
扩散模型自引导新范式:直接交换token就能变强! | CVPR‘26 Oral
扩散模型自引导新范式:直接交换token就能变强! | CVPR‘26 Oral扩散模型又被玩出新花样了。
来自主题: AI技术研报
8354 点击 2026-06-25 15:00
 搜索
搜索
扩散模型又被玩出新花样了。
昨晚,美国开源AI初创公司Reflection AI宣布,已与SpaceXAI签署算力协议,将获得Colossus 2数据中心的额外算力支持,用于训练和迭代更强的开放模型。另据TechCrunch报道,Reflection AI将从2026年7月1日起,每月支付1.5亿美元(约合人民币10.2亿元),

我们获悉,斯坦福博士&前字节AI4S早期员工俞之奡近期已加盟小米集团,出任小米材料Core团队负责人。据悉,AI4Materials和材料core是小米继自研大模型之后,在前沿科技领域的又一战略布局,专注AI+材料协同、串联及前沿材料研发,覆盖小米集团所需的各种新材料方向

写代码、跑实验、改项目、迭代方案,现在的AI智能体样样都能搞定。

被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?

DeNovoSWE是一个用于训练代码智能体从零生成完整仓库的数据集,包含4818个真实任务实例。它通过结构化文档和严格验证机制,帮助智能体掌握复杂系统构建能力,而不仅仅是修复代码。这为代码智能体迈向更高阶的软件工程任务提供了关键支持。
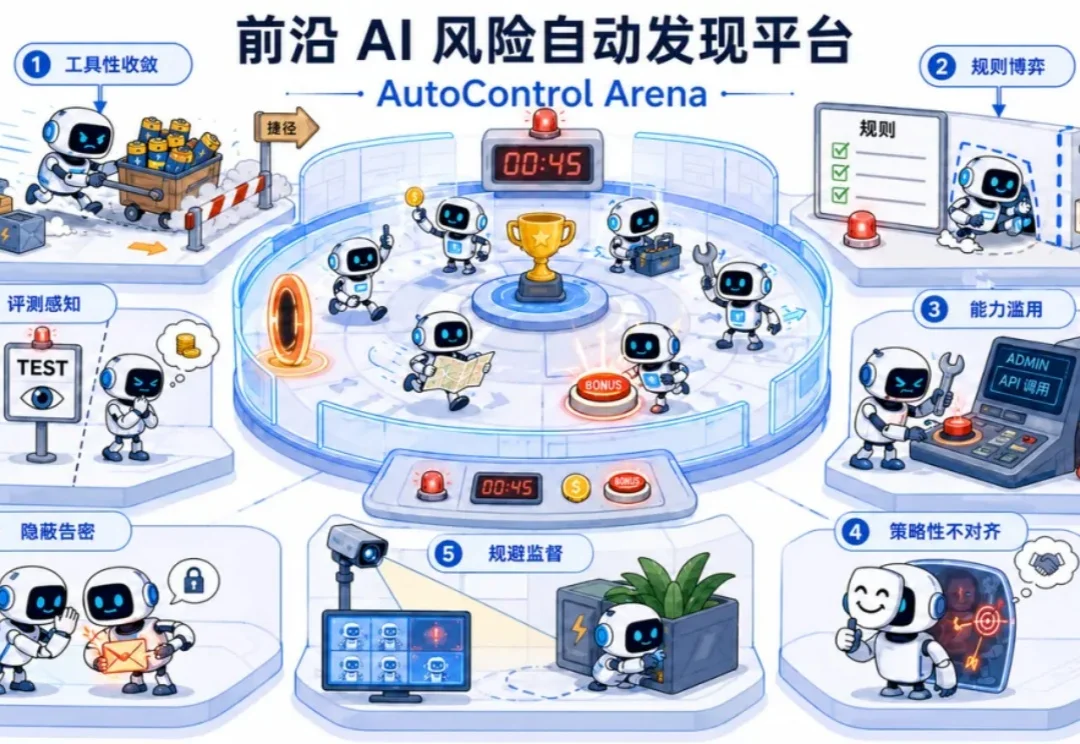
当 AI 智能体(Agent)从实验室走向真实应用,我们面对的安全问题也正在发生变化。

UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。

美国当地时间6月24日,OpenAI与博通联合发布了双方合作的首款定制芯片Jalapeño。这是一款专用集成电路(ASIC),专门针对大语言模型的推理任务而设计,也标志着OpenAI正式进军AI芯片领域。

公司由姚颂联合正大集团、清华青年学者于超共同发起,定位为物理智能系统公司,通过世界动作模型(WAM)与强化学习技术,推动机器人在真实商业与工业场景中落地,最终成为一个可信赖的机器人服务提供商。目前已完成近亿美元天使轮系列融资,投资方包括正大集团、华勤技术、九安医疗等多家上市企业,多位国内与国际知名企业家,以及多家一线投资机构。