
FaceMind 陆弘远:在世界模型的“原点”,做一个“非共识”的Neolab
FaceMind 陆弘远:在世界模型的“原点”,做一个“非共识”的Neolab走在风口浪尖,拥抱最新的技术。
来自主题: AI资讯
7992 点击 2026-07-02 10:35
 搜索
搜索
走在风口浪尖,拥抱最新的技术。
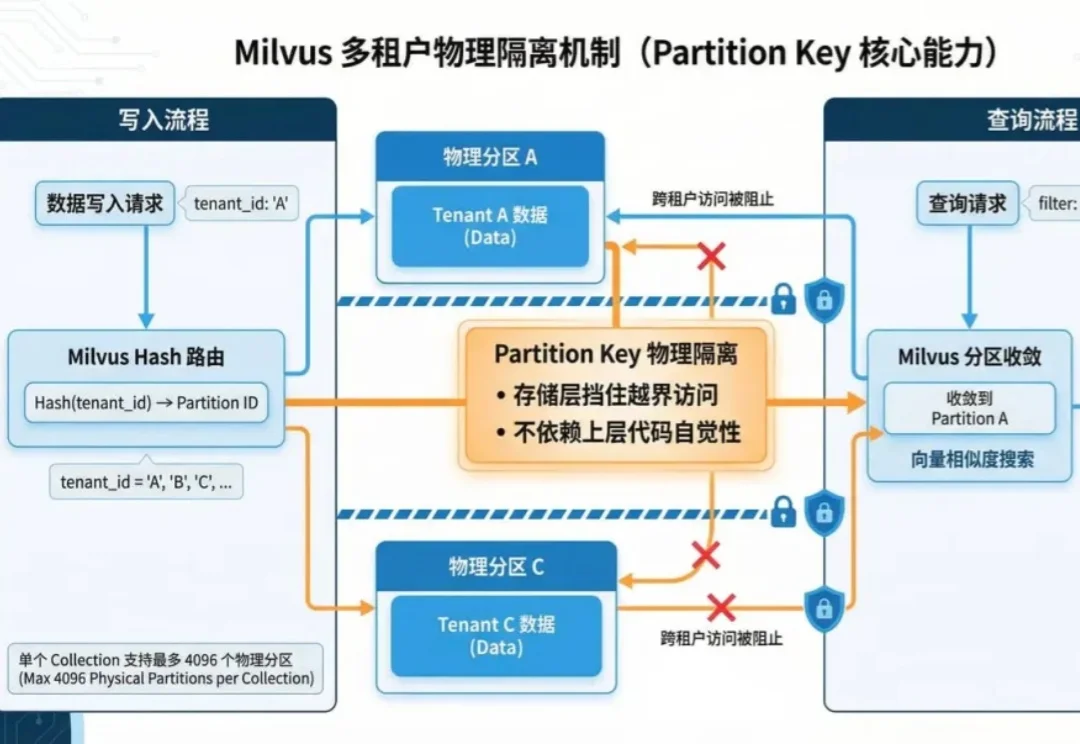
多租户 RAG 与Agent系统的生产实践中,最致命的事故莫过于数据串租,系统将租户 B 的私有数据作为背景知识,回答了租户 A 的提问。

大模型公司在港股热度正酣,现在,卖Token的公司也开始冲刺了。硅基流动已向港交所提交上市申请,剑指港股「AI Token工厂第一股」。此前,硅基流动已完成7轮融资,估值77.4亿元。阿里、美团、商汤、蔚来、智谱等产业方和明星AI投资机构均有押注。
去年夏天,MBZUAI 校长、CMU 教授邢波一篇《世界模型批评》吸引了研究社区广泛关注,他从科幻经典《沙丘》里「完美模拟现实」的想象出发,逐一拆解了当下几大世界模型流派的硬伤,提出了一套新架构,也由此引出了他与 Yann LeCun 之间一场关于「世界模型到底该怎么造」的公开辩论。

Prompt还没退场,Loop已经开始接管AI叙事。

本篇文章根据我在本月 43 Talks 线下活动中的分享整理而成。主理人李继刚邀请我时,给的主题词只有一个:Context。我想从 Agent 的视角出发,讨论一个判断:随着模型和 Harness 逐步趋同,真正决定 Agent 能力边界的,会越来越是 Context。

Yann LeCun的JEPA架构很可能不会work,但至少证明了隐空间比像素或文本空间具备更强的泛化能力;
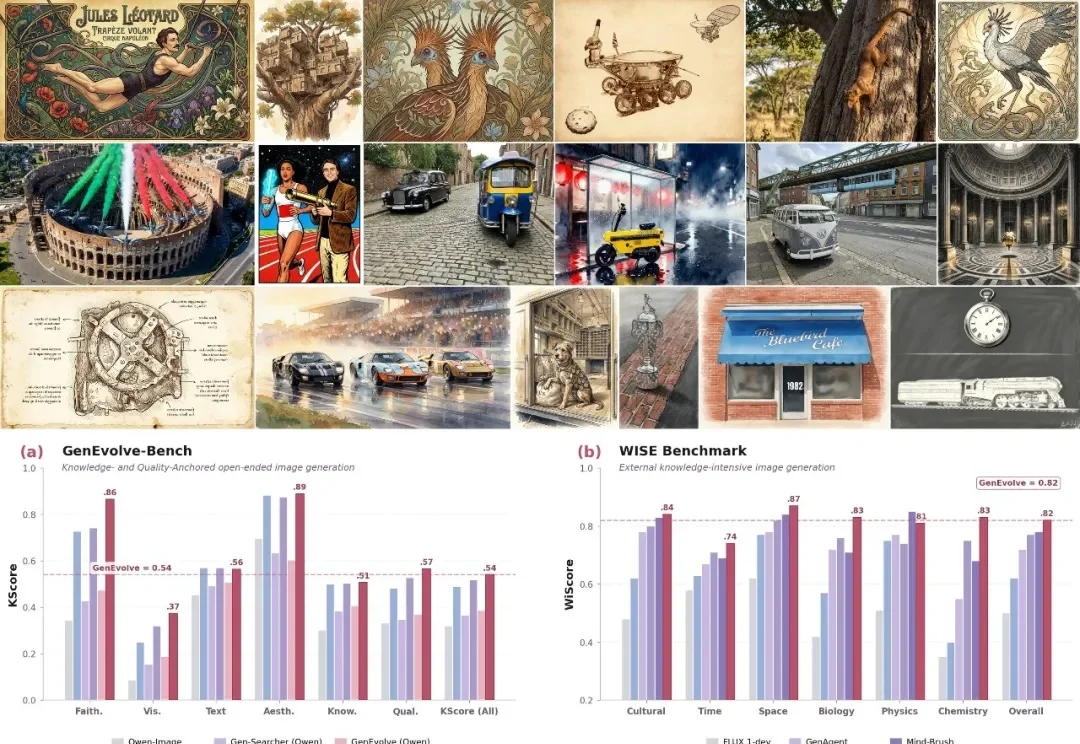
图像生成正在从「一句话生成一张图」,走向更接近真实创作流程的开放任务。
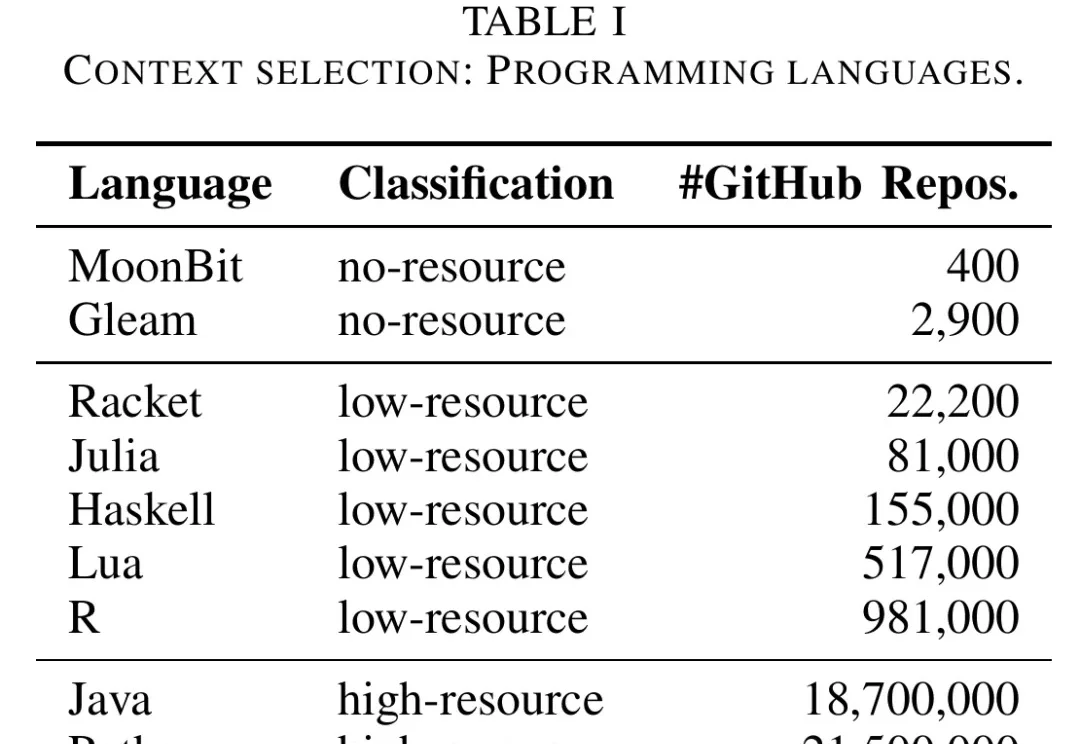
对于Python、Java、JavaScript这些语言,大模型通常能给出相当成熟的答案。

模型会升级,Agent会重构,但用户长期积累的记忆不会轻易迁移。