
刚刚,GPT-5.5被星火医疗大模型V3.5反超了!
刚刚,GPT-5.5被星火医疗大模型V3.5反超了!刚刚,医疗大模型赛道的魔咒,终于被打破了!讯飞医疗正式发布——星火医疗大模型V3.5。生成病历医生采纳率91%、书写时间缩短52%、累计辅助诊断超12亿次。这一连串的数字,直接把医疗AI「最难用的门槛」踩在脚下。
来自主题: AI资讯
9958 点击 2026-06-14 12:52
 搜索
搜索
刚刚,医疗大模型赛道的魔咒,终于被打破了!讯飞医疗正式发布——星火医疗大模型V3.5。生成病历医生采纳率91%、书写时间缩短52%、累计辅助诊断超12亿次。这一连串的数字,直接把医疗AI「最难用的门槛」踩在脚下。
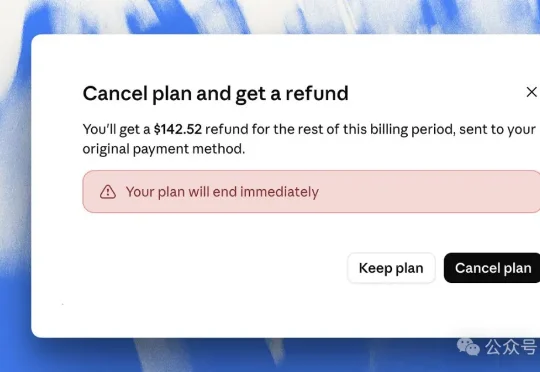
刚刚,Anthropic开始退款,截止日期为6月20日!美国一纸禁令,最强AI模型Fable 5说没就没,虽说能退款很好,但大多数用户,还是最想让它回来。
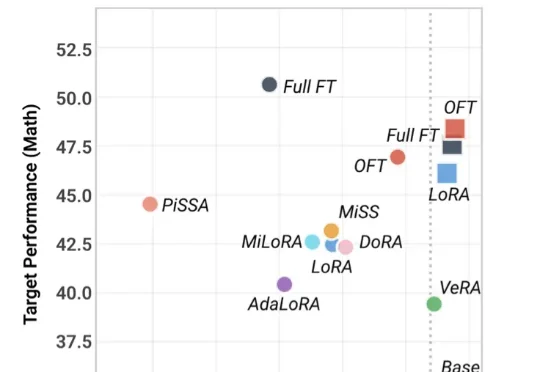
近期,来自香港中文大学、西湖大学、德国马普所等机构的研究者提出了 PEFT-Arena —— 一个从稳定性‑可塑性权衡(stability–plasticity trade-off)视角重新审视 PEFT 方法的评测基准与分析框架。该工作已在 ICLR 2026 相关 workshop 上进行了展示,并开源了完整代码。

最近整个世界的魔幻程度,真的让人唏嘘。 今天早上,Anthropic收到了美国商务部的一封信。 信的内容很简单,以国家安全为由,要求Anthropic立刻暂停所有外国公民对Fable 5和Mythos

GLM-5.2 是智谱迄今能力最强的开源模型,支持真正可用的 1M 上下文,并在长程任务中继续保持领先。它也依旧是我们心中最强的国产 Coding 模型。

今天,由李飞飞联合创立的空间智能公司 World Labs 在同一天发布了三篇技术论文!三篇论文分别由公司内部实习生主导完成,研究方向各异,但共享同一个核心命题:借助已在海量图片数据上训练成熟的 2D 生成模型,降低 3D 内容生成的难度门槛。

香港城市大学曾晓成教授与中国石油大学(华东)钟杰教授团队给出了终结级的分子水平证据,成果发表于《Nature Physics》。他们首创了一套无监督深度学习框架,不给AI任何预设条件,直接把海量水系统中7400多万个水分子结构扔给模型,让AI自己去悟。结果不仅直接证明常压水里确实存在两种「暗」组份,还把A/B水分子相互变身的「立交桥」路线图给完整画了出来。
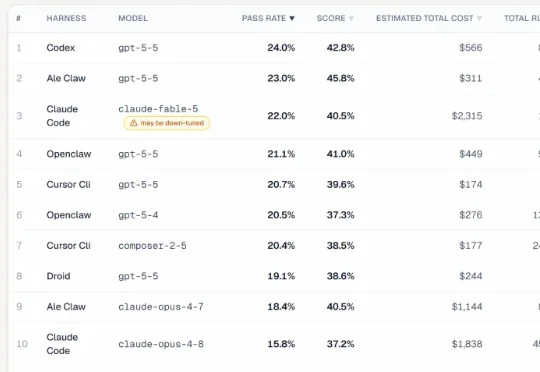
刚刚,UC伯克利放出了一场号称“智能体最后的考试”的全新基准测试。它把当今最强的AI Agent们拉到考场上,让它们干真正的活——在Siemens NX里建3D模型、在Unreal Engine里搭游戏场景、在Adobe After Effects里做特效合成。

本周「十字路口」,我们聊 FDE 这个正在被重新定义的岗位与分工:它究竟是在把“售前/交付”换个名字,还是代表 ToB AI 时代新的组织结构与商业边界?当模型越来越强,最后一公里为什么依然最难?企业真正缺的,到底是更强的模型,还是能把 AI 带进流程、接入系统、治理知识、持续迭代并对结果负责的人?
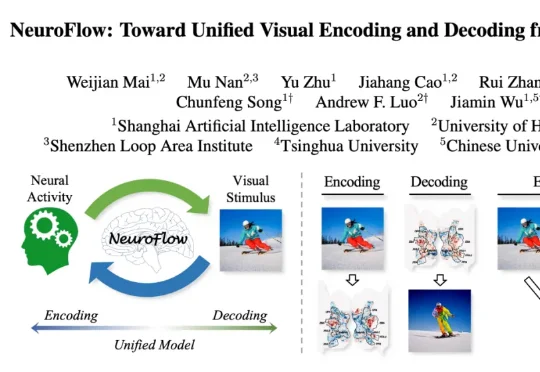
来自上海人工智能实验室、香港大学、香港中文大学等机构的研究团队,提出首个基于统一神经流模型的视觉-神经双向建模框架NeuroFlow,相关成果入选 CVPR 2026。它首次将视觉编码(写脑)与解码(读脑)整合到同一可逆流结构中,打通视觉感知与神经活动之间的双向通路,为理解人类视觉认知机制、构建下一代通用视觉假体与双向脑机接口提供了全新范式。