
USC团队发布HumDex:攻克人形机器人数据瓶颈,低成本实现全身灵巧操控
USC团队发布HumDex:攻克人形机器人数据瓶颈,低成本实现全身灵巧操控人形机器人全身灵巧操作是通向通用具身智能的核心目标之一。在这一愿景下,机器人不仅需要双臂与高自由度多指灵巧手的精细协调,还需要与全身位姿(如行走、弯腰)进行动态配合。
来自主题: AI技术研报
5726 点击 2026-04-07 09:26
 搜索
搜索
人形机器人全身灵巧操作是通向通用具身智能的核心目标之一。在这一愿景下,机器人不仅需要双臂与高自由度多指灵巧手的精细协调,还需要与全身位姿(如行走、弯腰)进行动态配合。

郭亚楠说,Context就承接了新需求。传统OS让人和软件对齐,新OS应该让人和Agent对齐。因为Context是个人数据的结构化、语义化集合,它就像OS管理内存和CPU一样管理每个人的数字痕迹。

Chatbot时代结束了!Google将AI植入Android底层,让它变成一个主动规划一切的系统管家。每个月$19.99+你的全部数据,就能获得一个全天候24h的AI管家。

《读佳》获悉,腾讯近期正在开发一款AI助手产品“Vedas AI”,定位是聪明可靠的AI助手,帮用户做数据分析,写PPT,搭网页,出调研报告,还能自动跑任务。不过该产品还未对外公开使用。 从产品的描述
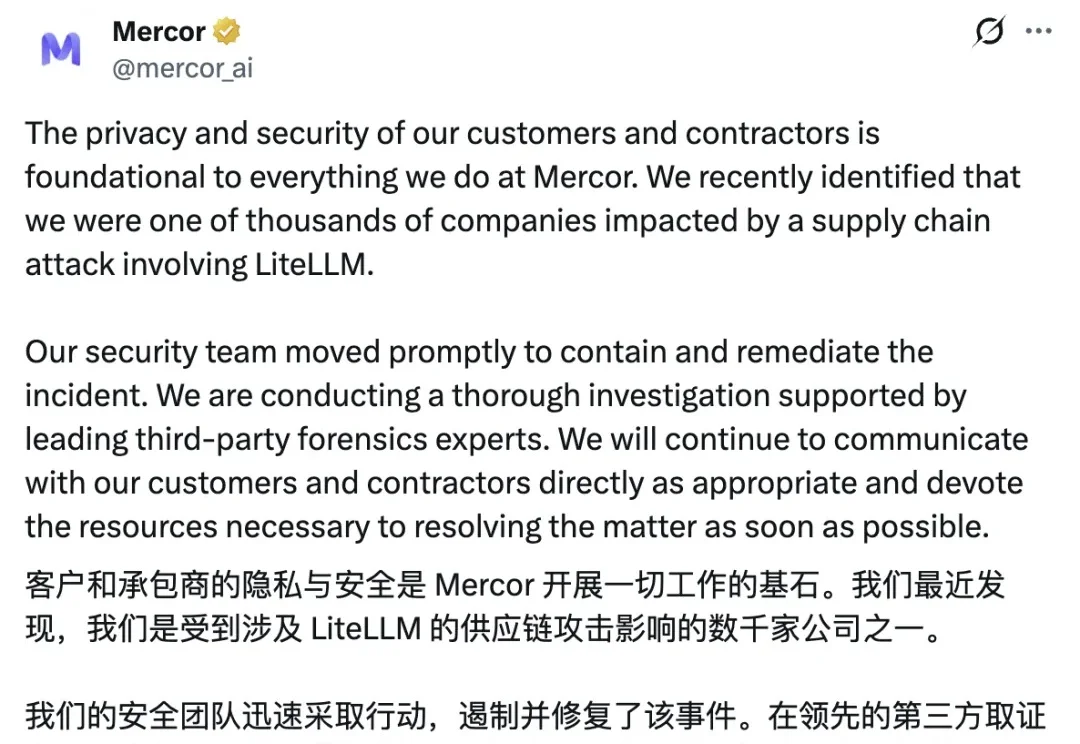
Anthropic 的 Claude Code 源代码泄漏事件余波未平,另一场事故又接踵而至了。
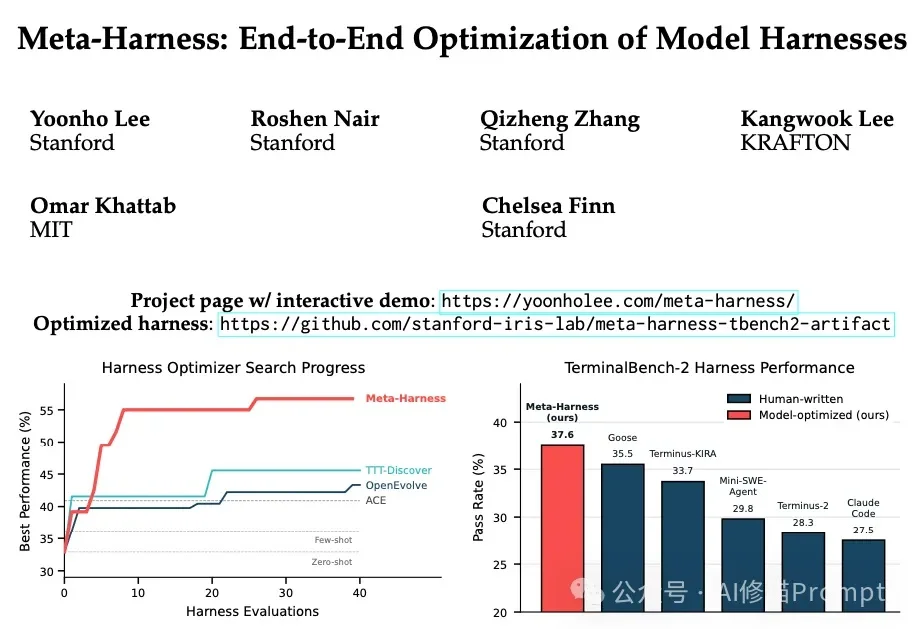
去年讨论Agent落地时,重点往往是Context Engineering。大家都在琢磨怎么放 Few-shot,怎么优化 RAG 检索的文本片段。但随着 Agent 任务复杂度的上升,控制数据流向、工具调度和异常处理的底层脚手架代码,往往比单纯拼接文本对系统性能的影响更大。
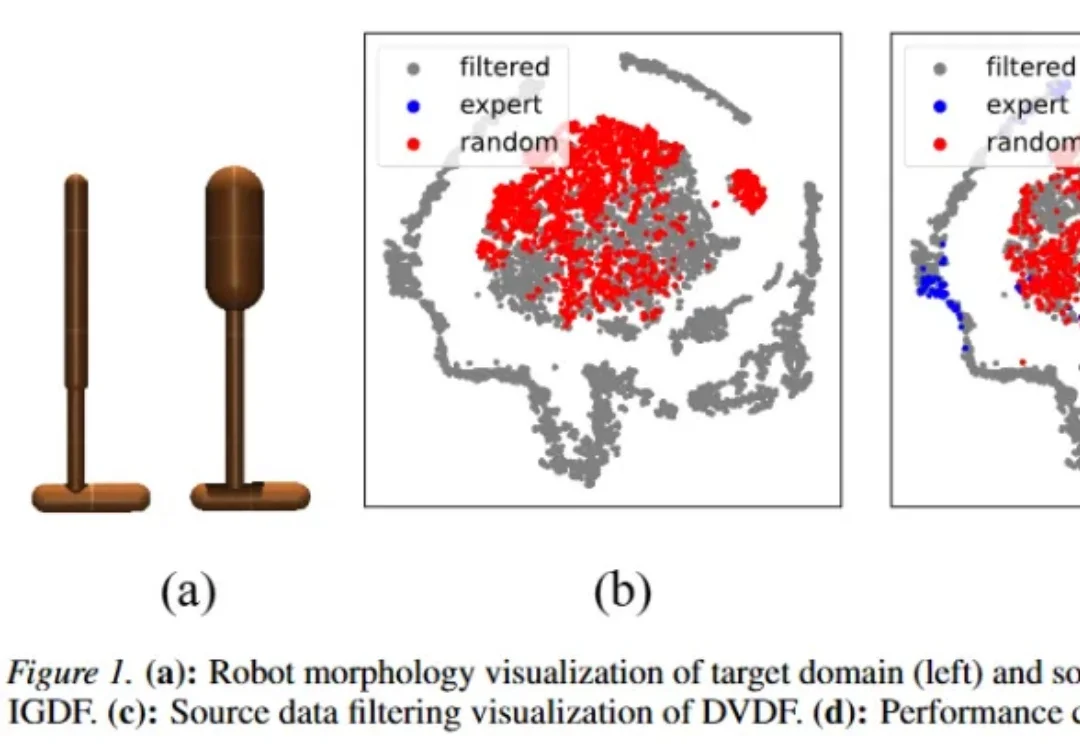
在现实世界中通过强化学习训练智能体,往往需要大量在线试错与环境探索,这不仅成本高昂,还可能带来显著安全风险:机器人可能因试错而损坏,自动驾驶的在线探索可能危及行车安全,而持续采集交互数据本身也代价巨大。
就在这个节骨眼上,我发现了一个非常有意思的东西,科大讯飞在 GitHub 上开源了一个叫 SkillHub 的项目。简单说,SkillHub 就是一个可以私有化部署的 Skill 技能包管理平台,团队可以在自己服务器上搭建,数据完全掌握在自己手上。

相似度超越Seed-TTS、MiniMax-Speech等知名模型。昨晚,美团LongCat团队发布了文本转语音模型LongCat-AudioDiT,并开源1B、3.5B参数量的版本。这一模型的最大特点,是彻底抛弃了梅尔谱等中间表示,直接在波形潜空间进行基于扩散模型的文本转语音。通俗地说,这一模型直接根据声音本身的规律进行生成,“雕刻”出最原始的声音波形,从根源阻断数据转换的级联误差。

3月30日,阿里巴巴内部发布了 Wan2.7-Image 图像生成与编辑统一模型。根据官方公布的数据,在人类偏好盲测评分中,Wan2.7-Image 目前位列国内第一。从放出的评测雷达图来看,无论是文本生图(Text-to-Image)还是综合图像编辑(Image Editing),它的各项指标基本都盖过了市面上主流的几家头部模型。