万字综述遥感AI智能体!六大应用场景全面爆发,地理空间智能从「眼睛」变「大脑」
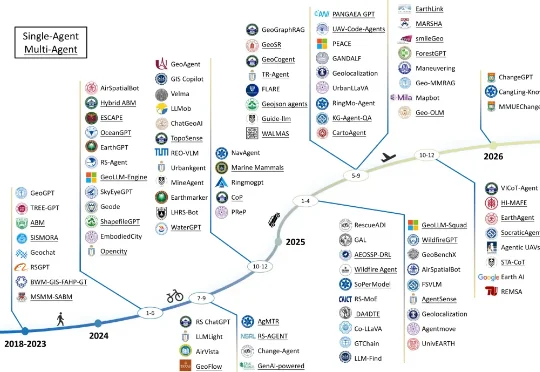
万字综述遥感AI智能体!六大应用场景全面爆发,地理空间智能从「眼睛」变「大脑」如今,一场由 AI 智能体驱动的变革正在发生。近日,来自香港科技大学、西北工业大学、清华大学等多家高校及研究机构的学者联合发布了遥感 AI 智能体领域系统综述。全文逾万字,首次为「遥感智能体」给出了严格定义,系统梳理了其架构、应用、数据集与未来方向。
来自主题: AI技术研报
8819 点击 2026-03-21 09:28
 搜索
搜索
如今,一场由 AI 智能体驱动的变革正在发生。近日,来自香港科技大学、西北工业大学、清华大学等多家高校及研究机构的学者联合发布了遥感 AI 智能体领域系统综述。全文逾万字,首次为「遥感智能体」给出了严格定义,系统梳理了其架构、应用、数据集与未来方向。
让OpenClaw帮干活还不够,现在,程序员们正想方设法让🦞自己变强。

港科大团队提出音频生成统一模型AudioX,只需一个模型,就能从文本、视频、图像等任意模态生成高质量音效和音乐,在多项基准上超越专家模型。团队同时开源了700万样本的细粒度标注数据集IF-caps与可控T2A评测基准T2A-bench,并在该基准上大幅领先现有方法。论文已被ICLR 2026接收。
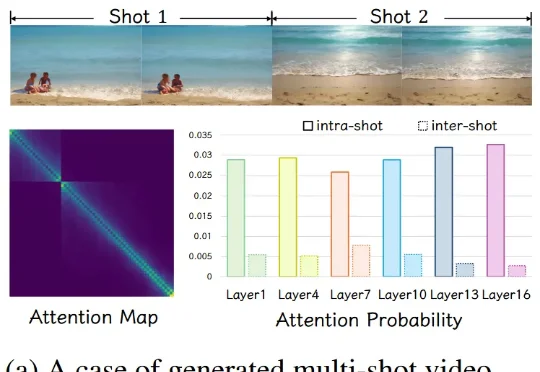
基于对注意力特性的观察,CineTrans 提出块对角掩码的通用机制,使视频生成模型能高效地自动化转场。为了进一步提升转场模型的效果和准确性,作者设计了详细的多镜头视频生产管线,并收集了一个高质量、多镜头数据集 Cine250K,大幅提升多镜头转场视频生成的效果。作为首个时间级可控的自动化转场模型,CineTrans 为这一领域的众多后续方法提供了关键技术。
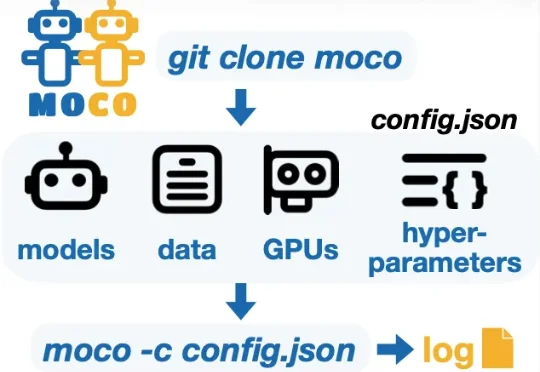
为了支持多模型协同研究并加速这一未来愿景的实现,华盛顿大学 (University of Washington) 冯尚彬团队联合斯坦福大学、哈佛大学等研究人员提出 MoCo—— 一个针对多模型协同研究的 Python 框架。MoCo 支持 26 种在不同层级实现多模型交互的算法,研究者可以灵活自定义数据集、模型以及硬件配置,比较不同算法,优化自身算法,以此构建组合式人工智能系统。MoCo 为设计、

DiscoX构建了一套200题的长文翻译数据集,以平均长度1,712 tokens的长篇章做评测单元,要求整个长文文本作为一个整体来翻译,除翻译准确度外,重点考察跨段落的逻辑与风格一致性、上下文中的术语精确性、以及专业写作规范,贴合用户真实的使用场景。
来自上海交通大学、清华大学、微软研究院、麻省理工学院(MIT)、上海 AI Lab、小红书、阿里巴巴、港科大(广州)等机构的研究团队,系统梳理了近年来大语言模型在数据准备流程中的角色变化,试图回答一个业界关心的问题:LLM 能否成为下一代数据管道的「智能语义中枢」,彻底重构数据准备的范式?
机器人领域是我们长期关注的赛道,而 Generalist 是当前机器人领域中极少数具备长期竞争潜力的公司,核心优势集中在数据规模、团队能力与清晰的 scaling 路径上。

为什么让多模态大模型“一步一步思考”(”Let’s think step by step”)来回答视频问题,效果有时甚至还不如让它“直接回答”?
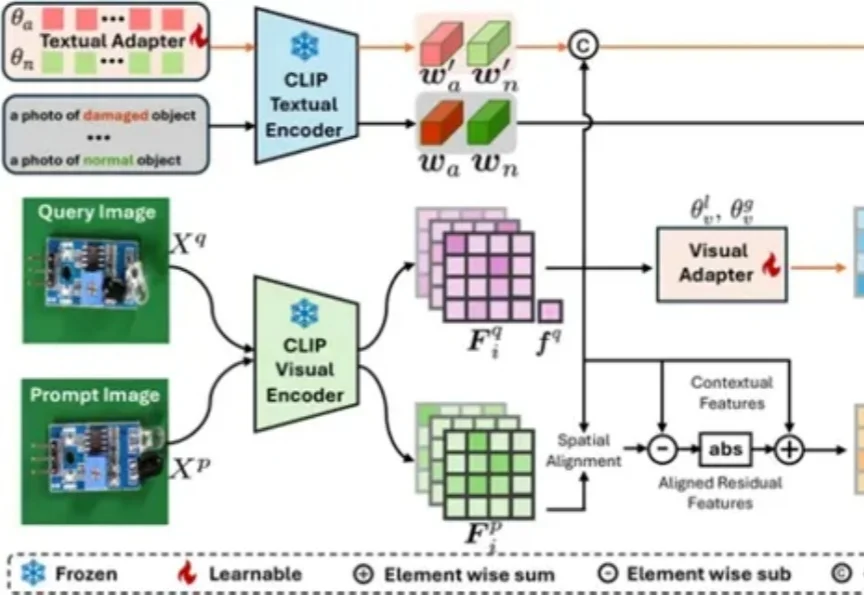
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。