
百亿真实数据,首个面向AI Infra的运维智能体评测基准正式开源
百亿真实数据,首个面向AI Infra的运维智能体评测基准正式开源随着全球智能体加速落地,算力需求呈指数级爆发,以 GPU 为核心的 AI 基础设施正变得愈发关键。据摩根士丹利报告预测,2028 年全球 AI 基础设施累计总投资将达 2.9 万亿美元。
来自主题: AI技术研报
5718 点击 2026-06-30 09:53
 搜索
搜索
随着全球智能体加速落地,算力需求呈指数级爆发,以 GPU 为核心的 AI 基础设施正变得愈发关键。据摩根士丹利报告预测,2028 年全球 AI 基础设施累计总投资将达 2.9 万亿美元。
独家获悉,被称为“最像特斯拉”的具身智能公司智平方近日已完成新一轮融资,总额近50亿元人民币,估值突破200亿。据了解,本轮投资方阵容横跨国家队、大湾区产业资本、保险公司、头部券商及多家特斯拉供应链企业。公开数据显示,智平方此轮融资是迄今国内具身智能赛道单次披露金额最大的融资之一。
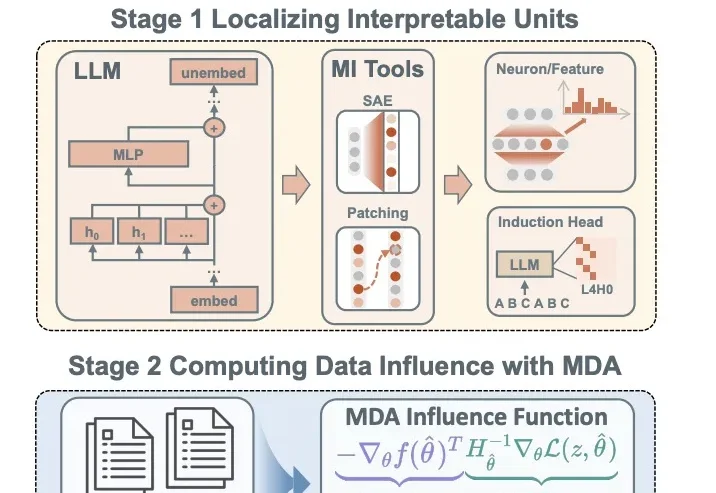
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。

这篇来自 Interlatent(一家聚焦具身智能后训练与部署的早期创业公司) 的文章,试图从第一性原理出发,把现代 AI 机器人技术重新讲清楚:一个机器人到底如何理解世界,如何生成动作,又为什么会在数据、延迟和泛化上遇到如此多的困难。
清华系物理AI企业「清研精准」已于近日完成数亿元B3轮融资,本轮融资由北京市绿色能源基金、北汽产投领投,裕隆集团跟投。据悉,该轮资金将会用于核心人才招募、多模态数采设备的研发与规模化部署,以及算力采购与模型训练基础设施建设等方向。

就在最近,英国前首相府数据科学家Liam Wilkinson,花一个周末搭了76个MCP工具,把Claude、GPT、Gemini等四个顶尖模型扔进了《文明VI》。结果,23场对局打完,其中一个AI造了核弹炸了法国——然后输了。
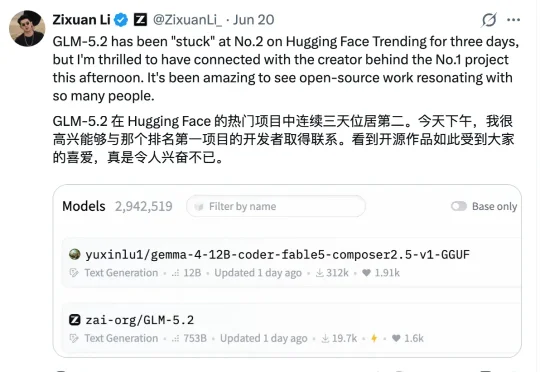
一位个人开发者,竟然在一众大厂中,杀进了抱抱脸Models Trending榜的前排?!突然出现了一个个人账号:yuxinlu1。再一看下载量——最新数据已高达20.7万和53.6万。好家伙,这是什么神仙模型来了?
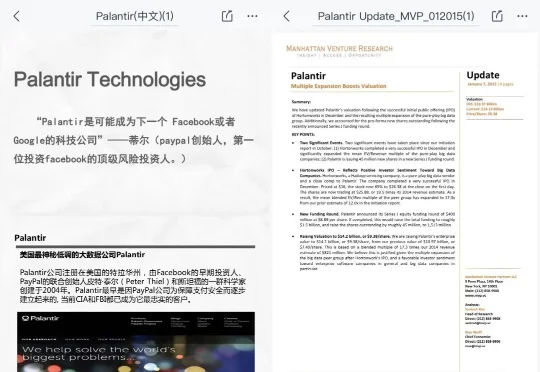
一直很奇怪为什么那么多人追崇Palantir这家公司。中国不会有Palantir,在美国它也是非常特殊的存在。这个公司不是近几年才火的,十年前投资行业追大数据概念的时候就已经很火了,当时同事还给我传过它的BP资料,当然我们国企不会去跟进这种海外项目。这十年间,国内拿Palantir作为对标、讲故事的大数据公司一抓一大把,但跟它做一样事情的大数据公司一个都没有。

来自 Sharpa、清华大学、UC Berkeley、上海交通大学、ETH Zurich 等机构的研究者提出了首个通用触觉基础策略 FTP-1。它基于约 3,000 小时、来自 26 个数据来源和 21 种触觉传感器的数据进行预训练

看《堡垒之夜》的游戏录像,也能训练AI?没错,一家靠着海量游戏录像训练AI的公司General Intuition,刚刚完成3.2亿美元(约合人民币21.77亿元)融资。General Intuition公开披露的融资总额已达4.54亿美元,估值23亿美元。