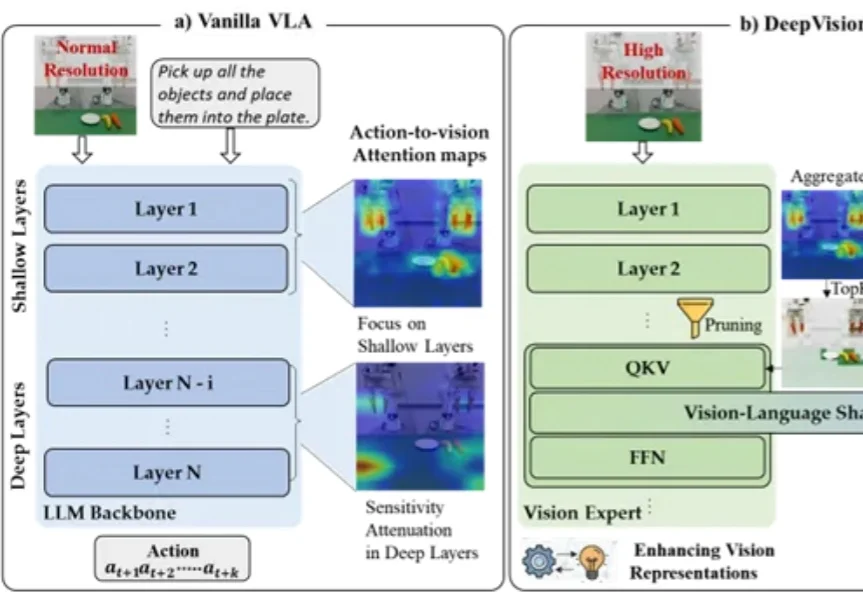
VLA别再「走神」:即插即用提升视觉泛化,相对Pi0.5提升18%
VLA别再「走神」:即插即用提升视觉泛化,相对Pi0.5提升18%“把水果放进盘子里”——机器人看懂了指令,开始执行,却在最后关头抓偏了。
来自主题: AI技术研报
6217 点击 2026-03-26 10:48
 搜索
搜索
“把水果放进盘子里”——机器人看懂了指令,开始执行,却在最后关头抓偏了。

在大模型后训练阶段,监督微调(SFT)和强化学习(RL)是两根不可或缺的支柱。SFT 利用高质量的离线(Off-policy)数据快速注入知识,但受限于静态数据分布,泛化能力往往容易触及天花板并带来灾难性遗忘;RL 则允许模型在探索中不断自我迭代,产生与当前策略同分布(On-policy)的数据,上限极高,但往往伴随着训练极度不稳定、计算资源消耗巨大的痛点。
大模型开发者常面临一个两难选择:要速度,还是省显存?

到2025年末,AI编程已经全面从辅助工具Copilot,转向以AI为主、人类监督的Agent时代。
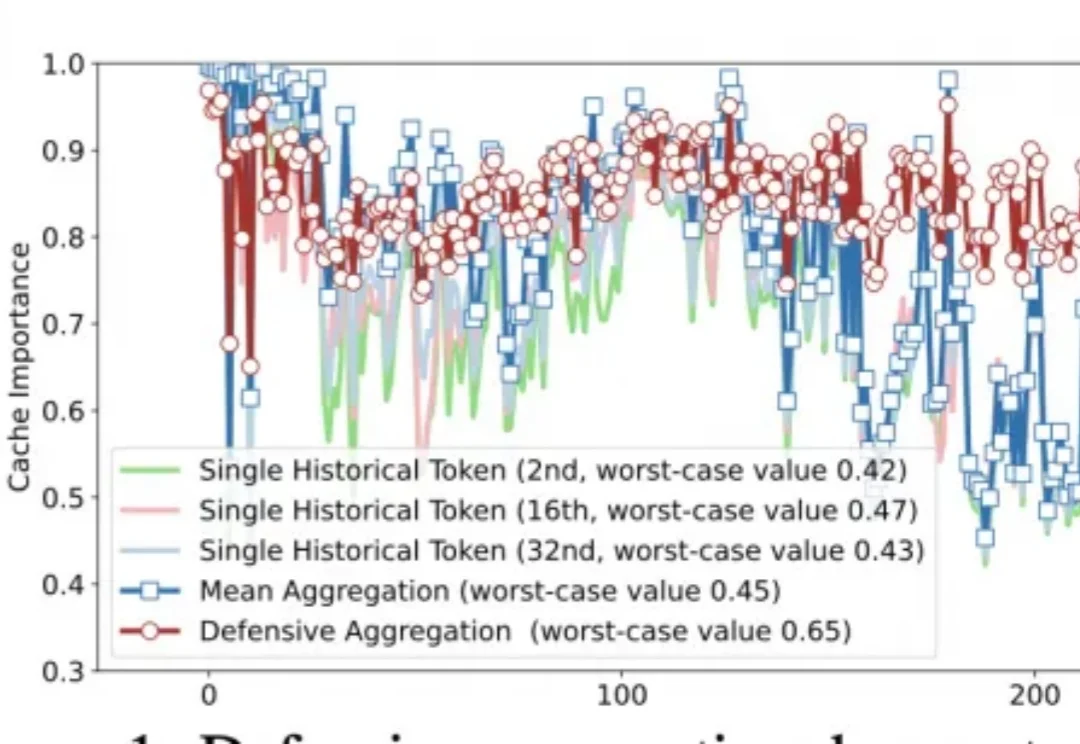
随着大模型长上下文能力快速增长,海量 KV Cache 存储需求急剧增加,各类 KV Cache 压缩方法如雨后春笋般涌现。然而,这些方案在真实场景中的工程落地却常常陷入困境。

近期,围绕「世界模型」这一方向,有两项工作受到较多关注。

OpenClaw 的爆火,不只是因为它能替你干活。
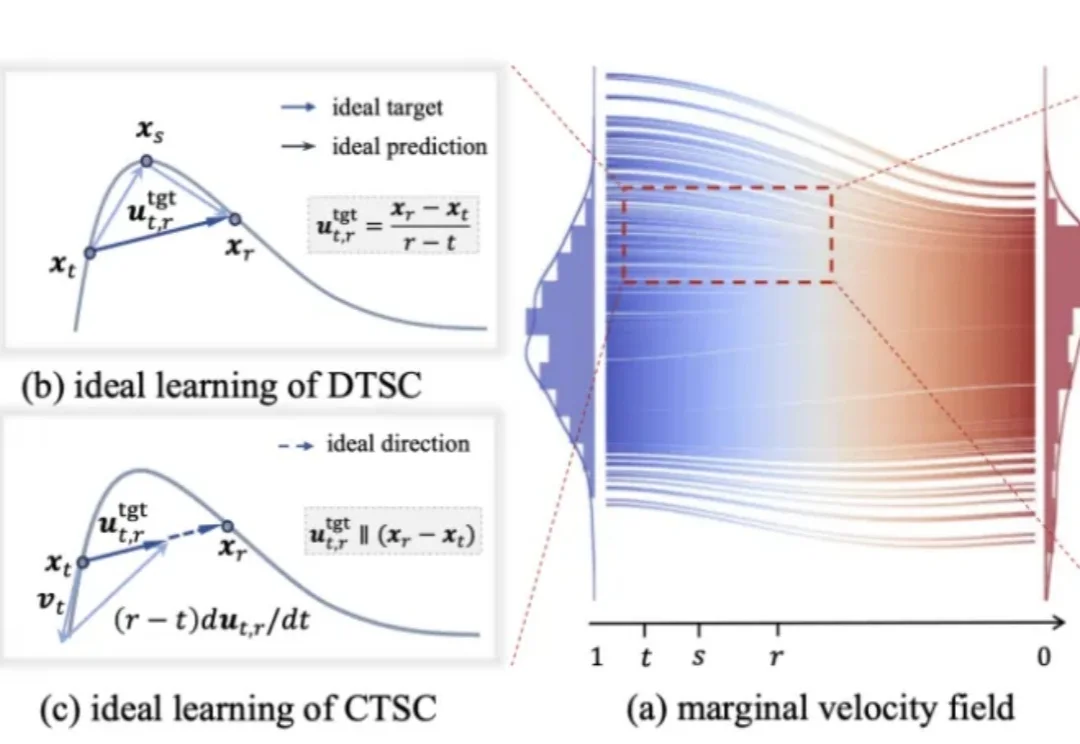
近期,基于捷径化概率流路径(shortcut probability flow trajectory)并从头训练的一步扩散生成模型,展现出强大的实证有效性。然而,这类方法的提出通常建立在较为复杂的理论推导之上,并且往往与具体实现细节高度耦合。这带来一个直接的问题:究竟哪些设计是方法成立的本质要素,哪些又只是可以灵活替换的实现组件。
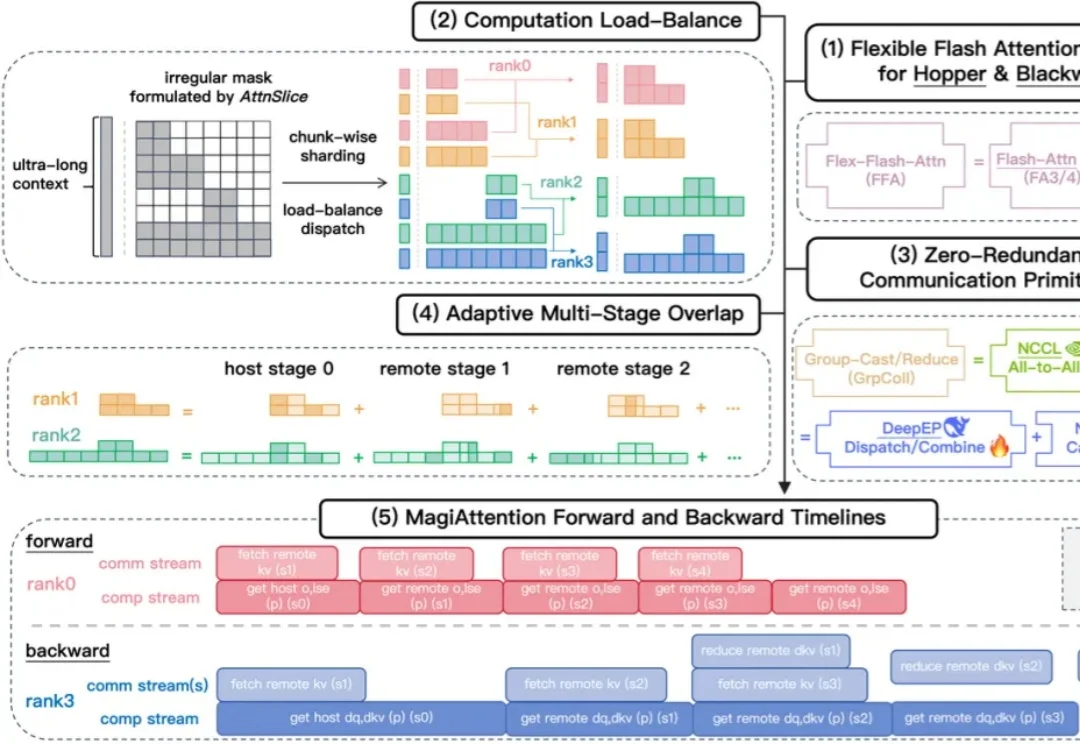
2025 年 4 月,Sand.ai 开源了 MagiAttention v1.0.0,定义了下一代分布式 Attention 的全新设计和系统框架。历经一年的深耕,今天 Sand.ai 正式发布:MagiAttention v1.1.0,以更成熟的原生算子组件,重新定义 Hopper 与 Blackwell 两代架构分布式 Attention 的性能上限。

我们在很多地方都看到了一个词,叫「压缩即智能」