
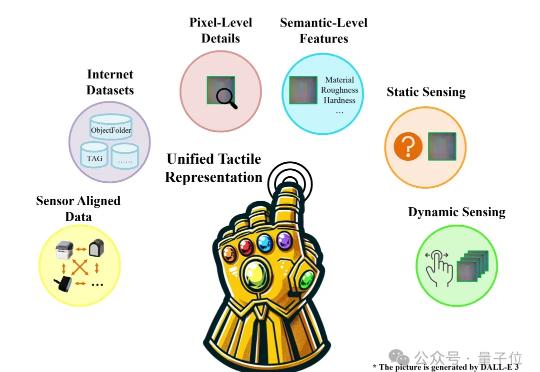
人大北邮等团队解视触觉感知统一难题,模型代码数据集全开源 | ICLR 2025
人大北邮等团队解视触觉感知统一难题,模型代码数据集全开源 | ICLR 2025机器人怎样感知世界?
来自主题: AI技术研报
10134 点击 2025-03-15 16:18
机器人怎样感知世界?
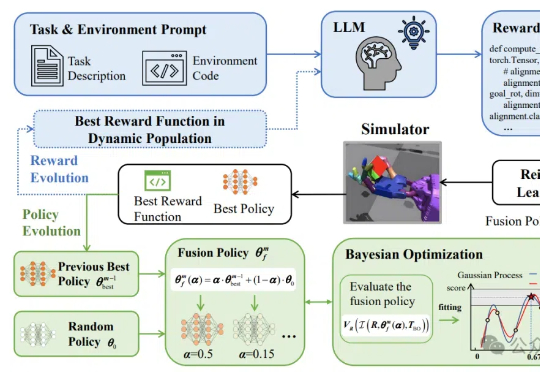
让机器人轻松学习复杂技能有新框架了!
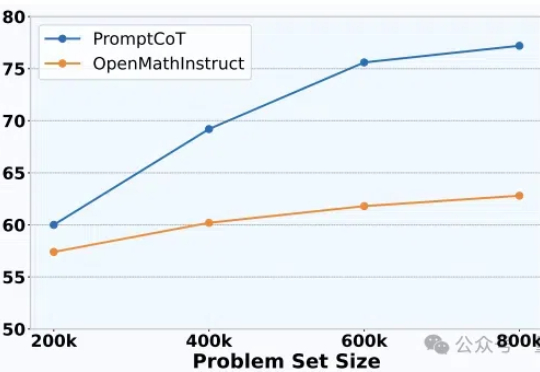
大模型架构研究进展太快,数据却快要不够用了,其中问题数据又尤其缺乏。

「压缩即智能」。这并不是一个新想法,著名 AI 研究科学家、OpenAI 与 SSI 联合创始人 Ilya Sutskever 就曾表达过类似的观点。

当前,视觉语言模型(VLMs)的能力边界不断被突破,但大多数评测基准仍聚焦于复杂知识推理或专业场景。本文提出全新视角:如果一项能力对人类而言是 “无需思考” 的本能,但对 AI 却是巨大挑战,它是否才是 VLMs 亟待突破的核心瓶颈?

今年,CVPR共有13008份有效投稿并进入评审流程,其中2878篇被录用,最终录用率为22.1%。

Transformer架构迎来历史性突破!刚刚,何恺明LeCun、清华姚班刘壮联手,用9行代码砍掉了Transformer「标配」归一化层,创造了性能不减反增的奇迹。

在 Sora 引爆世界模型技术革命的当下,3D 场景作为物理世界的数字基座,正成为构建动态可交互 AI 系统的关键基础设施。当前,单张图像生成三维资产的技术突破,已为三维内容生产提供了 "从想象到三维" 的原子能力。

尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。
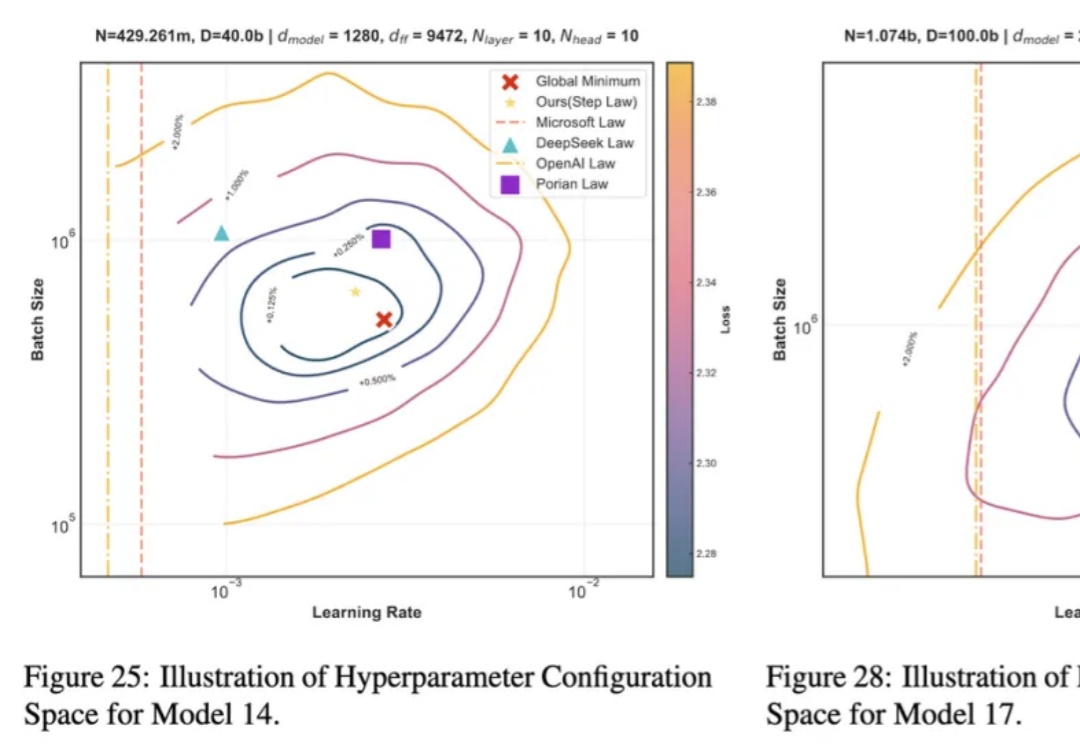
近年来,大语言模型 LLMs 在多种任务上的卓越表现已得到广泛认可。然而,要实现其高效部署,精细的超参数优化至关重要。为了探究最佳超参数的规律,我们开展了大规模的实证研究,通过在不同配置上进行网格搜索,我们揭示了一套通用的最优超参数缩放定律(Optimal Hyperparameter Scaling Law)。