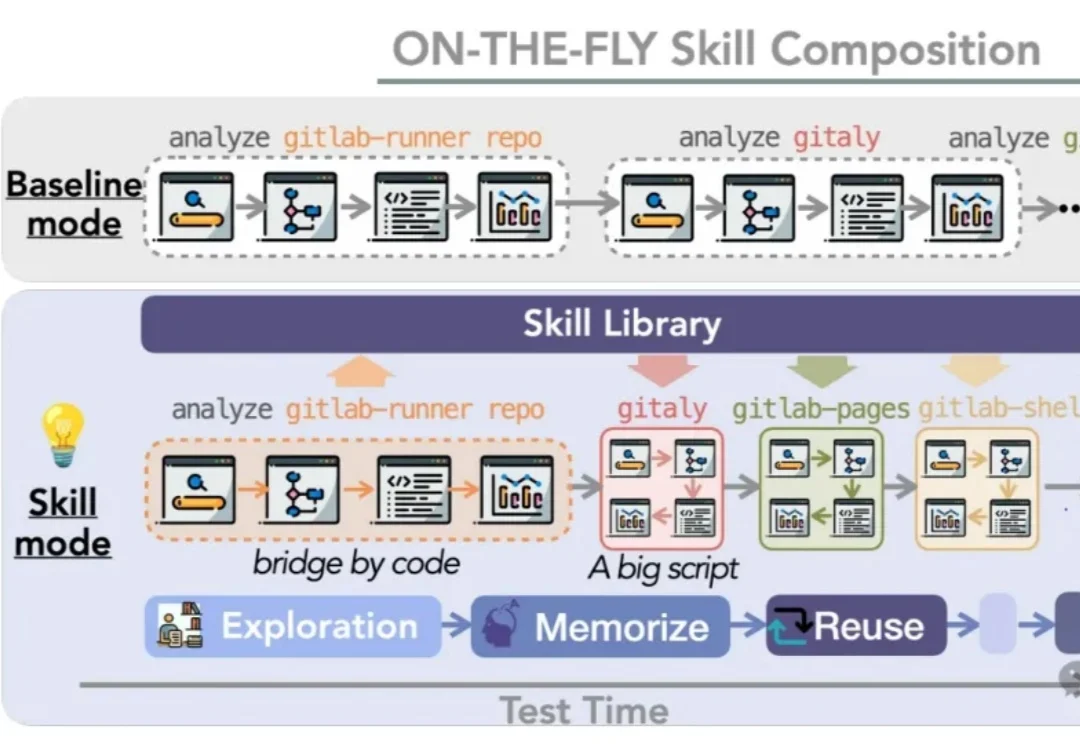
让Agent把成功经验固化成skills,跨模型复用成功率100%
让Agent把成功经验固化成skills,跨模型复用成功率100%AI会用工具了,问题才真正开始…
来自主题: AI技术研报
8448 点击 2026-04-02 09:39
 搜索
搜索
AI会用工具了,问题才真正开始…

在构建多Agent系统(Multi-Agent Systems)时,让几个Agent互相“对话”并不难,但要让它们在局部状态不一致的情况下,敲定一个全局唯一的决策,也就是达成“一致”(Agree)或“共识(Consensus)”,却是一个极具挑战的工程难题,您可能会问为什么,这有何难?
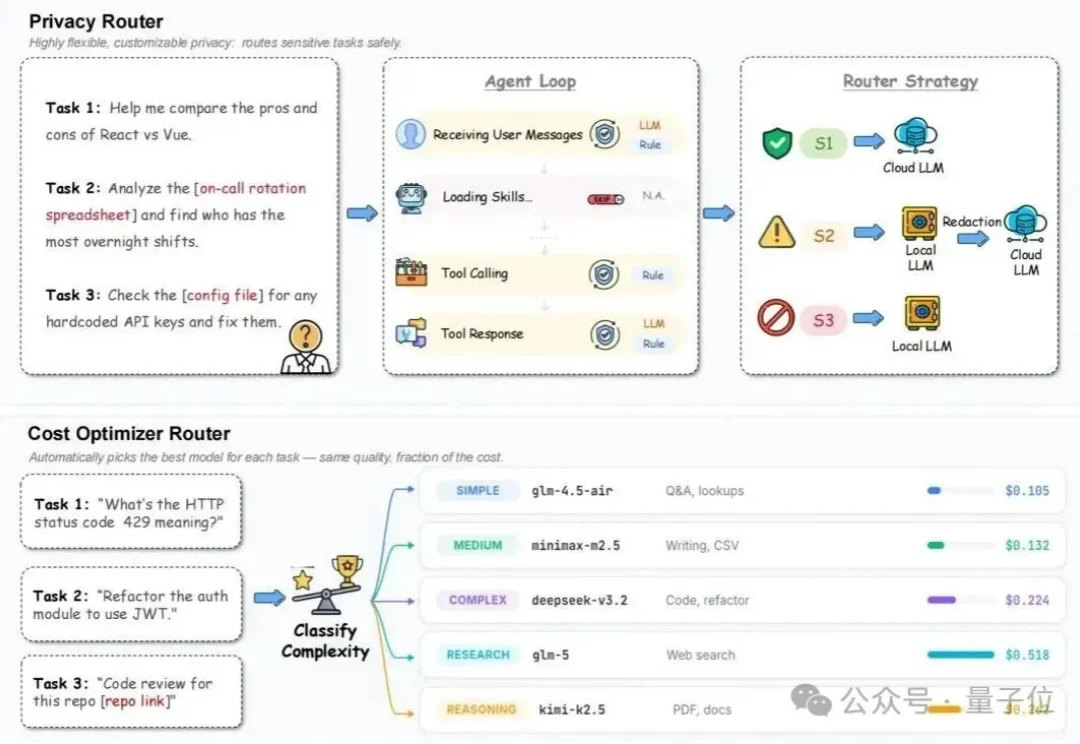
把Agent接入工作流,本该是件提效的乐事。
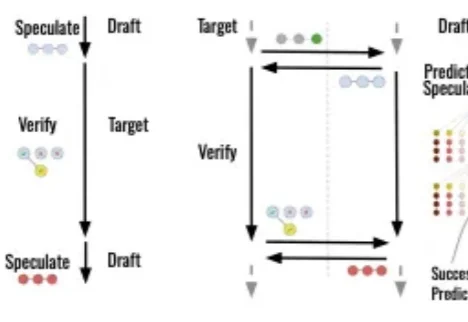
在大语言模型推理领域,虽然「推测解码」(Speculative Decoding,SD)已成为加速生成的标准配置,但它依然存在一个致命弱点: drafting(草拟)和 verification(验证)之间必须串行进行。
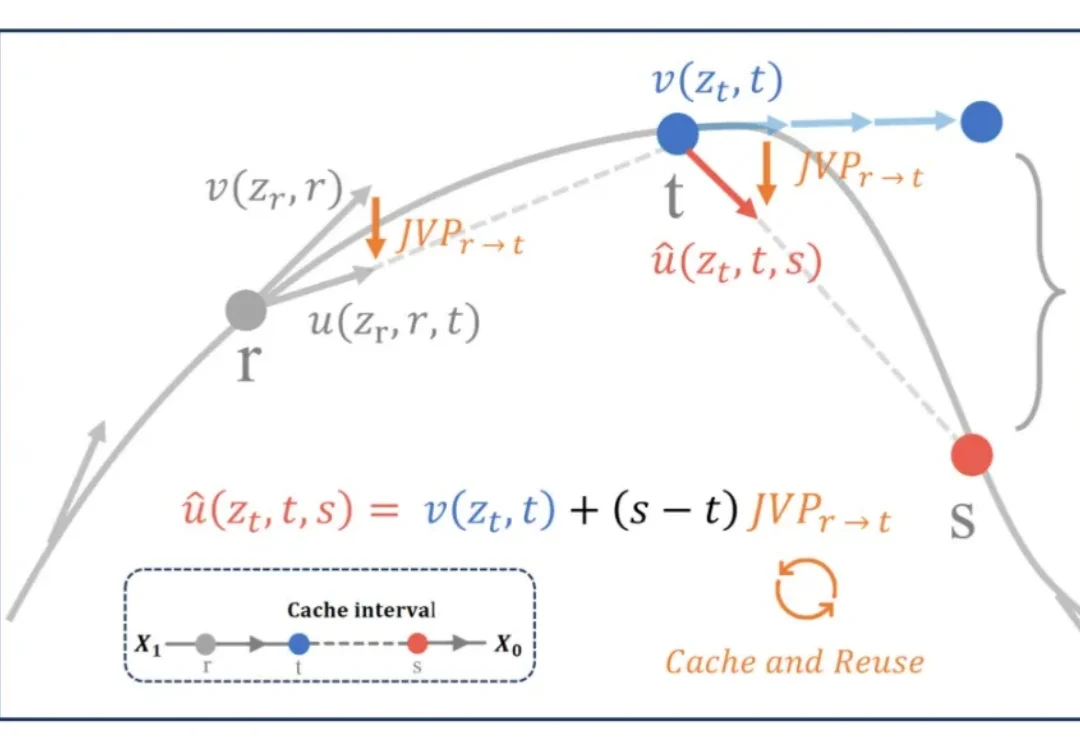
FLUX 、Qwen-Image 等多模态生成模型的推理速度一直是工业级多模态模型落地的痛点。传统的特征缓存(Feature Caching)方案在追求高倍率加速时,常因瞬时速度的剧烈波动导致轨迹漂移。
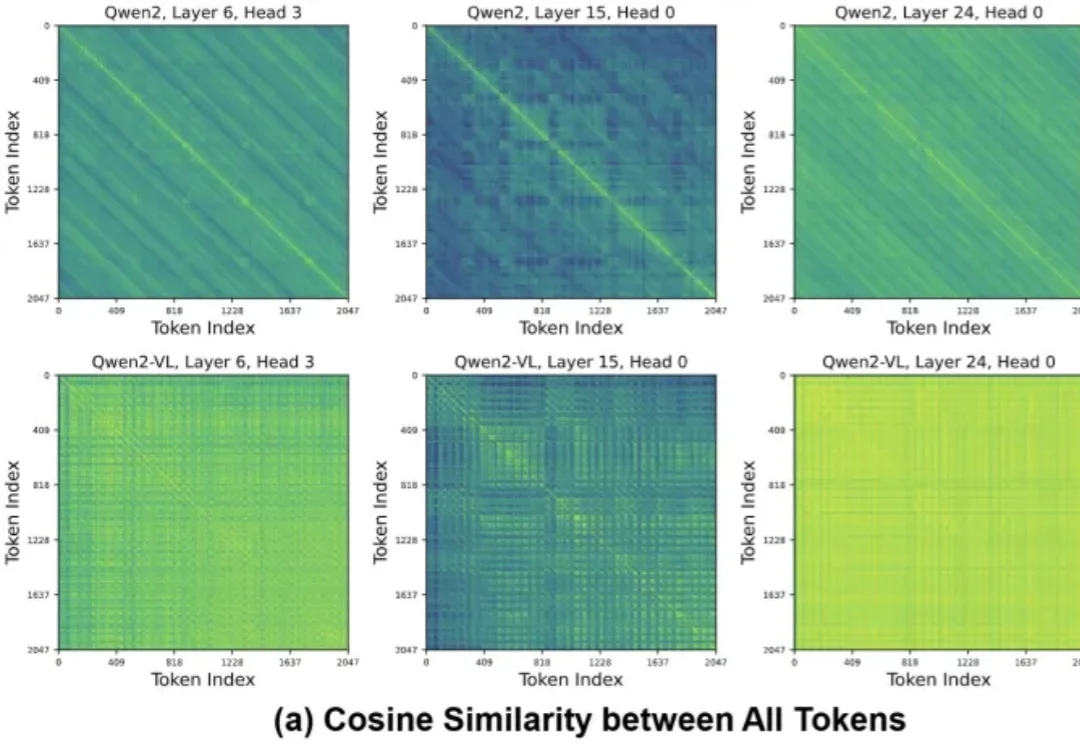
长上下文推理已经成了VLM/LLM的默认形态。

3 月 16 日,在刚刚结束的 NVIDIA GTC 2026 大会上,黄仁勋在长达三小时的 Keynote 演讲中发布了 NVIDIA Agent Toolkit 和 AI-Q 开放智能体蓝图,将 AI Agent 定位为下一个重大前沿。

过去数月,AI 领域很难绕开一个名字 ——OpenClaw。这个项目在极短时间内获得了爆发式关注:数十万星标、惊人的 Token 消耗,以及几乎所有大厂的快速跟进。从表面上看,它像是又一个现象级 AI 产品;但如果进一步审视,一个更值得思考的问题随之浮现 ——OpenClaw 的出现,究竟意味着什么?它真的是一次技术突破,还是某种更深层变化的信号?

全球首个1毫秒级人体动作捕捉系统FlashCap,通过闪烁LED与事件相机结合,实现1000Hz超高帧率捕捉。无需昂贵设备或强光环境,低成本穿戴服即可精准捕捉极速动作。团队同步开源715万帧的FlashMotion数据集与多模态模型ResPose,显著提升运动分析精度,推动体育、VR与机器人领域迈向高动态智能新阶段。

什么在限制空间智能落地?