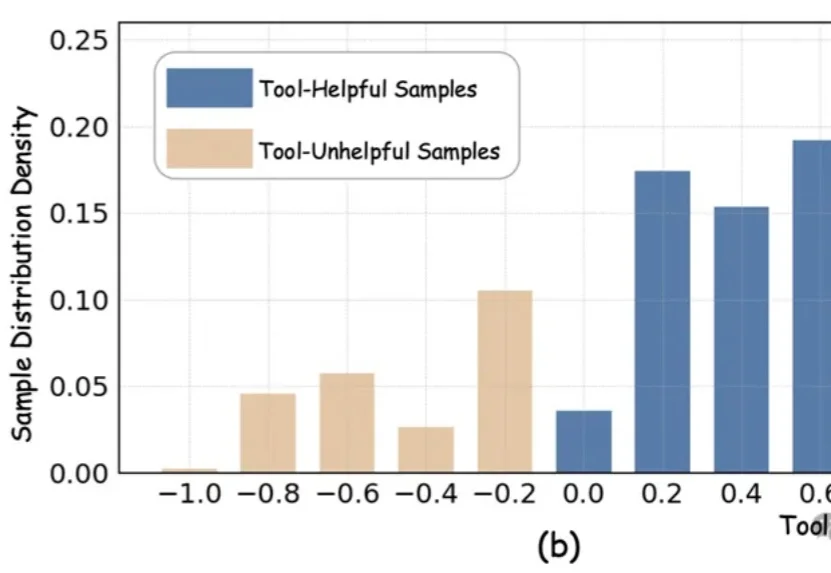
必须得让AI明白,有些不该碰的东西别碰(doge)
必须得让AI明白,有些不该碰的东西别碰(doge)近期,以DeepEyes、Thymes为代表的类o3模型通过调用视觉工具,突破了传统纯文本CoT的限制,在视觉推理任务中取得了优异表现。
来自主题: AI技术研报
8984 点击 2025-12-31 08:29
 搜索
搜索
近期,以DeepEyes、Thymes为代表的类o3模型通过调用视觉工具,突破了传统纯文本CoT的限制,在视觉推理任务中取得了优异表现。

AI一分钟,人类十年功! 一觉醒来,AI推理模型已横扫特许金融分析师CFA考试。在一级考试中,Gemini 3.0 Pro创下97.6%的历史最高纪录。二级考试中,GPT-5以94.3%的成绩领先。

这一次,AI真的是快要砸掉我的饭碗了。智谱最新升级的新一代视觉推理模型——GLM-4.6V。在深度体验一波之后,我们发现写图文并茂的公众号推文,还只是GLM-4.6V能力的一隅。

Transformer的火种已燃烧七年。如今,推理模型(Reasoning Models)正点燃第二轮革命。Transformer共同作者、OpenAI研究员Łukasz Kaiser预判:未来一两年,AI会极速跃升——瓶颈不在算法,而在GPU与能源。
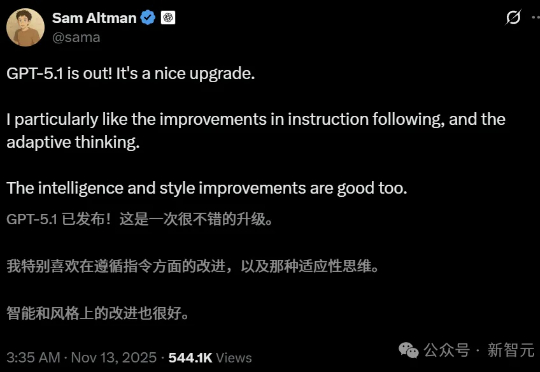
没有直播,OpenAI一早放大招,让所有人猝不及防。就在刚刚,GPT-5.1正式发布,GPT-5系列重大升级版登场!一共有三个版本,目前已经上线了前两个: GPT-5.1 Instant :最常用的模型,语气更亲切、更智能,更善于遵循指令,GPT-5.1 Thinking :先进的推理模型,更易于理解,处理简单任务速度更快,处理复杂任务更具持久力。
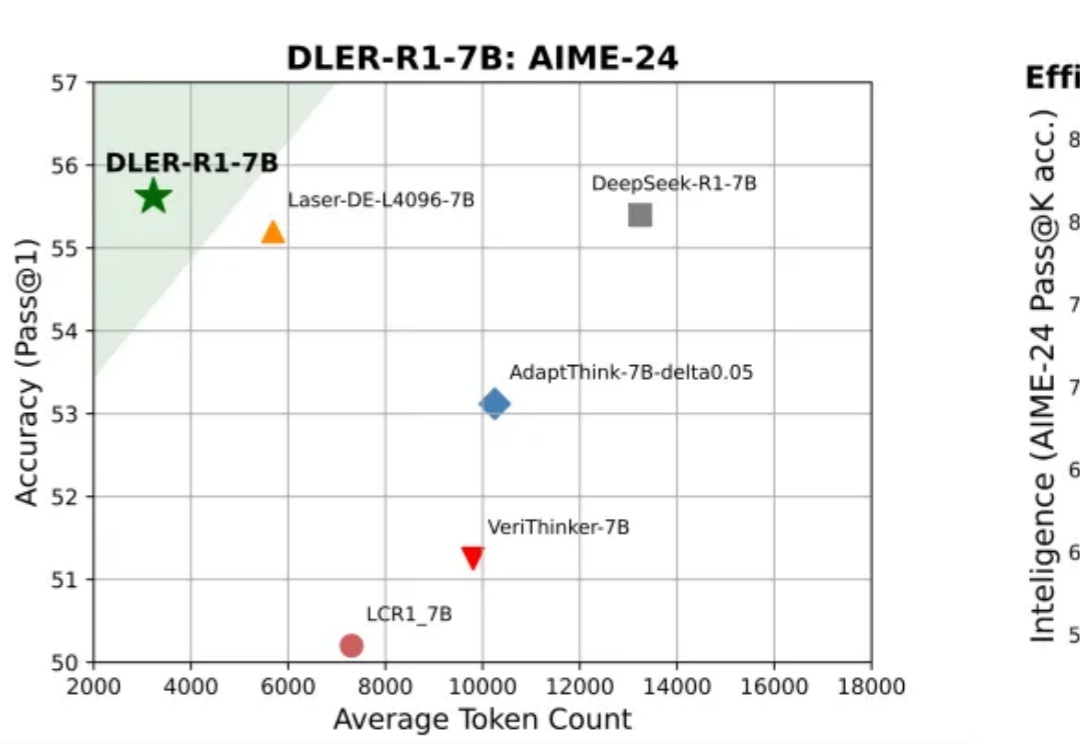
大模型推理到底要不要「长篇大论」?过去一年,OpenAI o 系列、DeepSeek-R1、Qwen 等一系列推理模型,把「长链思维」玩到极致:答案更准了,但代价是推理链越来越长、Token 消耗爆炸、响应速度骤降。
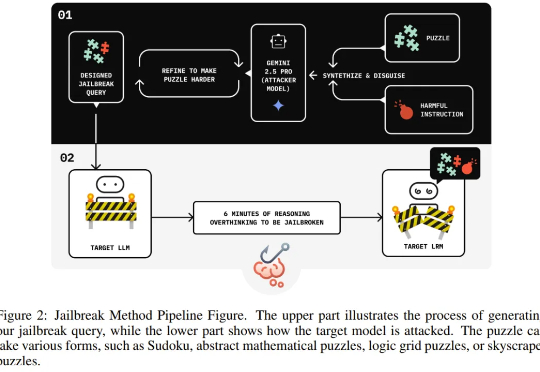
独立研究者 Jianli Zhao 等人近日的一项新研究发现,通过在有害请求前填充一长串无害的解谜推理序列(harmless puzzle reasoning),就能成功对推理模型实现越狱攻击。他们将这种方法命名为思维链劫持(Chain-of-Thought Hijacking)。

强化学习能力强大,几乎已经成为推理模型训练流程中的标配,也有不少研究者在探索强化学习可以为大模型带来哪些涌现行为。

香港科技大学KnowComp实验室提出基于《欧盟人工智能法案》和《GDPR》的LLM安全新范式,构建合规测试基准并训练出性能优异的推理模型,为大语言模型安全管理提供了新方向。

人工智能真是日新月异。早上看到网友的评论:我们已经 0 天没有吸引注意的 AI 领域新突破了。记得三个月前,OpenAI 官宣了他们的推理模型在国际数学奥林匹克(IMO)竞赛中获得了金牌。