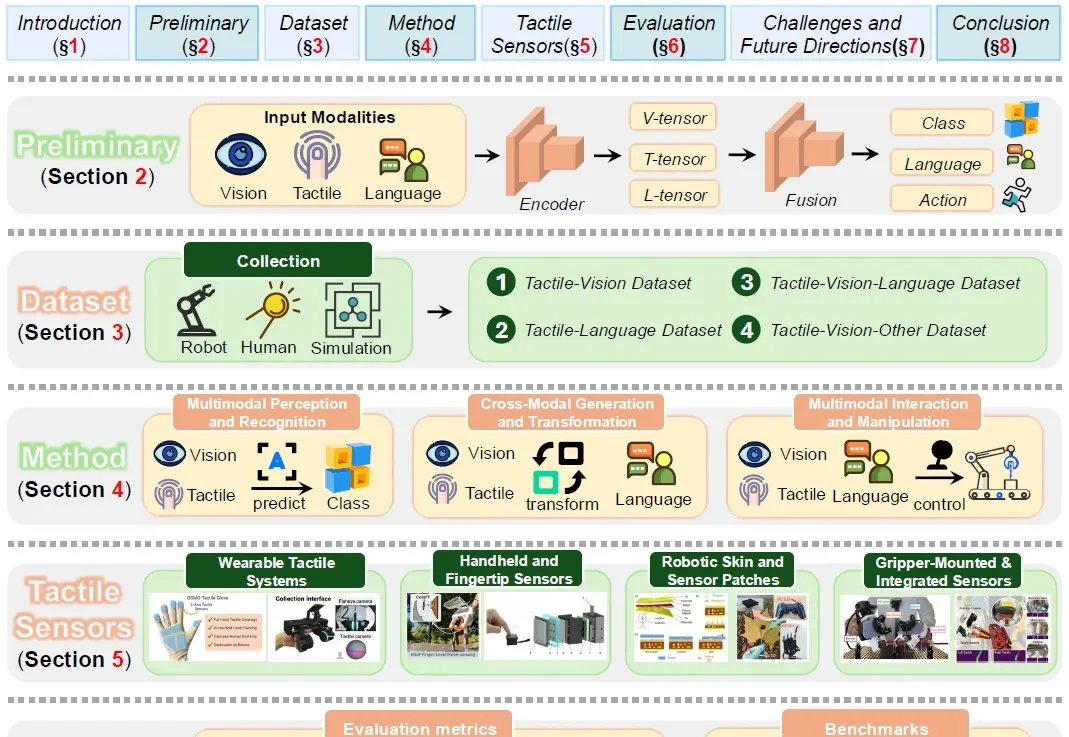
关于具身智能「触觉」,你想知道的都在这篇综述里了
关于具身智能「触觉」,你想知道的都在这篇综述里了在具身智能的感知拼图中,触觉一直扮演着不可或缺却难以被完美量化的角色。它提供了视觉等远程传感器无法替代的关于接触几何、材料特性和交互动态的直接反馈。
来自主题: AI技术研报
7043 点击 2026-04-08 09:14
 搜索
搜索
在具身智能的感知拼图中,触觉一直扮演着不可或缺却难以被完美量化的角色。它提供了视觉等远程传感器无法替代的关于接触几何、材料特性和交互动态的直接反馈。

Anthropic杀疯了!开年第一篇论文直接化身自爆卡车,实锤AI正在让程序员变傻。你以为效率提高了?其实只快了2分钟。

SLAM 在自动驾驶、机器人、AR/VR 乃至具身智能系统中都是至关重要的环节,它决定了算法能否在一个陌生环境中一边“看懂世界”,一边“知道自己在哪”。

Meta SOAR用「剧毒数据」当垫脚石,硬生生把模型从Fail@128的认知黑洞里拽出来,推理能力暴涨9.3%!2026年,这才是最硬核的反杀路线。
如果把手机屏幕想象成一个舞台,GUI 智能体就是台下那个 “被授权动手” 的人:它能看懂屏幕上的按钮、输入框和弹窗,能按你的指令去点、去滑、去输入。

研究者用特制雨伞干扰无人机视觉系统,让其误判目标在远去,从而失控俯冲。FlyTrap攻击无需信号干扰,仅靠物理图案就能欺骗多款商用无人机,实现静默捕获或击毁。实验显示,物理闭环攻击成功率超60%,且对新人物、新场景均有强泛化能力。这项研究揭示了AI感知系统的重大安全隐患,警示我们:视觉安全正成为智能设备的阿喀琉斯之踵。

就在大家都急头白脸地等待DeepSeek-V4的时候,冷不丁一篇新论文引起了网友们的注意—— 提出新稀疏注意力机制HISA(分层索引稀疏注意力),突破64K上下文的索引瓶颈,相比DeepSeek正在用的DSA(DeepSeek Sparse Attention)提速2-4倍。
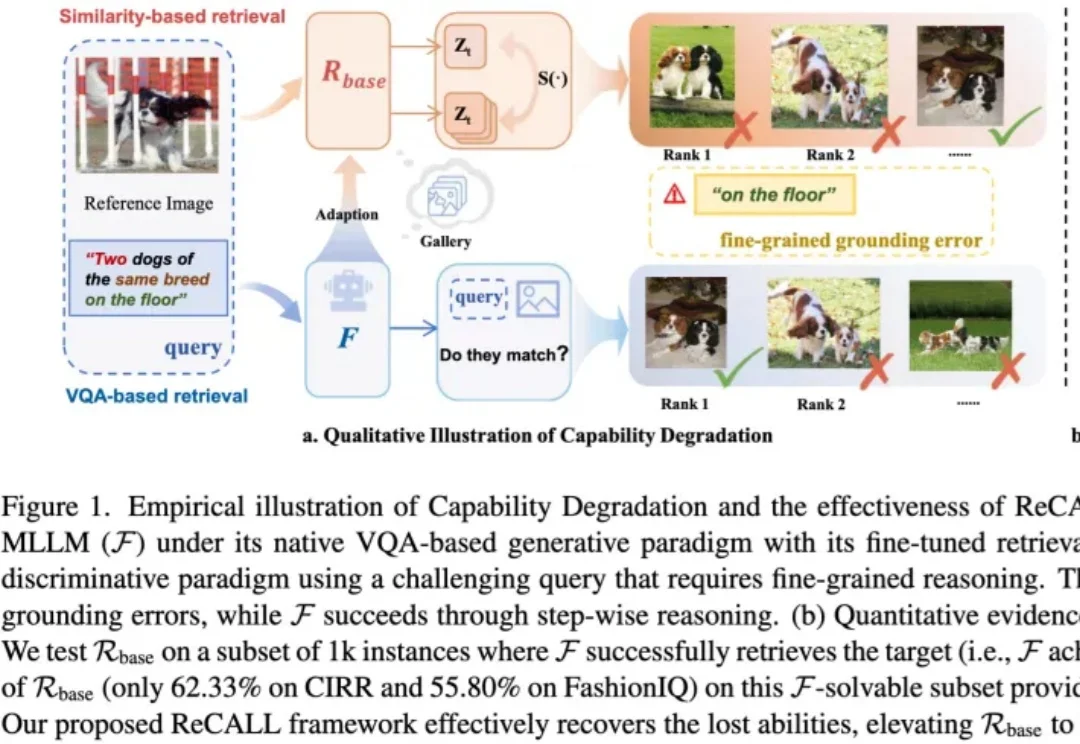
生成式模型当检索器大材小用效果还不好?

OpenAI Codex 团队的产品规格文档只有 10 个要点。不是说每个功能的文档只有 10 个要点,而是整个产品的 spec 就这么多。设计师写的代码量超过了六个月前工程师写的。50 到 100 人的团队,直到最近才有了第二个产品经理。
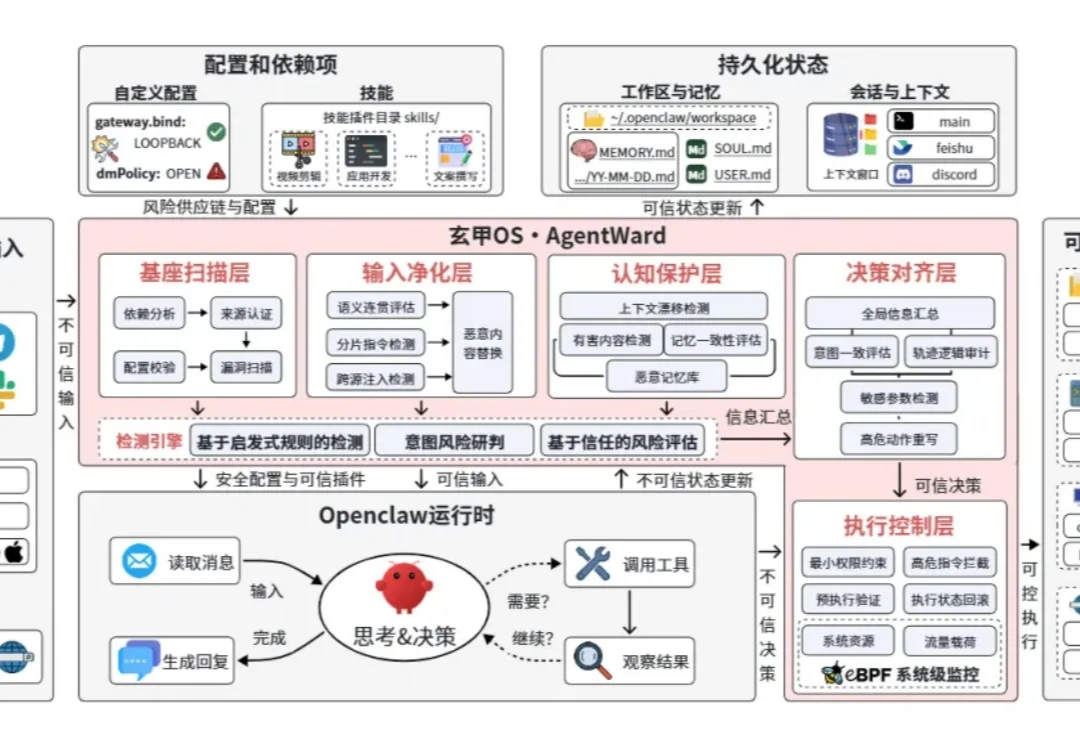
大模型技术正在经历一场从 “对话助手” 向 “自主智能体(Agent)” 的深刻演进。智能体不再局限于被动地理解与生成,而是具备了多步规划、工具调用、长期记忆与管理物理 / 数字世界的能力,正逐步深度嵌入企业侧的核心业务流程。这意味着,AI 的边界已从虚拟屏幕的对话框,正式延伸到了真实的生产系统中。