独家丨上线一个月吸引10万开发者,AnySearch要帮Agent看见网页之外的世界
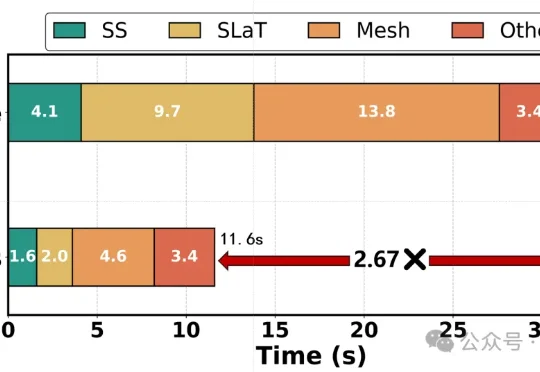
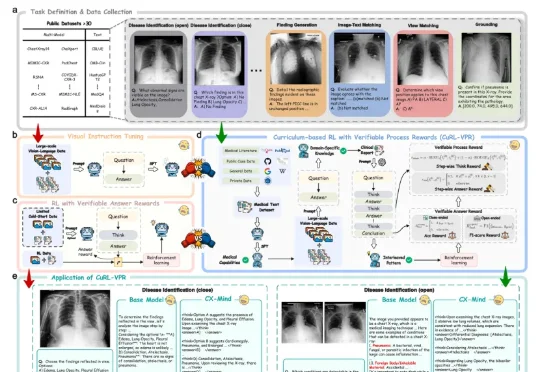
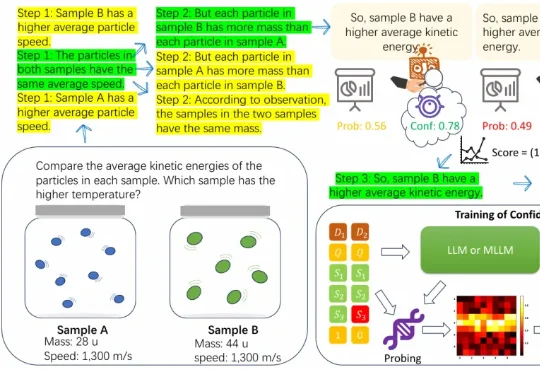
独家丨上线一个月吸引10万开发者,AnySearch要帮Agent看见网页之外的世界5 月中旬,一个名叫 anysearch-skill 的开源仓库出现在 GitHub 上,一周之内冲上了 Agent 技能市场 Skills.sh 的热榜第一。开发者们发现,给自己的 Agent 装上这个 Skill 之后,原本要搜七八轮才能拼凑完整的调研任务,常常一两次调用就能拿到结果,而且返回的不是网页链接,是可以直接进推理链路的结构化数据。
来自主题: AI资讯
8896 点击 2026-06-13 10:53