RAG没有银弹!四级难度,最新综述覆盖数据集、解决方案,教你「LLM+外部数据」的正确使用姿势
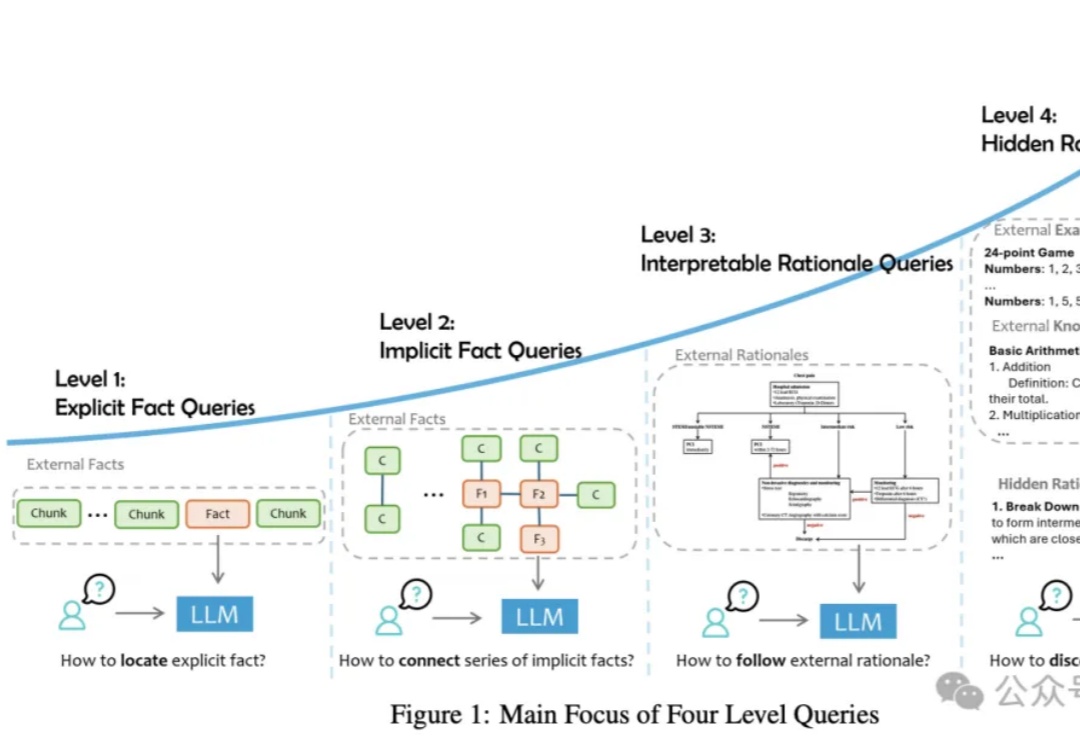
RAG没有银弹!四级难度,最新综述覆盖数据集、解决方案,教你「LLM+外部数据」的正确使用姿势论文提出了一种RAG任务分类法,将用户查询分为四个级别,并讨论了将外部数据集成到LLMs中的三种主要方式。从简单的事实检索到复杂的推理任务,每个级别都有其独特的难点和解决方案,需要不同的技术和方法来优化性能。
来自主题: AI技术研报
9413 点击 2024-11-21 13:39
 搜索
搜索
论文提出了一种RAG任务分类法,将用户查询分为四个级别,并讨论了将外部数据集成到LLMs中的三种主要方式。从简单的事实检索到复杂的推理任务,每个级别都有其独特的难点和解决方案,需要不同的技术和方法来优化性能。
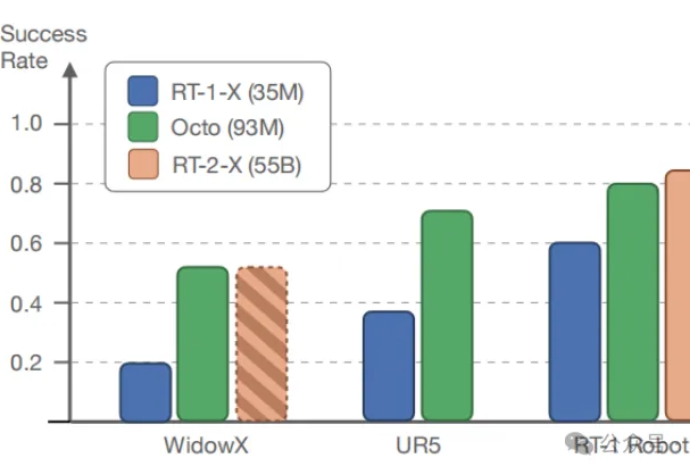
在多样化的机器人数据集上预训练的大型策略有潜力改变机器人学习:与从头开始训练新策略相比,这种通用型机器人策略可以通过少量的领域内数据进行微调,同时具备广泛的泛化能力。

近日,中科大王杰教授团队 (MIRA Lab) 针对离线强化学习数据集存在多类数据损坏这一复杂的实际问题,提出了一种鲁棒的变分贝叶斯推断方法,有效地提升了智能决策模型的鲁棒性,为机器人控制、自动驾驶等领域的鲁棒学习奠定了重要基础。论文发表在 CCF-A 类人工智能顶级会议 Neural Information Processing Systems(NeurIPS 2024)。

GenXD模型结合CamVid-30K数据集突破了3D和4D场景生成的挑战,能从单张图片生成逼真的动态3D和4D场景。这一进展为虚拟世界构建带来新的可能性,让动态场景的生成更加快速和真实。

继稚晖君之后,国内又一家头部机器人公司玩起了开源!
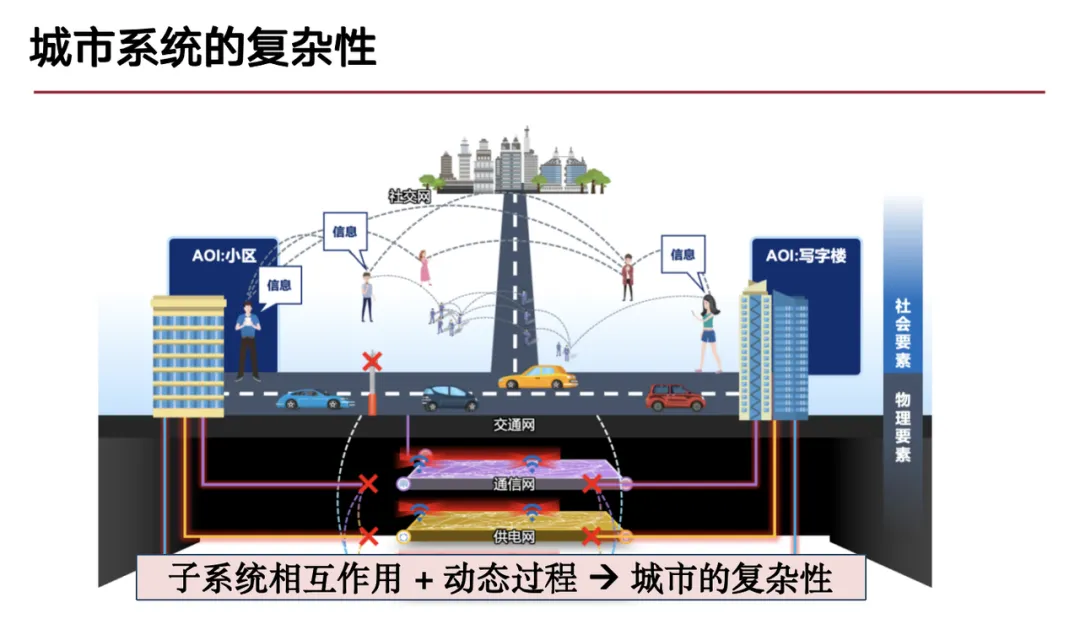
在 HyperAI超神经联合出品的 COSCon’24 AI for Science 论坛中,来自清华大学电子工程系城市科学与计算研究中心的博士后研究员丁璟韬带来了深度分享,以下为演讲精华实录。

最近,来自上海大学、山东大学和埃默里大学等机构的研究人员首次提出了文本边图的数据集与基准,包括9个覆盖4个领域的大规模文本边图数据集,以及一套标准化的文本边图研究范式。该研究的发表极大促进了文本边图图表示学习的研究,有利于自然语言处理与图数据挖掘领域的深度合作。
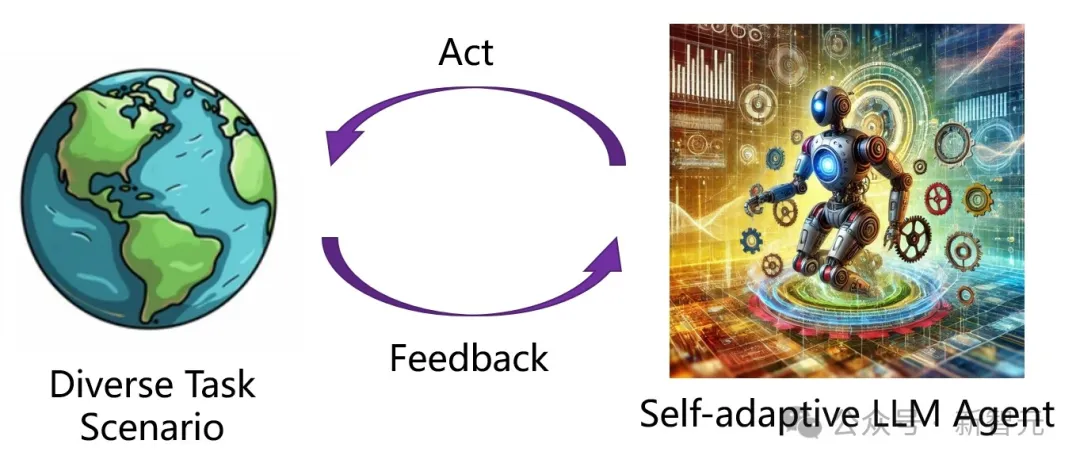
AI智能体能像有机生命一样自适应演化吗?最近清华大学团队提出了AgentSquare模块化智能体设计框架,通过标准化的模块接口抽象,让AI智能体可以通过模块演化和重组高速进化,实现针对不同任务场景的自适应演进,赋能超越人类设计的智能体系统在多种评测数据集上广泛自我涌现。

SegVG是一种新的视觉定位方法,通过将边界框注释转化为像素级分割信号来增强模型的监督信号,同时利用三重对齐模块解决特征域差异问题,提升了定位准确性。实验结果显示,SegVG在多个标准数据集上超越了现有的最佳模型,证明了其在视觉定位任务中的有效性和实用性。

Kapoor 在 2024 年 TechCrunch Disrupt 大会上启动了一场关于“新数据管道”的对话,讨论现代 AI 应用的背景,他的对话伙伴包括风险投资公司NEA的合伙人Vanessa Larco,以及数据集成平台Fivetran的首席执行官George Fraser。