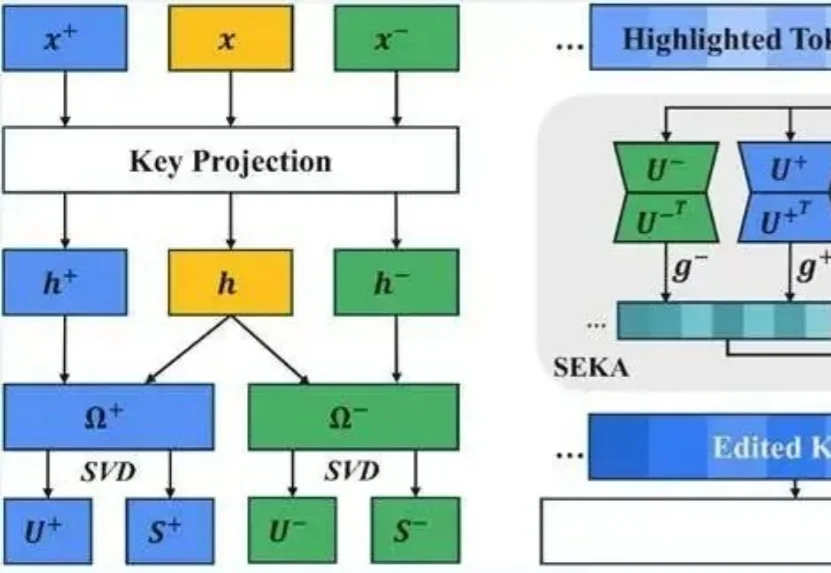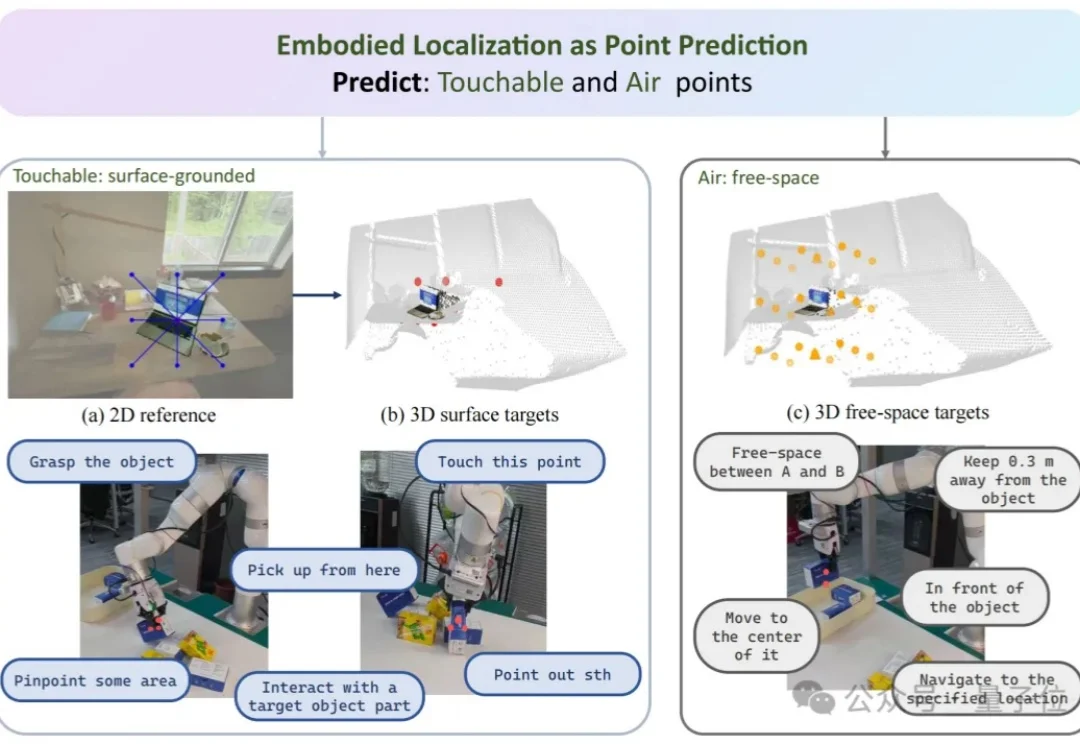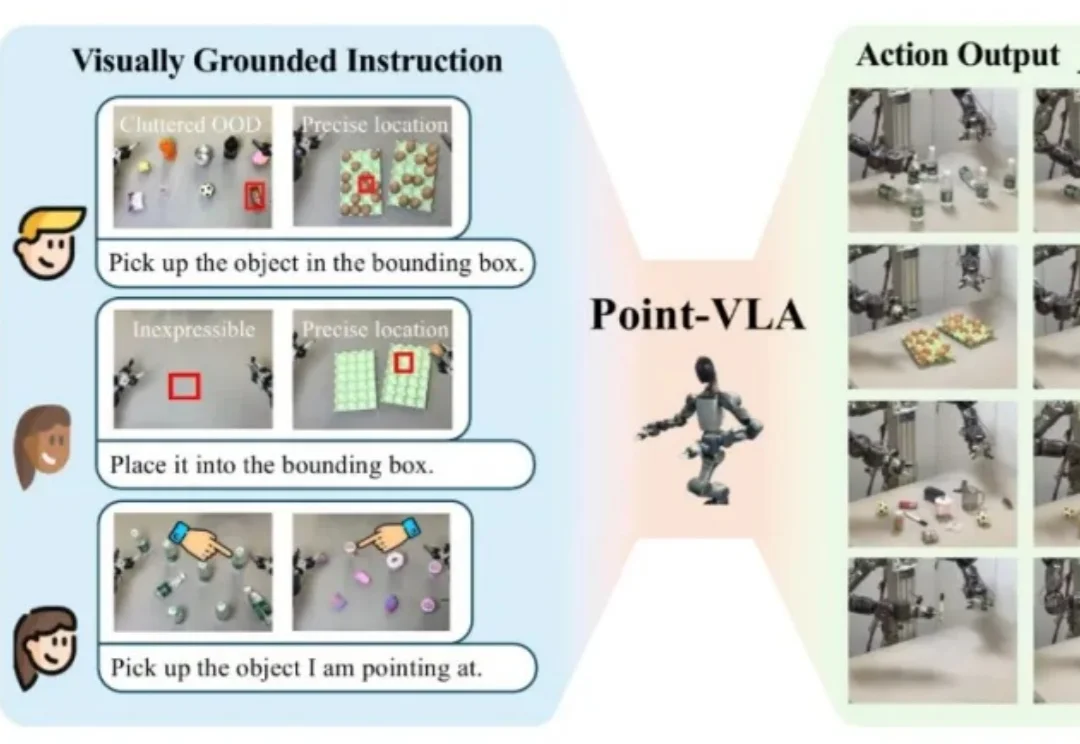
直指具身智能核心瓶颈,千寻智能高阳团队提出 Point-VLA:首次以视觉定位实现语言指令精准执行
直指具身智能核心瓶颈,千寻智能高阳团队提出 Point-VLA:首次以视觉定位实现语言指令精准执行设想这样一个场景:你打电话让同事去办公室某个地方拿东西,仅凭语言描述位置是多么困难。在办公室里,从一堆已经喝过的矿泉水瓶中,让对面同学递过来你之前喝过的那个,只用语言几乎无法准确描述——「左边第二个」?「有点旧的那个」?这时候,人们更倾向于用手指一下,或者拿出图片来指代。
来自主题: AI技术研报
7581 点击 2026-03-31 14:37