全球算力分布地图曝光:谁掌握能源,谁掌握AI未来
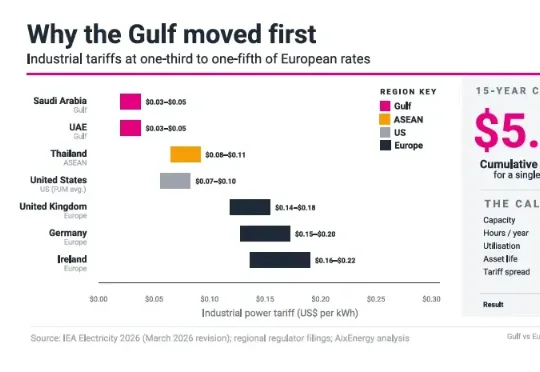
全球算力分布地图曝光:谁掌握能源,谁掌握AI未来近日,国际能源研究机构AixEnergy发布《Market Outlook》报告,提出一个值得关注的判断:AI基础设施首先是一项能源决策,其次才是一项技术决策。报告认为,决定未来全球AI版图的关键因素,正从芯片、模型和算法,转向稳定、低成本且能够快速接入的能源系统。海湾国家凭借廉价电力迅速崛起,美国受制于电网瓶颈,中国则依托新能源和产业链优势加速布局,东南亚正试图成为新的算力高地。
来自主题: AI技术研报
9185 点击 2026-06-24 17:38