
对话Clipto.AI创始人康洪文:没有记忆的AI,只是一个“失忆”的聪明人
对话Clipto.AI创始人康洪文:没有记忆的AI,只是一个“失忆”的聪明人模型会升级,Agent会重构,但用户长期积累的记忆不会轻易迁移。
来自主题: AI资讯
6396 点击 2026-07-01 15:02
 搜索
搜索
模型会升级,Agent会重构,但用户长期积累的记忆不会轻易迁移。

18天后,AI圈终于迎来了一场狂欢!今天,Anthropic官宣:美国商务部正式撤销对Anthropic旗下神级模型Fable 5(以及Mythos 5)的出口管制,明天恢复访问。

2026年,具身智能赛道的融资热度仍在持续,但投资人的提问方式已经变了。
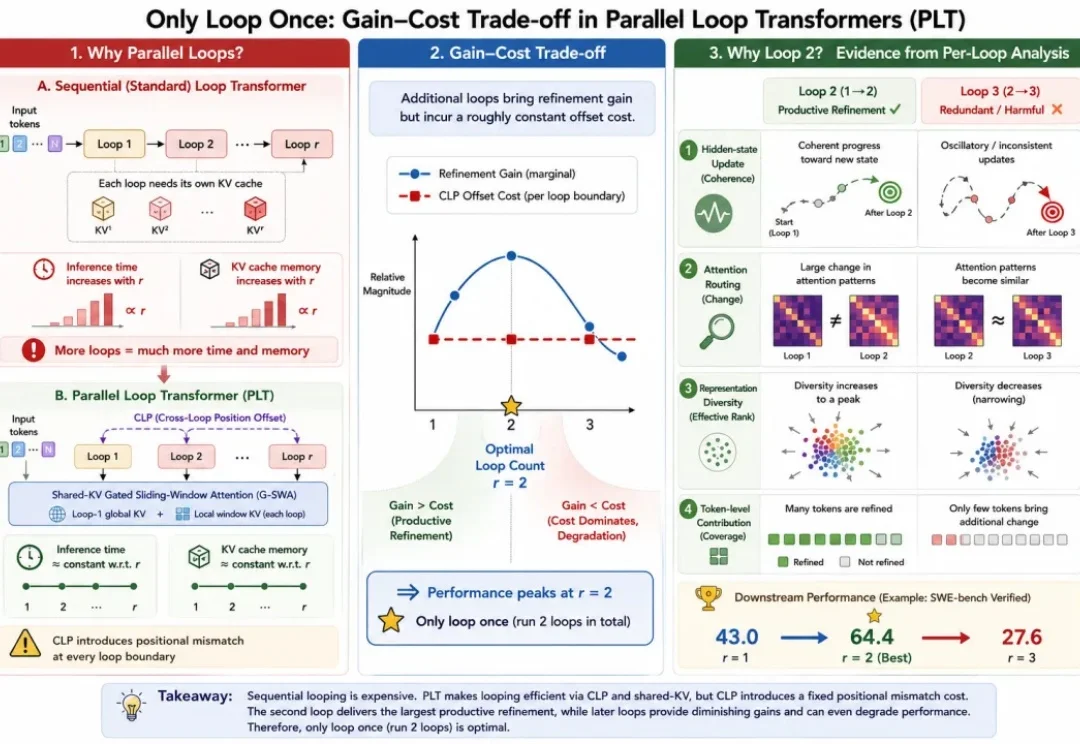
当所有人都在比谁「想得更久、算得更多」——推理模型动辄输出成千上万个思考 token,循环式架构恨不得在内部反复迭代十遍八遍——一项新研究反手泼了盆冷水:

知识第一次,能像代码一样利滚利。前OpenA 创始团队成员、特斯拉前 AI 高级总监 Andrej Karpathy,提出一个狠招:别再用 RAG 检索你的知识库,让大模型把它「编译」成一座持续生长的活 Wiki。两个多月,他在GitHub屠出 5000+ star。

AgentSociety²是清华大学团队推出的社会科学研究新工具,通过AI智能体模拟社会行为,帮助研究者构建实验环境,直接运行社会假设。它让AI同时扮演研究助手和实验参与者角色,使复杂社会问题能被构造、运行和分析,提升研究效率与可复现性。

最近硅谷最火的岗位,非FDE莫属。FDE全称“Forward Deployment Engineer”,可以直接翻译成“前线部署工程师”。他们既要懂模型和技术,也要理解客户的数据、流程和业务痛点,核心任务是把AI从demo变成各个职业自己的AI-native工作流。

卫星和航空影像里的目标,不仅大小相差悬殊,还可能朝向任意方向:一边是细长的桥梁、船舶,一边是密集的小车和大面积运动场。PKINet-v2是一种改进的遥感目标检测模型,能同时处理复杂形状和尺度变化的问题。

Google 将开始通过其云服务提供软件公司 SandboxAQ 的专业人工智能模型,扩展企业和研究机构对旨在加速药物发现、材料科学和半导体制造技术的访问。SandboxAQ 是 Alphabet 的分拆公司,是越来越多致力于利用 AI 解决棘手研究问题的公司之一。

近日,Hermes Agent上线了MoA(Mixture of Agents)功能,支持用户自由组合多种模型作为虚拟模型使用,在Nous Research即将发布的基准测试中,这个混合模型的评分超过了Opus 4.8 和GPT-5.5。