链式思维是幻象吗?从数据分布视角重新审视大模型推理,马斯克回复,Grok破防
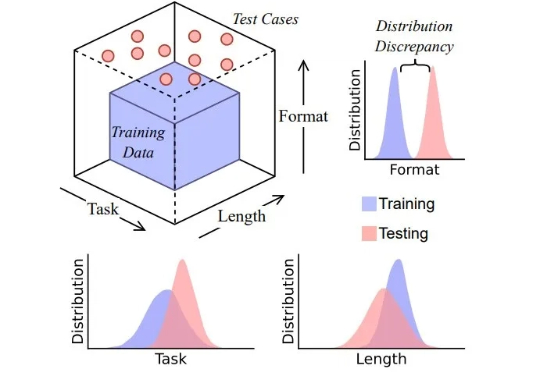
链式思维是幻象吗?从数据分布视角重新审视大模型推理,马斯克回复,Grok破防思维链 (CoT) 提示技术常被认为是让大模型分步思考的关键手段,通过在输入中加入「Let’s think step by step」等提示,模型会生成类似人类的中间推理步骤,显著提升复杂任务的表现。然而,这些流畅的推理链条是否真的反映了模型的推理能力?
来自主题: AI技术研报
7641 点击 2025-08-15 12:38
 搜索
搜索
思维链 (CoT) 提示技术常被认为是让大模型分步思考的关键手段,通过在输入中加入「Let’s think step by step」等提示,模型会生成类似人类的中间推理步骤,显著提升复杂任务的表现。然而,这些流畅的推理链条是否真的反映了模型的推理能力?
当推理链从3步延伸到50+步,幻觉率暴增10倍;反思节点也束手无策。

大语言模型(LLMs)在决策场景中常因贪婪性、频率偏差和知行差距表现欠佳。研究者提出强化学习微调(RLFT),通过自我生成的推理链(CoT)优化模型,提升决策能力。实验表明,RLFT可增加模型探索性,缩小知行差距,但探索策略仍有改进空间。

GRIT能让多模态大语言模型(MLLM)通过生成自然语言和图像框坐标结合的推理链进行「图像思维」,仅需20个训练样本即可实现优越性能!

思维链(Chain of Thought, CoT)推理方法已被证明能够显著提升大语言模型(LLMs)在复杂任务中的表现。而在多模态大语言模型(MLLMs)中,CoT 同样展现出了巨大潜力。
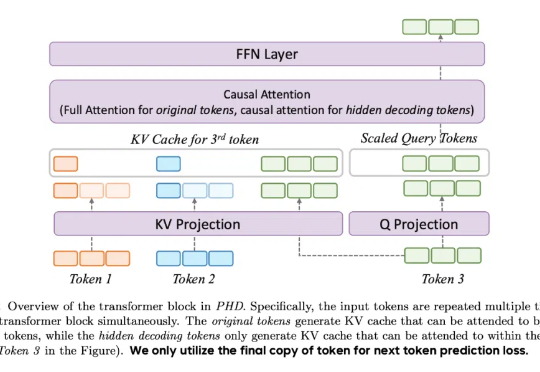
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。

DeepSeek-R1是近年来推理模型领域的一颗新星,它不仅突破了传统LLM的局限,还开启了全新的研究方向「思维链学」(Thoughtology)。这份长达142页的报告深入剖析了DeepSeek-R1的推理过程,揭示了其推理链的独特结构与优势,为未来推理模型的优化提供了重要启示。

不怕推理模型简单问题过度思考了,能动态调整CoT的新推理范式SCoT来了!