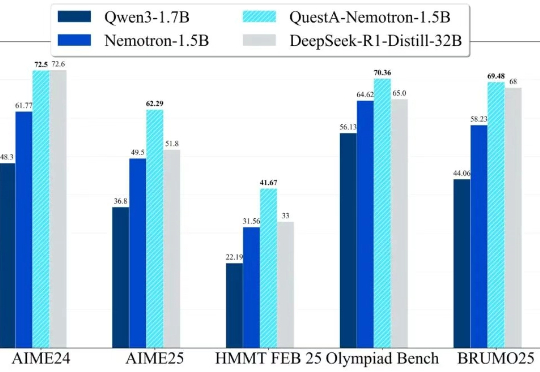
1.5B推理模型新SOTA,RL训练新解法打破「简单题过拟合、难题学不动」的魔咒
1.5B推理模型新SOTA,RL训练新解法打破「简单题过拟合、难题学不动」的魔咒QuestA(问题增强)引入了一种方法,用于提升强化学习中的推理能力。通过在训练过程中注入部分解题提示,QuestA 实现两项重大成果
来自主题: AI技术研报
9206 点击 2025-10-06 13:54
 搜索
搜索
QuestA(问题增强)引入了一种方法,用于提升强化学习中的推理能力。通过在训练过程中注入部分解题提示,QuestA 实现两项重大成果
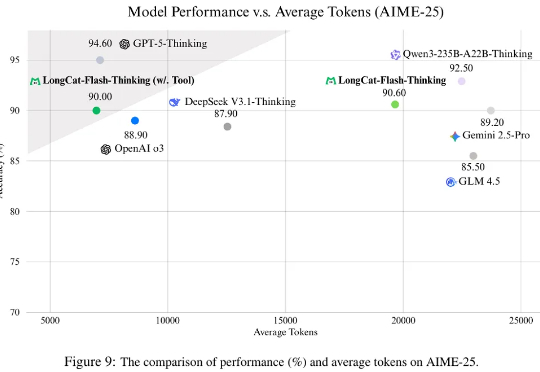
最近,美团在AI开源赛道上在猛踩加速。今天,在开源其首款大语言模型仅仅24天后,美团又开源了其首款自研推理模型LongCat-Flash-Thinking。与其基础模型LongCat-Flash类似,效率也是LongCat-Flash-Thinking的最大特点。美团在技术报告中透露,LongCat-Flash-Thinking在自研的DORA强化学习基础设施完成训练
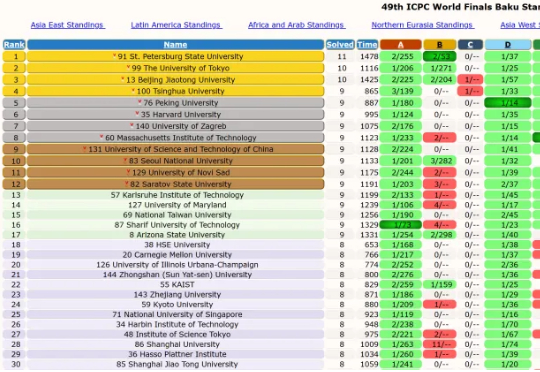
ICPC 2025全球总决赛诞生历史性一幕:谷歌Gemini与OpenAI推理模型同时斩获金牌!Gemini在5小时内攻下12题中的10题,并在30分钟破解难倒所有人类的死亡C题;而OpenAI更是满分12/12,碾压139支人类队伍,成为赛场唯一全解团队。

上周,福布斯、Wired等争相报道「全球最快开源推理模型」K2-Think,,甚至图灵奖得主Yann LeCun转发推文。但仅三天后,ETH五位研究员的博客如晴天霹雳:87数学评估题竟藏在训练集中!这不仅仅是技术突破,更是行业诚信的警钟。
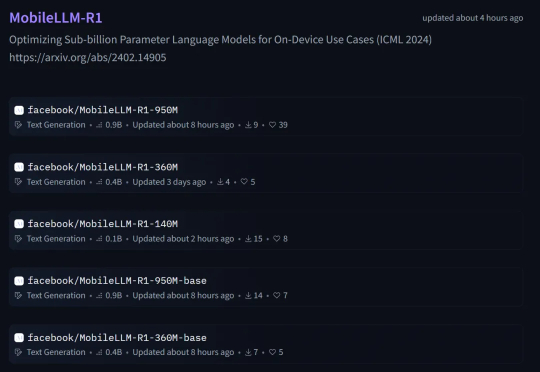
本周五,Meta AI 团队正式发布了 MobileLLM-R1。 这是 MobileLLM 的全新高效推理模型系列,包含两类模型:基础模型 MobileLLM-R1-140M-base、MobileLLM-R1-360M-base、MobileLLM-R1-950M-base 和它们相应的最终模型版。
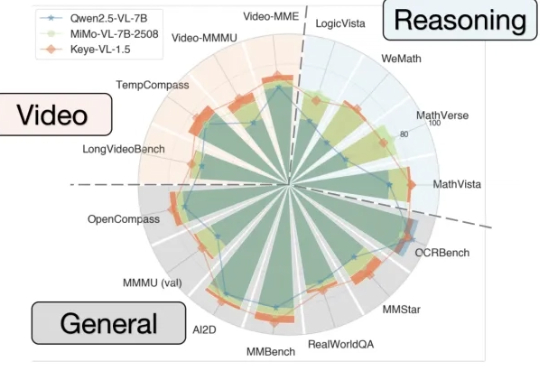
能看懂视频并进行跨模态推理的大模型Keye-VL 1.5,快手开源了。
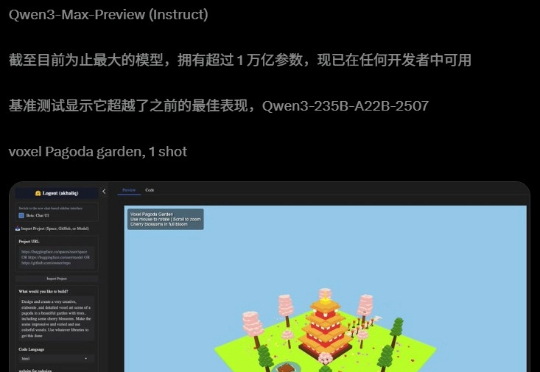
阿里迄今为止,参数最大的模型诞生了!昨夜,Qwen3-Max-Preview(Instruct)官宣上线,超1万亿参数性能爆表。在全球主流权威基准测试中,Qwen3-Max-Preview狂揽非推理模型「C」位,直接碾压Claude-Opus 4(Non-Thinking)、Kimi-K2、DeepSeek-V3.1。
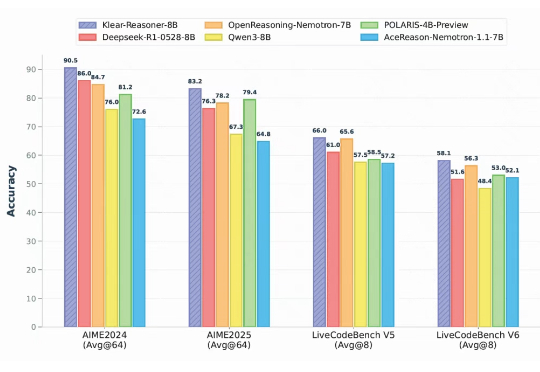
在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。
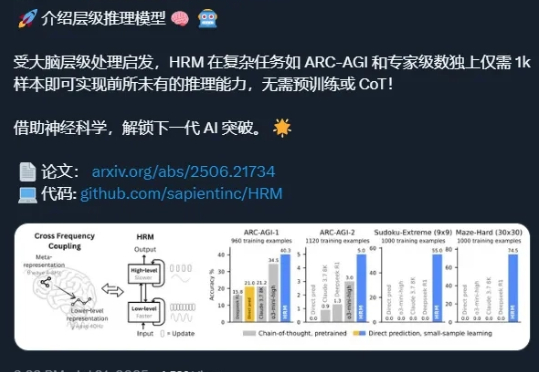
还记得分层推理模型(Hierarchical Reasoning Model,HRM)吗? 这项工作于 6 月份发布,当时引起了不小的轰动——X/Twitter 上的相关讨论获得了超过 400 万的浏览量和数万个点赞,剖析这项工作的 YouTube 视频观看量也超过了 47.5 万次。
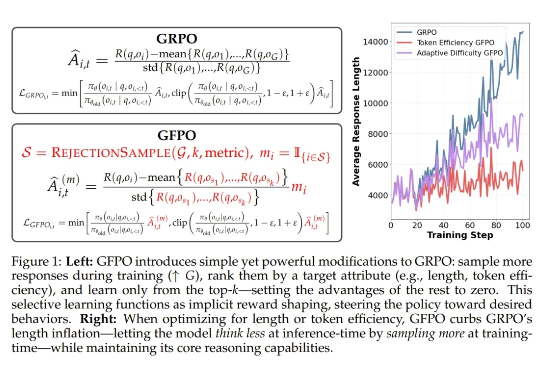
用过 DeepSeek-R1 等推理模型的人,大概都遇到过这种情况:一个稍微棘手的问题,模型像陷入沉思一样长篇大论地推下去,耗时耗算力,结果却未必靠谱。现在,我们或许有了解决方案。