
深夜突袭,DeepSeek-Prover-V2加冕数学王者!671B数学推理逆天狂飙
深夜突袭,DeepSeek-Prover-V2加冕数学王者!671B数学推理逆天狂飙就在刚刚,DeepSeek-Prover-V2技术报告也来了!34页论文揭秘了模型的训练核心——递归+强化学习,让数学推理大提升。有人盛赞:DeepSeek已找到通往AGI的正确路径!
来自主题: AI资讯
9981 点击 2025-05-01 10:49
 搜索
搜索
就在刚刚,DeepSeek-Prover-V2技术报告也来了!34页论文揭秘了模型的训练核心——递归+强化学习,让数学推理大提升。有人盛赞:DeepSeek已找到通往AGI的正确路径!
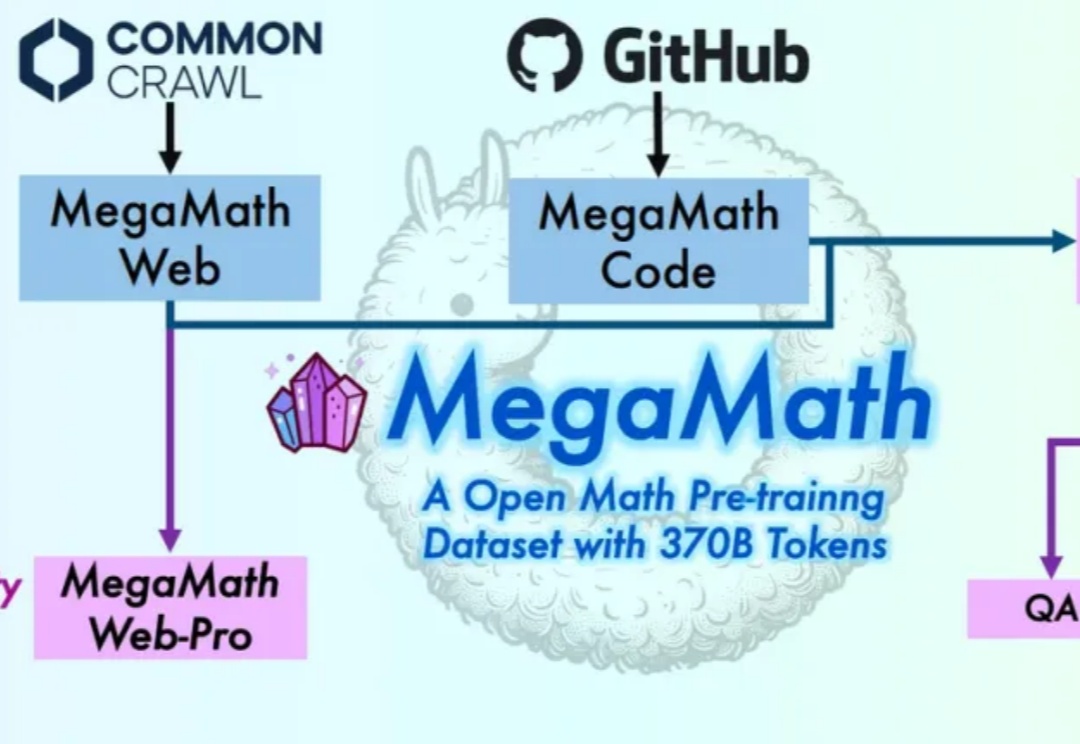
在大模型迈向推理时代的当下,数学推理能力已成为衡量语言模型智能上限的关键指标。
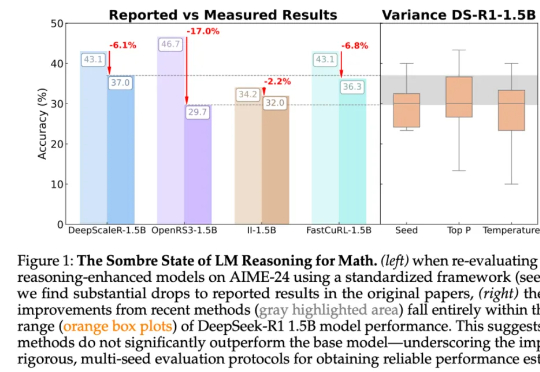
尽管这些论文的结论统统指向了强化学习带来的显著性能提升,但来自图宾根大学和剑桥大学的研究者发现,强化学习导致的许多「改进」可能只是噪音。「受推理领域越来越多不一致的经验说法的推动,我们对推理基准的现状进行了严格的调查,特别关注了数学推理领域评估算法进展最广泛使用的测试平台之一 HuggingFaceH4,2024;AI - MO。」
在数学推理中,大语言模型存在根本性局限:在美国数学奥赛,顶级AI模型得分不足5%!来自ETH Zurich等机构的MathArena团队,一下子推翻了AI会做数学题这个神话。

685B的DeepSeek-V3新版本,就在昨夜悄悄上线了。参数量685B的V3,代码数学推理再次显著提升,甚至代码追平Claude 3.7,网友们实测后大呼强到离谱!有人预测说,按照此前的节奏,DeepSeek-R2大概率几周内就将上线。
就在DeepSeek-V3更新的同一夜,阿里通义千问Qwen又双叒叕一次梦幻联动了——

多模态大模型虽然在视觉理解方面表现出色,但在需要深度数学推理的任务上往往力不从心,尤其是对于参数量较小的模型来说更是如此。
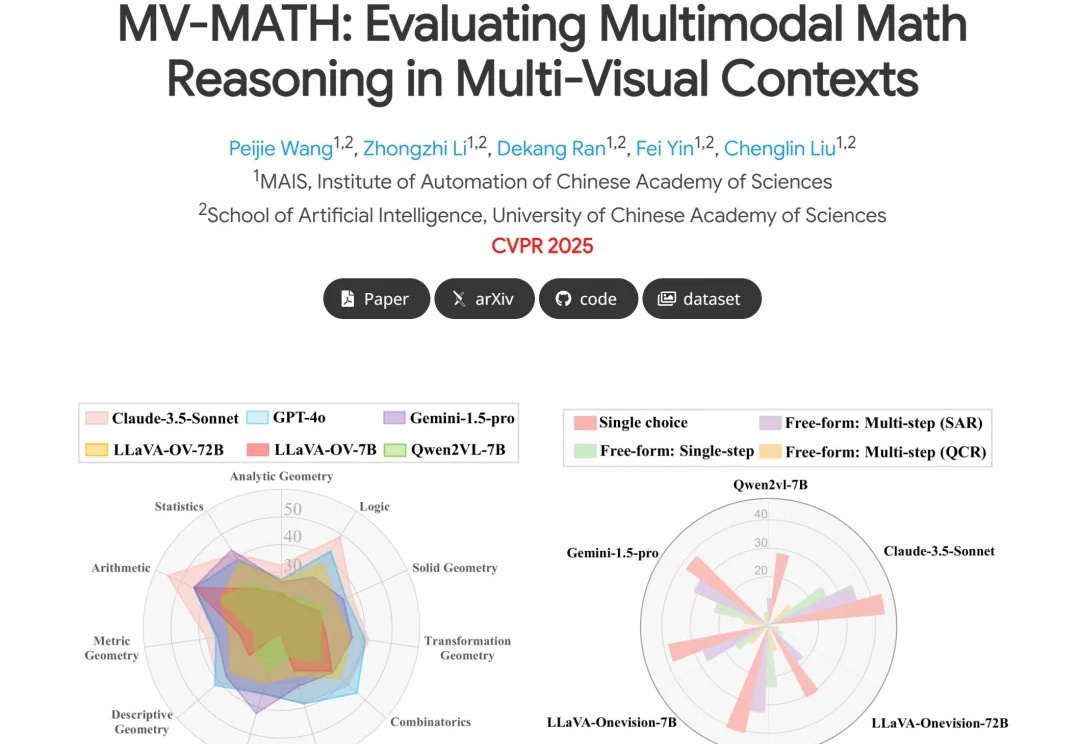
挑战多图数学推理新基准,大模型直接全军覆没?!

CMU团队用LCPO训练了一个15亿参数的L1模型,结果令人震惊:在数学推理任务中,它比S1相对提升100%以上,在逻辑推理和MMLU等非训练任务上也能稳定发挥。更厉害的是,要求短推理时,甚至击败了GPT-4o——用的还是相同的token预算!
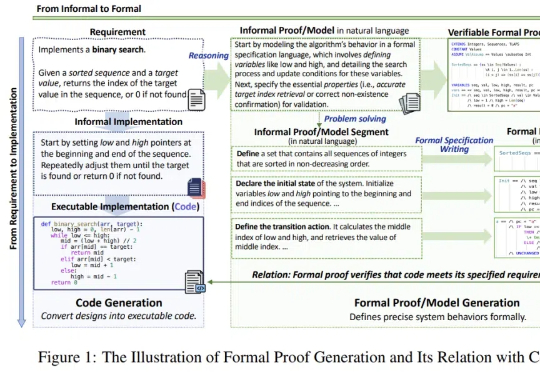
随着 DeepSeek-R1 的流行与 AI4Math 研究的深入,大模型在辅助形式化证明写作方面的需求日益增长。作为数学推理最直接的应用场景,形式化推理与验证(formal reasoning and verification),也获得持续关注。