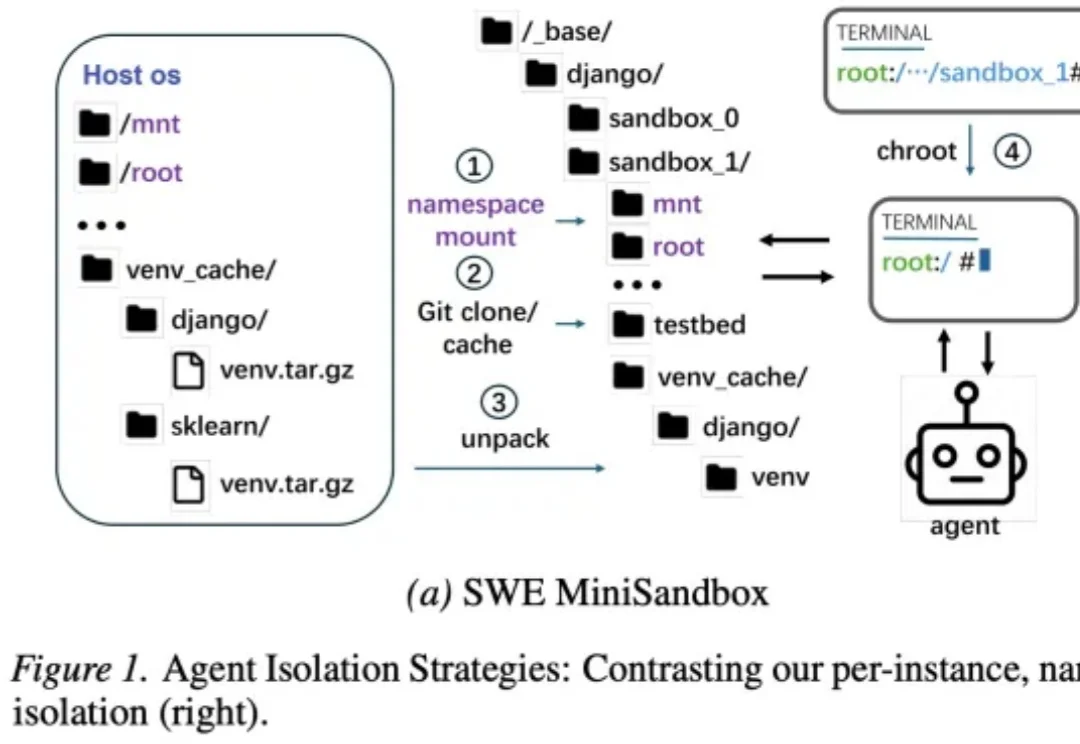
AI 编程这么火,想训练个 SWE Agent 却没有资源怎么办?
AI 驱动的自动化科研正从概念走向真实系统。近期受到广泛关注的 FARS,以及 Karpathy 开源的 autoresearch,都在不同程度上展示了 AI Scientist 自动进行 AI 领域研究的可行性。

在 AIGC 领域,基于参考图像的图像修复(Reference-based Inpainting)一直是一项备受关注的核心任务,它旨在利用参考图像引导修复过程,生成视觉一致的内容。这一技术在广告营销和电商领域有着巨大的应用潜力,例如让 AI 自动生成 “真人手持或穿戴商品” 的展示图。