
USC团队发布HumDex:攻克人形机器人数据瓶颈,低成本实现全身灵巧操控
USC团队发布HumDex:攻克人形机器人数据瓶颈,低成本实现全身灵巧操控人形机器人全身灵巧操作是通向通用具身智能的核心目标之一。在这一愿景下,机器人不仅需要双臂与高自由度多指灵巧手的精细协调,还需要与全身位姿(如行走、弯腰)进行动态配合。
来自主题: AI技术研报
5528 点击 2026-04-07 09:26
 搜索
搜索
人形机器人全身灵巧操作是通向通用具身智能的核心目标之一。在这一愿景下,机器人不仅需要双臂与高自由度多指灵巧手的精细协调,还需要与全身位姿(如行走、弯腰)进行动态配合。

AI不再只是把两个物体「放一起」,而是真正造出一个新实体。VMDiff模型通过分阶段策略:先拼接保留信息,再插值融合成整体,并自动调节平衡,让生成结果既像两者,又自然统一。 过去,很多图像生成模型都能同时画出两个物体;但要让它们真正「长成一个新物体」,其实远没有那么简单。
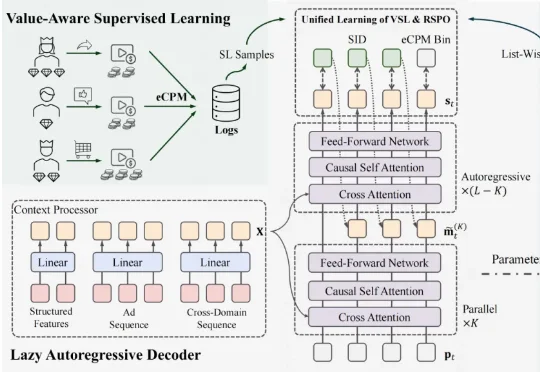
快手的这篇论文,正是对这一问题交出的一份沉甸甸的工业级答卷。他们提出了 GR4AD(Generative Recommendation for ADvertising),一个横跨表征、学习、服务三大层面协同设计的生成式广告推荐系统,并已全量部署于快手广告平台,服务超过 4 亿用户。
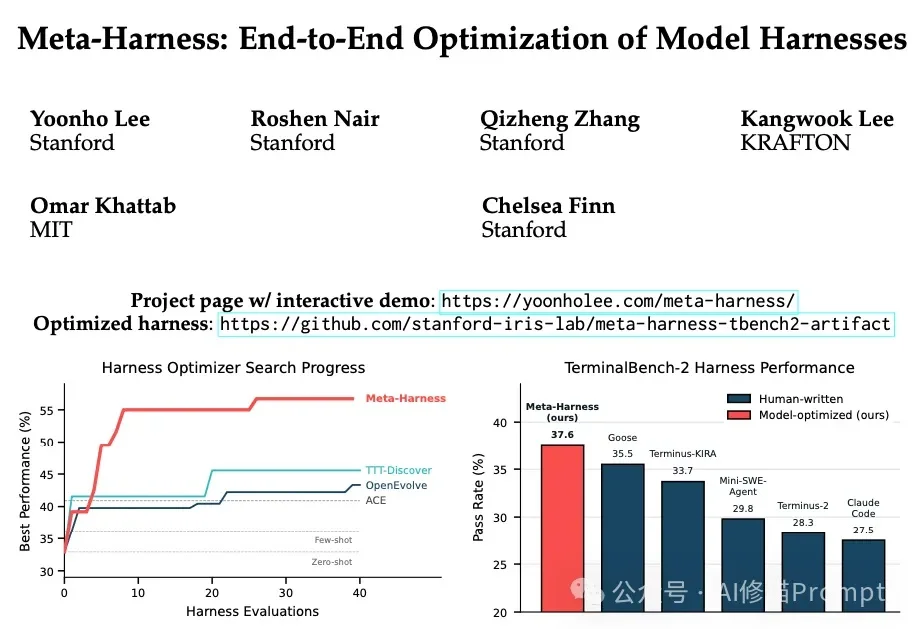
去年讨论Agent落地时,重点往往是Context Engineering。大家都在琢磨怎么放 Few-shot,怎么优化 RAG 检索的文本片段。但随着 Agent 任务复杂度的上升,控制数据流向、工具调度和异常处理的底层脚手架代码,往往比单纯拼接文本对系统性能的影响更大。

3 月 31 日下午,技术圈炸了锅: Claude Code,这款被公认为当前最强的 AI 编程助手,因为一次内部失误,核心代码逻辑暴露在了全球开发者面前。
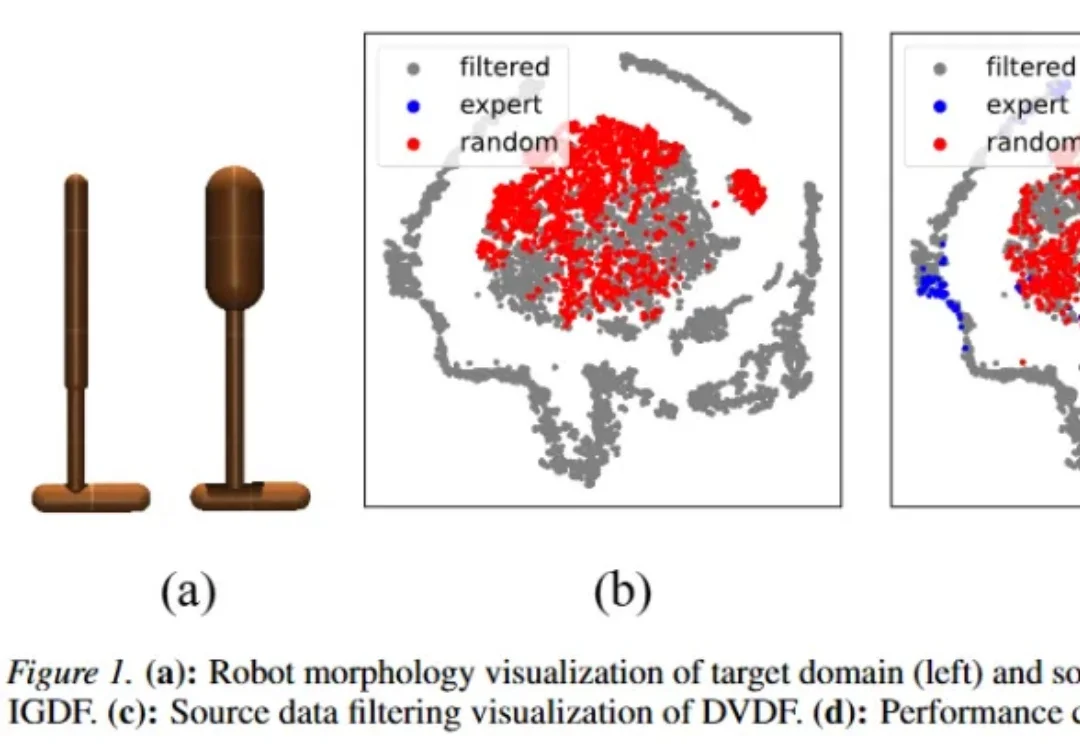
在现实世界中通过强化学习训练智能体,往往需要大量在线试错与环境探索,这不仅成本高昂,还可能带来显著安全风险:机器人可能因试错而损坏,自动驾驶的在线探索可能危及行车安全,而持续采集交互数据本身也代价巨大。
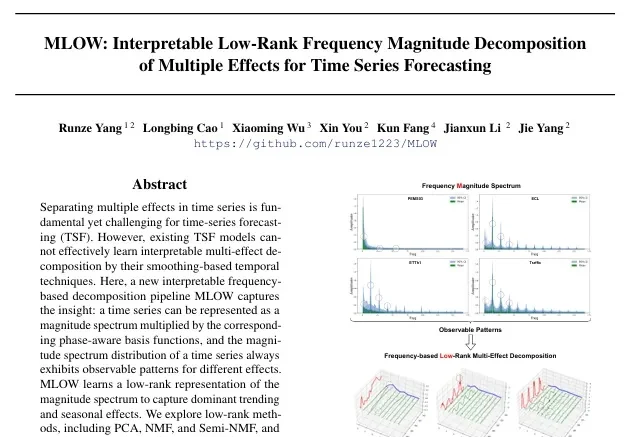
在时间序列预测领域,深度模型如iTransformer、PatchTST虽然性能强劲,却长期困于“黑盒”困境——预测准,但说不出为什么。

生物医学AI智能体正从「能不能做组学分析」快速进入下一阶段的检验:做出来的结果,能不能撑得住真实的治疗决策?哈佛医学院Zitnik团队的MEDEA 给出了一条明确的技术路线:与其追求更强的骨干大模型,不如在分析流程的每一步嵌入验证机制。
近年来,Decision-Coupled World Model 与 Model-based RL 在机器人领域取得了显著成功。通过学习环境动力学模型,智能体能够在内部模拟未来,从而进行规划与决策。但当系统从单机器人扩展到多机器人时,问题开始变得棘手。
《读佳》获悉,由北京青阳智维科技有限公司运营“量原求索Labelease”已推出,通过媒体报道可知,该公司隶属于字节跳动。 据悉,Labelease的主要作用是帮助模型团队解决模型从训练到部署全链路中