大模型合成数据机理分析,人大刘勇团队:信息增益影响泛化能力
大模型合成数据机理分析,人大刘勇团队:信息增益影响泛化能力在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。
来自主题: AI技术研报
8299 点击 2024-10-15 18:38
 搜索
搜索
在大语言模型(LLMs)后训练任务中,由于高质量的特定领域数据十分稀缺,合成数据已成为重要资源。虽然已有多种方法被用于生成合成数据,但合成数据的理论理解仍存在缺口。为了解决这一问题,本文首先对当前流行的合成数据生成过程进行了数学建模。

LightRAG通过双层检索范式和基于图的索引策略提高了信息检索的全面性和效率,同时具备对新数据快速适应的能力。在多个数据集上的实验表明,LightRAG在检索准确性和响应多样性方面均优于现有的基线模型,并且在资源消耗和动态环境适应性方面表现更优,使其在实际应用中更为有效和经济。

经过三年的努力,ImageNet成为了一个包含1500万张互联网图像的数据集,涵盖了22000个物体类别概念。

传统的歌声任务,如歌声合成,大多是在利用输入的歌词和乐谱生成高质量的歌声。随着深度学习的发展,人们希望实现可控和能个性化定制的歌声生成。

美司法部考虑强制谷歌拆分,解决垄断问题。

这样一套组合拳打下去,AI厂商大概率就会乖乖向网站付费了。
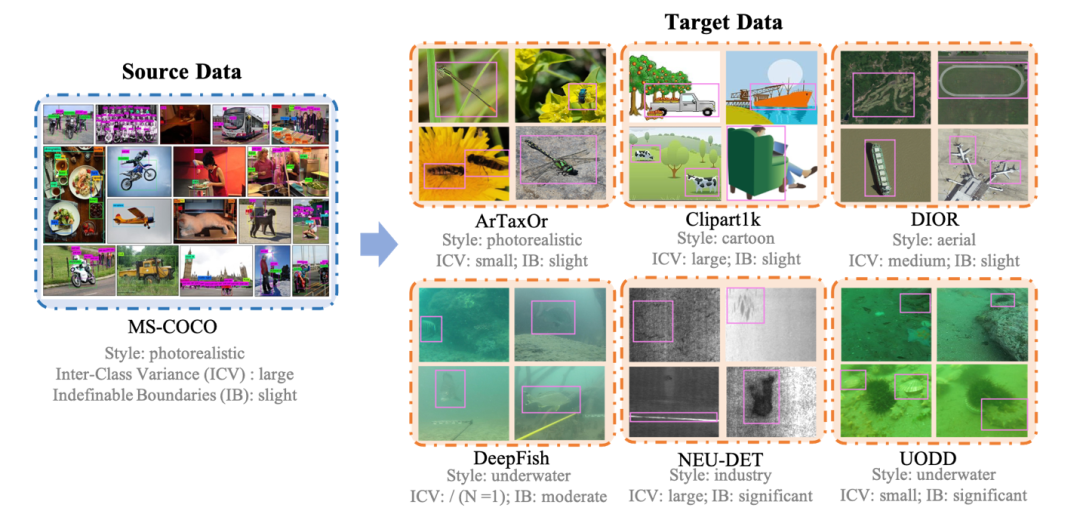
解决跨域小样本物体检测问题,入选ECCV 2024。

中科大成果,拿下图学习“世界杯”单项冠军! 由中科大王杰教授团队(MIRA Lab)提出的首个具有最优性保证的大语言模型和图神经网络分离训练框架,在国际顶级图学习标准OGB(Open Graph Benchmark)挑战赛的蛋白质功能预测任务上斩获「第一名」,该纪录从2023年9月27日起保持至今。
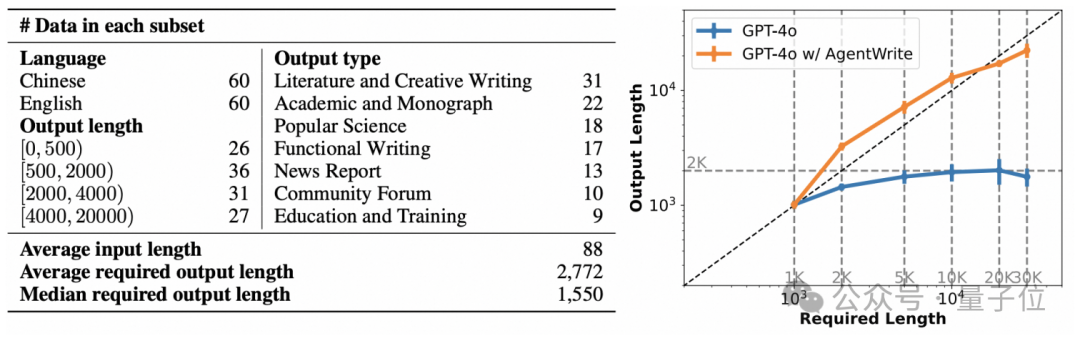
仅需600多条数据,就能训练自己的长输出模型了?!

最近看到这么一则与AI密切相关的新闻,一家标准的AI创业公司,和传统的老牌影视公司走到了一起,牵手合作,觉得意义重大,和大家做一个分享。