中文大模型幻觉测评系列:事实性幻觉测评结果发布!
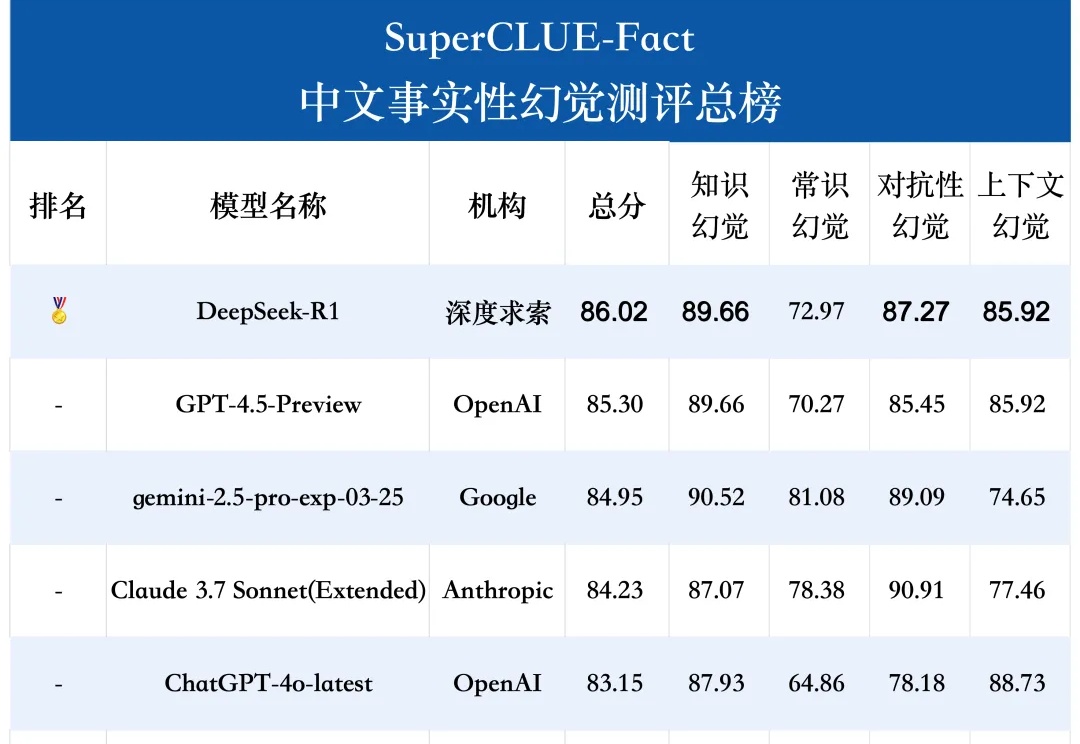
中文大模型幻觉测评系列:事实性幻觉测评结果发布!SuperCLUE-Fact是专门评估大语言模型在中文短问答中识别和应对事实性幻觉的测试基准。测评任务包括知识、常识、对抗性和上下文幻觉。
来自主题: AI资讯
14029 点击 2025-04-15 17:04
 搜索
搜索
SuperCLUE-Fact是专门评估大语言模型在中文短问答中识别和应对事实性幻觉的测试基准。测评任务包括知识、常识、对抗性和上下文幻觉。

2024年,智元机器人与北大成立联合实验室,8月发布“远征”与“灵犀”两大系列共五款商用人形机器人新品,10月旗下灵犀X1人形机器人官宣开源,12月宣布正式开启通用机器人量产,不断拓展应用场景。

AI「幻觉」可能在一般人看来是模型的胡言乱语,但它为科学家提供了新的灵感。David Baker甚至利用AI「幻觉」赢得了诺贝尔化学奖。纽约时报发文AI正在加速科学发展,但「幻觉」一词,在科学界仍有争议。
大语言模型(LLM)在各种任务上展示了卓越的性能。然而,受到幻觉(hallucination)的影响,LLM 生成的内容有时会出现错误或与事实不符,这限制了其在实际应用中的可靠性。

大模型幻觉,究竟是怎么来的?谷歌、苹果等机构研究人员发现,大模型知道的远比表现的要多。它们能够在内部编码正确答案,却依旧输出了错误内容。

哈佛大学研究了大型语言模型在回答晦涩难懂和有争议问题时产生「幻觉」的原因,发现模型输出的准确性高度依赖于训练数据的质量和数量。研究结果指出,大模型在处理有广泛共识的问题时表现较好,但在面对争议性或信息不足的主题时则容易产生误导性的回答。

作为 Meta 的前 CTO,Quora CEO Adam D'Angelo 目前还是 OpenAI 的董事会成员,在 Quora 之外推出的 Poe,成为当下接入大模型最多的 Chatbot 平台:GPT-4、Claude3、Mistral 等模型都有,用户也可以在上面搭建自己的 Chatbot 机器人,如果有别的用户使用,还可以产生收益。

DeepMind 这篇论文一出,人类标注者的饭碗也要被砸了吗?

大模型幻觉问题还有另一种解法?斯坦福联手OpenAI研究人员提出「元提示」新方法,能够让大模型成为全能「指挥家」,汇聚不同专家模型精华,让GPT-4的输出更精准。

大型语言模型(LLM)虽然在诸多下游任务上展现出卓越的能力,但其实际应用还存在一些问题。其中,LLM 的「幻觉(hallucination)」问题是一个重要缺陷。