
MPDS:提升电影海报生成效率的新型数据集
MPDS:提升电影海报生成效率的新型数据集MPDS(Movie Posters Dataset)是一个创新的电影海报数据集,旨在解决现有图像生成模型在制作电影海报时面临的挑战。
来自主题: AI技术研报
11980 点击 2024-11-02 17:21
 搜索
搜索
MPDS(Movie Posters Dataset)是一个创新的电影海报数据集,旨在解决现有图像生成模型在制作电影海报时面临的挑战。

自去年底以来,时序预测领域正在经历重大转型,从传统的「单一数据集训练单一模型」的模式逐步转向「通用预测基础模型」。

清华大学推出的SonicSim平台和SonicSet数据集针对动态声源的语音处理研究提供了强有力的工具和数据支持,有效降低了数据采集成本,实验证明这些工具能有效提升模型在真实环境中的性能。

近期,港中大(深圳)联手趣丸科技联合推出了新一代大规模声音克隆 TTS 模型 ——MaskGCT。该模型在包含 10 万小时多语言数据的 Emilia 数据集上进行训练,展现出超自然的语音克隆、风格迁移以及跨语言生成能力,同时保持了较强的稳定性。MaskGCT 已在香港中文大学(深圳)与上海人工智能实验室联合开发的开源系统 Amphion 发布。
TS-Reasoner是一个创新的多步推理框架,结合了大型语言模型的上下文学习和推理能力,通过程序化多步推理、模块化设计、自定义模块生成和多领域数据集评估,有效提高了复杂时间序列任务的推理能力和准确性。实验结果表明,TS-Reasoner在金融决策、能源负载预测和因果关系挖掘等多个任务上,相较于现有方法具有显著的性能优势。
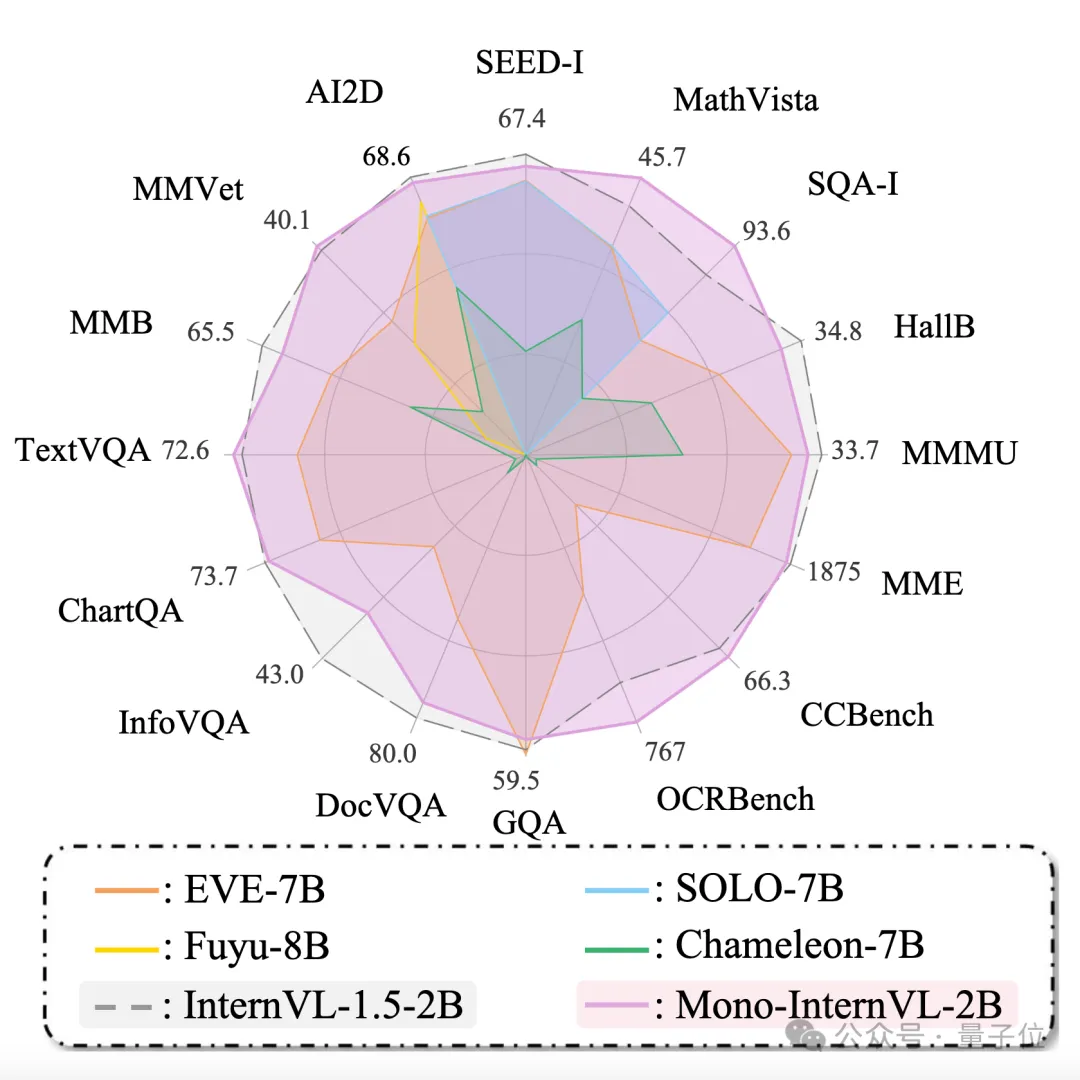
原生多模态大模型性能瓶颈,迎来新突破! 上海AI Lab代季峰老师团队,提出了全新的原生多模态大模型Mono-InternVL。 与非原生模型相比,该模型首个单词延迟最多降低67%,在多个评测数据集上均达到了SOTA水准。
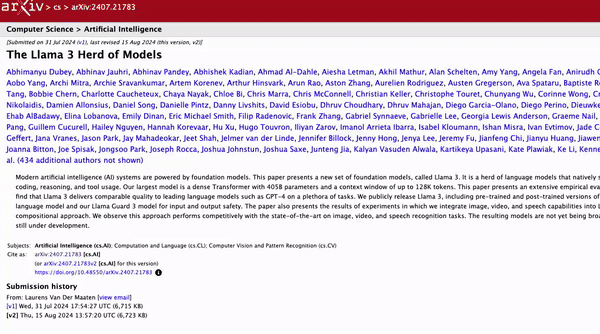
「这才是开放研究该有的样子。」 经常刷 arXiv 的同学,你有没有发现页面上多了个新功能?这个新功能(图中的「Hugging Face」按钮)隐藏在「Code, Data, Media」选项卡下,选中之后就可以直达相关的 Hugging Face 论文、模型和数据集。

Time-MoE采用了创新的混合专家架构,能以较低的计算成本实现高精度预测。研发团队还发布了Time-300B数据集,为时序分析提供了丰富的训练资源,为各行各业的时间序列预测任务带来了新的解决方案。

视频多模态大模型(LMMs)的发展受限于从网络获取大量高质量视频数据。为解决这一问题,我们提出了一种替代方法,创建一个专为视频指令跟随任务设计的高质量合成数据集,名为 LLaVA-Video-178K。

大语言模型(LLM)正在推动通信行业向智能化转型,在自动生成网络配置、优化网络管理和预测网络流量等方面展现出巨大潜力。未来,LLM在电信领域的应用将需要克服数据集构建、模型部署和提示工程等挑战,并探索多模态集成、增强机器学习算法和经济高效的模型压缩技术。