
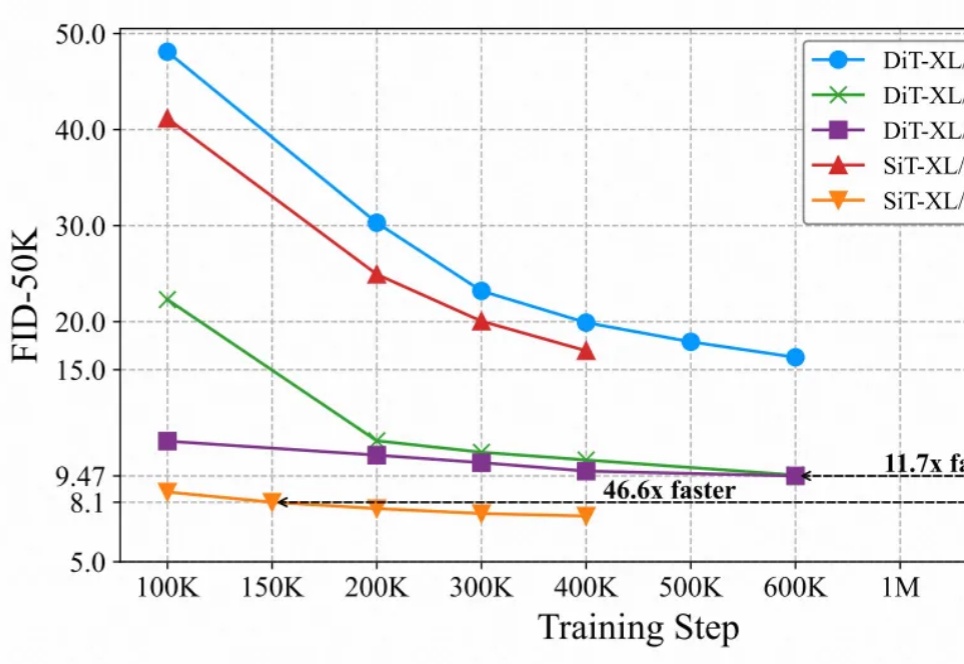
统一自监督预训练!视觉模型权重无缝迁移下游任务,SiT收敛提速近47倍
统一自监督预训练!视觉模型权重无缝迁移下游任务,SiT收敛提速近47倍最近的研究强调了扩散模型与表征学习之间的相互作用。扩散模型的中间表征可用于下游视觉任务,同时视觉模型表征能够提升扩散模型的收敛速度和生成质量。然而,由于输入不匹配和 VAE 潜在空间的使用,将视觉模型的预训练权重迁移到扩散模型中仍然具有挑战性。
来自主题: AI技术研报
10222 点击 2025-03-17 14:36
最近的研究强调了扩散模型与表征学习之间的相互作用。扩散模型的中间表征可用于下游视觉任务,同时视觉模型表征能够提升扩散模型的收敛速度和生成质量。然而,由于输入不匹配和 VAE 潜在空间的使用,将视觉模型的预训练权重迁移到扩散模型中仍然具有挑战性。
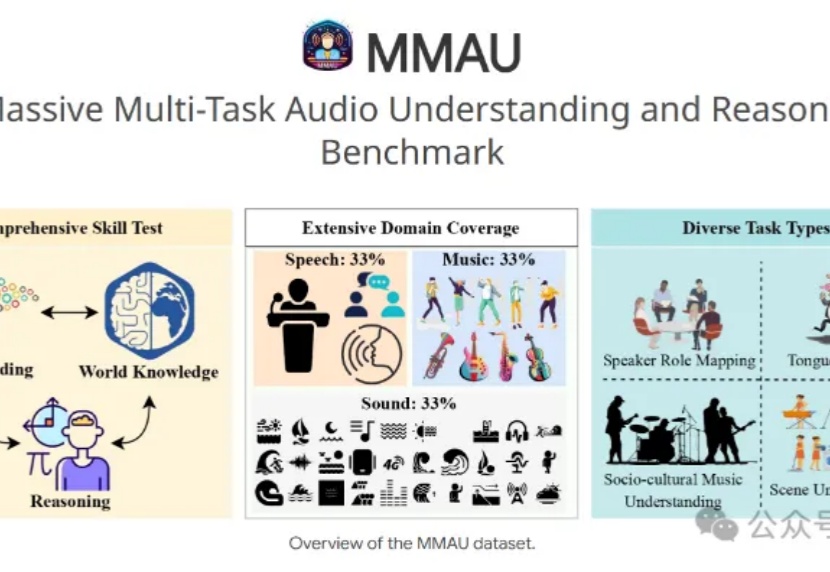
7B小模型+3.8万条训练数据,就能让音频理解和推断评测基准MMAU榜单王座易主?

LMM在人类反馈下表现如何?新加坡国立大学华人团队提出InterFeedback框架,结果显示,最先进的LMM通过人类反馈纠正结果的比例不到50%!
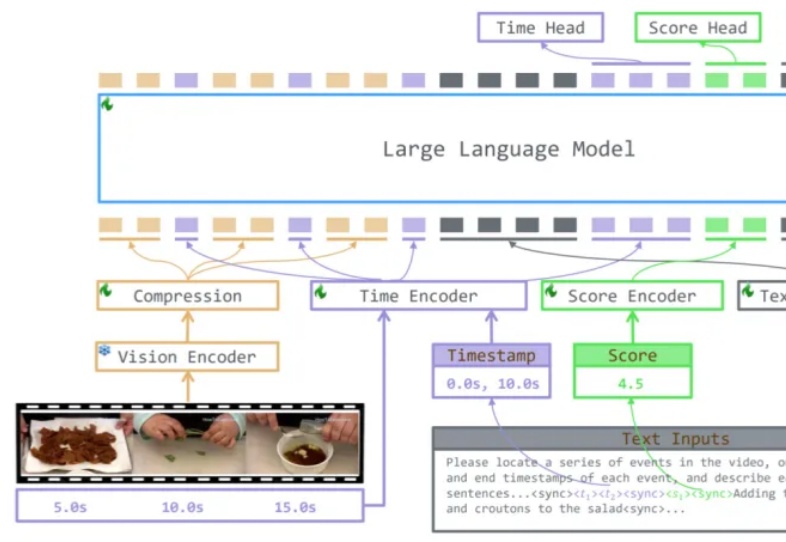
下班回家后你正深陷于一部两小时的综艺节目中,渴望找到那些让人捧腹的爆笑片段,却如同大海捞针。或者,在紧张刺激的足球赛中,你渴望捕捉到那决定性的绝杀瞬间,但传统 AI 视频处理技术效率低下,且模型缺乏泛化能力。为解决这些问题,香港中文大学(深圳)唐晓莹课题组联合腾讯 PCG 发布 TRACE 技术,通过因果事件建模为视频理解大模型提供精准的时间定位能力。

无需物理引擎,单个模型也能实现“渲染+逆渲染”了!

谷歌团队发现了全新Scaling Law!新方法DiLoCo被证明更好、更快、更强,可在多个数据中心训练越来越大的LLM。

何恺明团队提出的去噪哈密顿网络(DHN),将哈密顿力学融入神经网络,突破传统局部时间步限制,还有独特去噪机制,在物理推理任务中表现卓越。
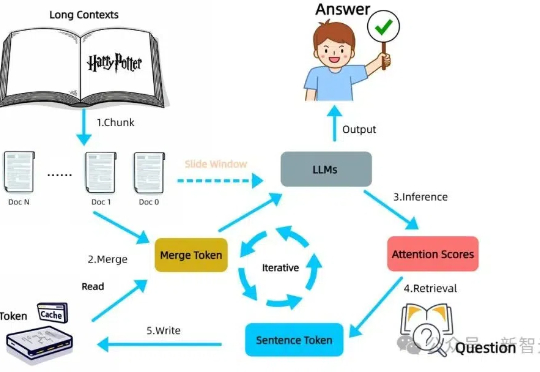
LLM自身有望在无限长token下检索信息!无需训练,在检索任务「大海捞针」(Needle-in-a-Haystack)测试中,新方法InfiniRetri让有效上下文token长度从32K扩展至1000+K,让7B模型比肩72B模型。
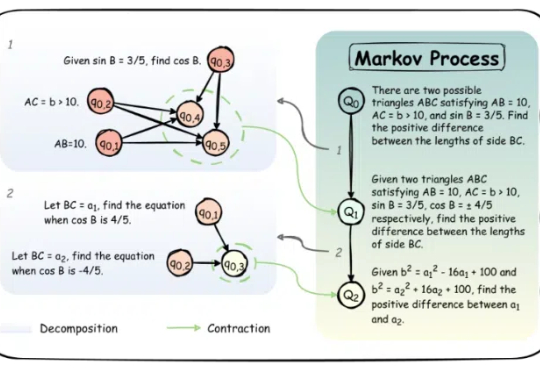
大语言模型(LLM)近年来凭借训练时扩展(train-time scaling)取得了显著性能提升。然而,随着模型规模和数据量的瓶颈显现,测试时扩展(test-time scaling)成为进一步释放潜力的新方向。
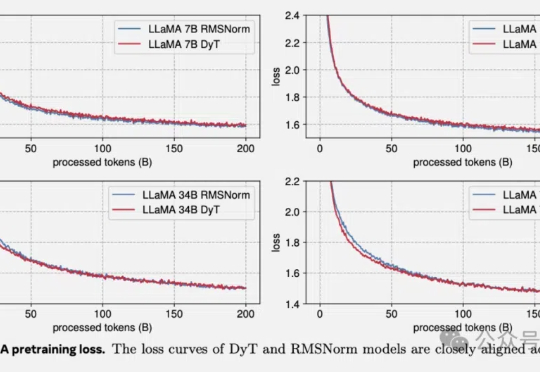
何恺明LeCun联手:Transformer不要归一化了,论文已入选CVPR2025。