10万引普林斯顿刘壮最新访谈:架构没那么重要,数据才是王道
10万引普林斯顿刘壮最新访谈:架构没那么重要,数据才是王道普林斯顿大学助理教授刘壮,在学术圈是一个颇为特殊的存在——他的每一篇论文几乎都在质疑某个“理所当然”的假设。架构真的重要吗?数据集真的足够多样吗?归一化层是必需的吗?大语言模型有世界模型吗?AI智能体能替代博士生吗?
来自主题: AI技术研报
8981 点击 2026-04-30 08:39
 搜索
搜索
普林斯顿大学助理教授刘壮,在学术圈是一个颇为特殊的存在——他的每一篇论文几乎都在质疑某个“理所当然”的假设。架构真的重要吗?数据集真的足够多样吗?归一化层是必需的吗?大语言模型有世界模型吗?AI智能体能替代博士生吗?

4 月 15 日,戴盟机器人联合Google DeepMind、中国移动、新加坡国立大学、香港科技大学、上海交通大学、日本东北大学等海内外数十家顶尖学术机构与知名企业,发布了全球最大规模含触觉全模态物理世界数据集Daimon-Infinity。
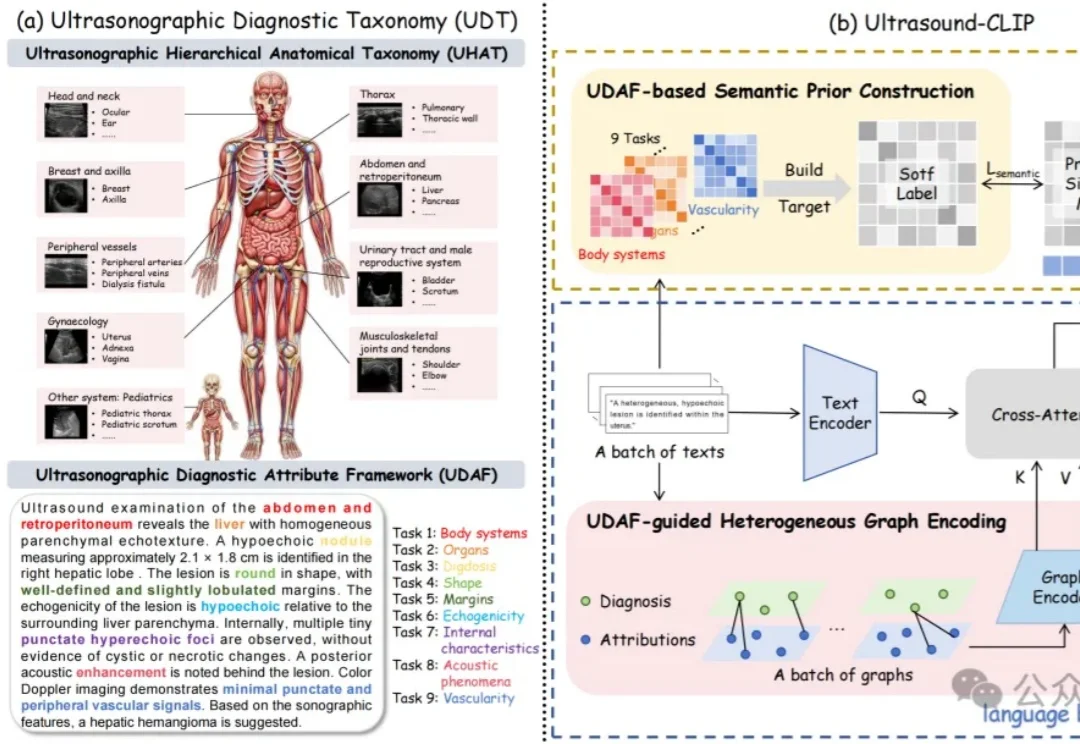
超声领域也有大模型了!

4 月 10 日晚,灵初智能发布了大模型、数据集与合作计划:包括策略模型 Psi-R2、世界模型 Psi-W0,以及总规模近 10 万小时的人类操作数据。它想回答的问题也很直接 —— 当真机数据不再是唯一解,机器人还能靠什么继续 scaling?

全球首个1毫秒级人体动作捕捉系统FlashCap,通过闪烁LED与事件相机结合,实现1000Hz超高帧率捕捉。无需昂贵设备或强光环境,低成本穿戴服即可精准捕捉极速动作。团队同步开源715万帧的FlashMotion数据集与多模态模型ResPose,显著提升运动分析精度,推动体育、VR与机器人领域迈向高动态智能新阶段。

什么在限制空间智能落地?

做深度估计、深度补全的人,大概都有过这样一个瞬间。

新一代代码模型的训练动态已与旧模型截然不同,主流强化学习方法和数据集在其上几乎“失效”。
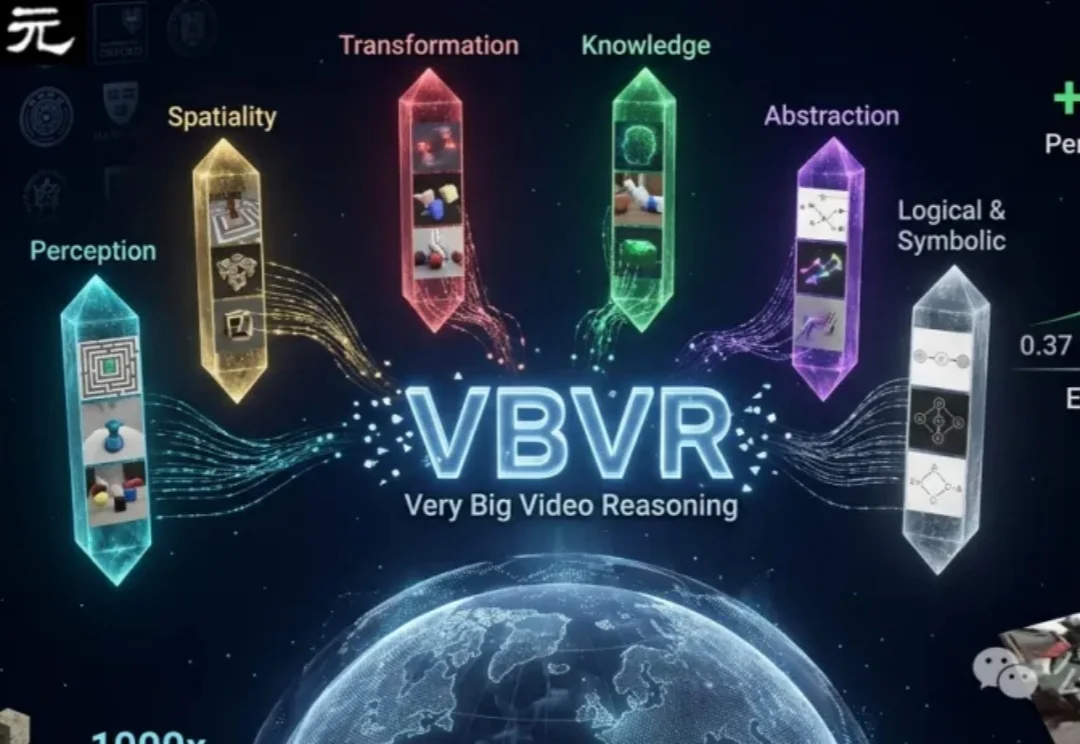
AI视频生成已能「画得像」,但不会「想得对」。VBVR推出百万级视频推理数据集,首次系统评测模型对空间、物理、逻辑和抽象的推理能力,发现顶尖模型通过率仅68%,暴露其缺乏真实认知,推动视频AI从「视觉模仿」迈向「智能推理」。

目前,该论文已录用至 CVPR 2026,相关数据集和模型训练训练和推理代码将逐步开源:究其原因,一个好故事并非一堆漂亮镜头的简单拼接,而是一个有结构、有逻辑的叙事整体。