4B小模型数学推理首超Claude 4,700步RL训练逼近235B性能 | 港大&字节Seed&复旦
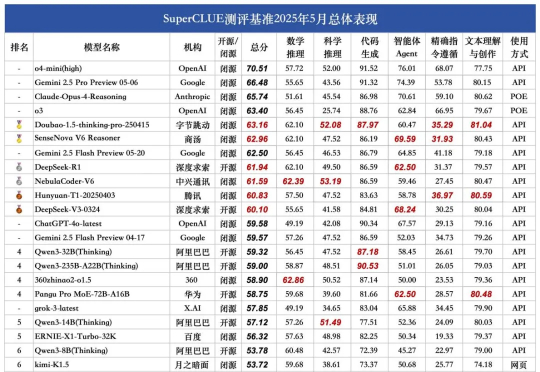
4B小模型数学推理首超Claude 4,700步RL训练逼近235B性能 | 港大&字节Seed&复旦香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。
来自主题: AI资讯
8083 点击 2025-07-09 12:10