
时序预测再出新范式!华东师大提出DUET:「双向聚类」新设计,性能刷新SOTA!| KDD 2025
时序预测再出新范式!华东师大提出DUET:「双向聚类」新设计,性能刷新SOTA!| KDD 2025研究团队在最新时间序列预测基准评测TFB的25个数据集上进行了广泛验证,证明了DUET的卓越性能,为各行业的时间序列预测任务提供了全新的解决方案。
来自主题: AI技术研报
7509 点击 2024-12-23 15:44
 搜索
搜索
研究团队在最新时间序列预测基准评测TFB的25个数据集上进行了广泛验证,证明了DUET的卓越性能,为各行业的时间序列预测任务提供了全新的解决方案。

只需要在手腕上戴一个腕带,就能够实现隔空打字。Meta近期推出的开源表面肌电图(sEMG)数据集,可进行姿态估计和表面类型识别,推动神经运动接口发展。
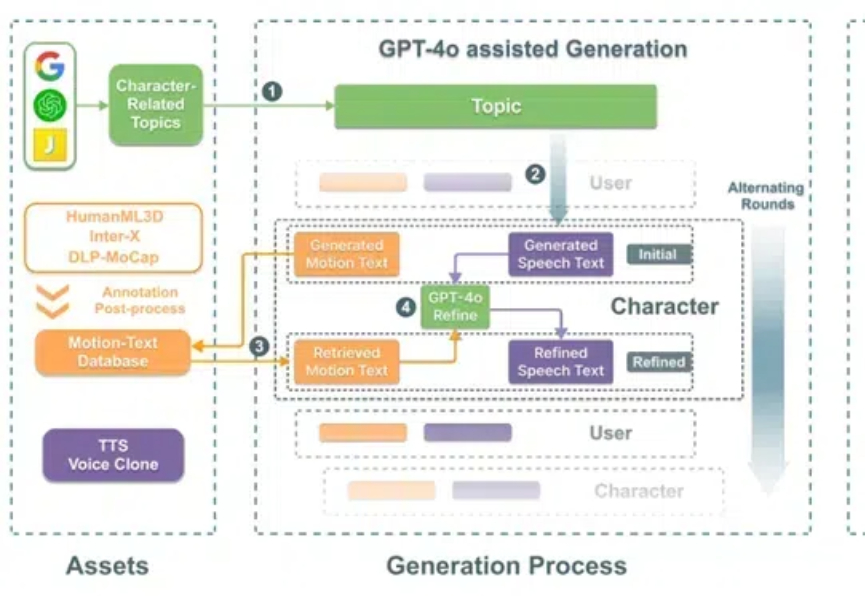
SOLAMI是一个创新的VR端3D角色扮演AI系统,用户可以通过语音和肢体语言与虚拟角色进行沉浸式互动。该系统利用先进的社交视觉-语言-行为模型,结合合成的数据集,提供更自然的交流体验,超越了传统的文本和语音交互。
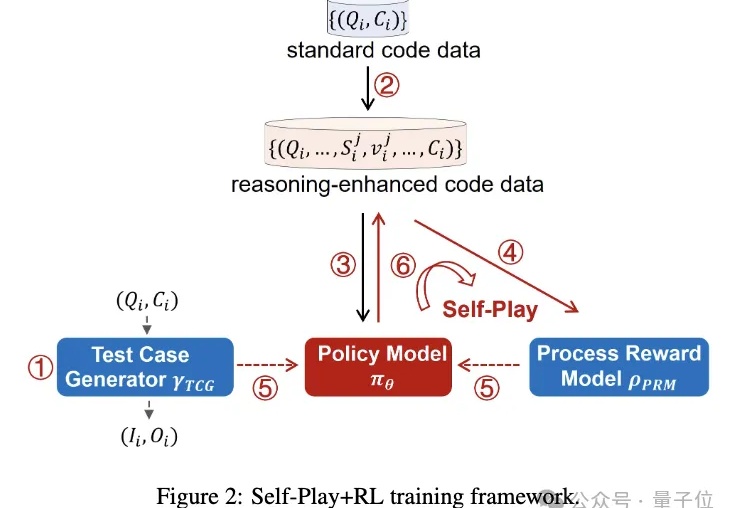
北京交通大学研究团队悄默声推出了一版o1,而且所有源代码、精选数据集以及衍生模型都开源!
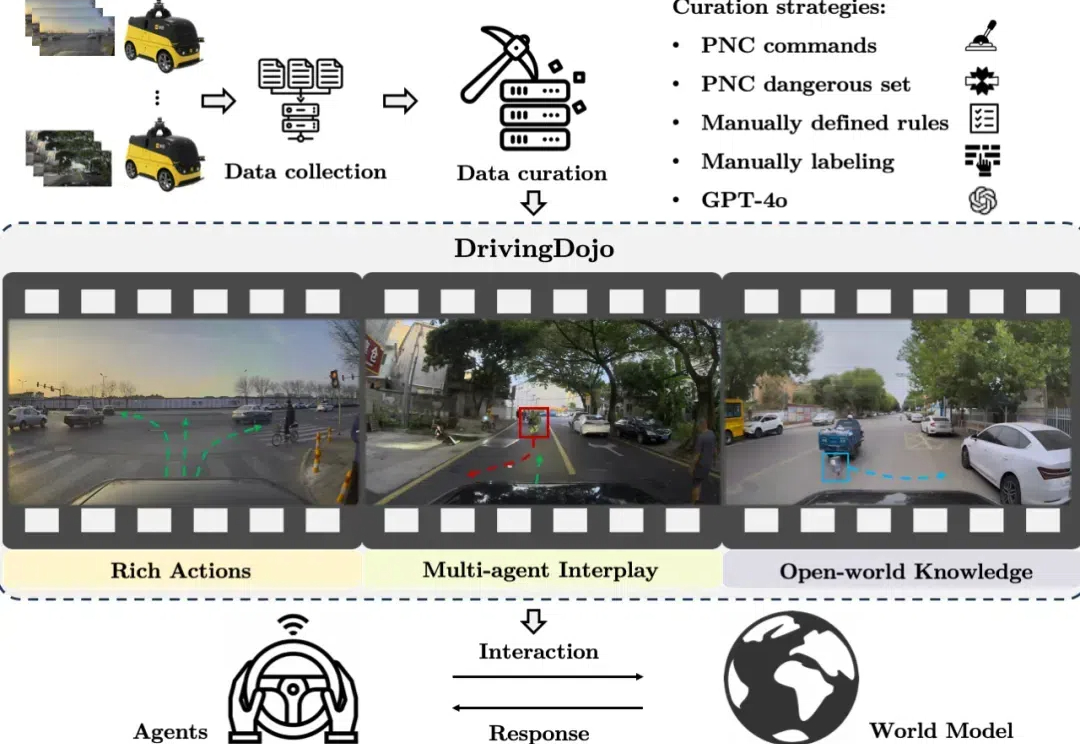
在自动驾驶领域,世界模型的应用尤为引人注目。然而,现有数据集在视频多样性和行为复杂性方面的不足,限制了世界模型潜力的全面发挥。为了解决这一瓶颈,中国科学院自动化研究所联合美团无人车团队推出了 DrivingDojo 数据集 —— 全球规模最大、专为自动驾驶世界模型研究设计的高质量视频数据集。该数据集已被 NeurIPS 2024 的 Dataset Track 接收。

斯坦福大学推出的IKEA Video Manuals数据集,通过4D对齐组装视频和说明书,为AI理解和执行复杂空间任务提供了新的挑战和研究基准,让机器人或AR眼镜指导家具组装不再是梦。

这是一个不容小觑的最新推理框架,它解耦了LLM的记忆与推理,用此框架Fine-tuned过的LLaMa-3.1-8B在TruthfulQA数据集上首次超越了GPT-4o。

斯坦福吴佳俊团队,给机器人设计了一套组装宜家家具的视频教程!
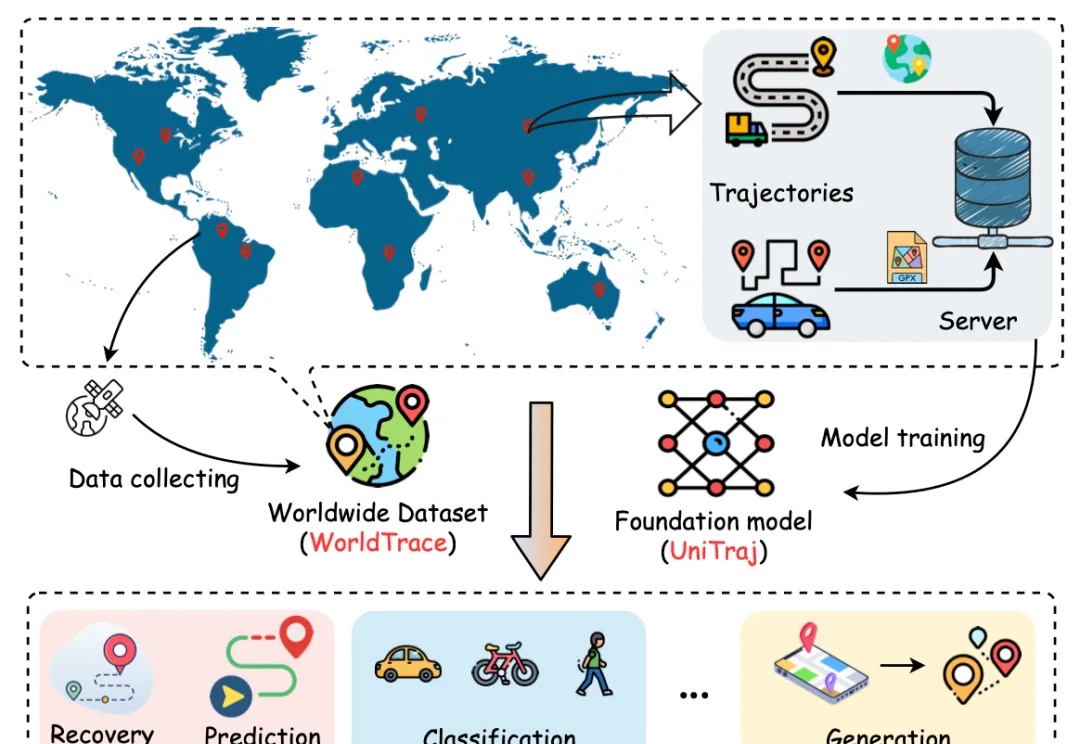
在智慧城市和大数据时代背景下,人类轨迹数据的分析对于交通优化、城市管理、物流配送等关键领域具有重要意义。然而,现有的轨迹相关模型往往受限于特定任务、区域依赖、轨迹数据规模和多样性困乏等问题,限制了模型的泛化能力和实际应用范围。

最近,Jim Fan参与的一项研究推出了自动化数据生成系统DexMimicGen。该系统可基于少量人类演示,合成类人机器人的灵巧手运动轨迹,解决了训练数据集的获取难题,而且还提升了实验中机器人的表现。