OpenAI没开源的gpt-oss基础模型,他去掉强化学习逆转出来了
OpenAI没开源的gpt-oss基础模型,他去掉强化学习逆转出来了前些天,OpenAI 少见地 Open 了一回,发布了两个推理模型 gpt-oss-120b 和 gpt-oss-20b。
来自主题: AI资讯
8159 点击 2025-08-13 18:19
 搜索
搜索
前些天,OpenAI 少见地 Open 了一回,发布了两个推理模型 gpt-oss-120b 和 gpt-oss-20b。
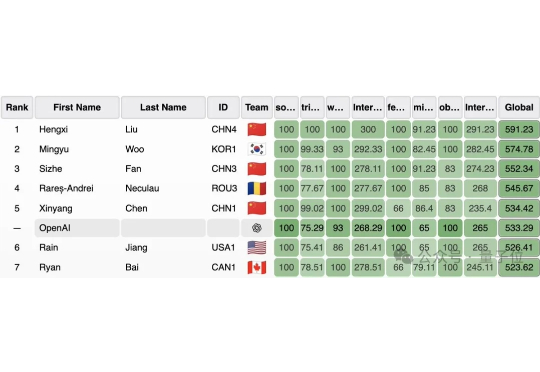
刚刚,OpenAI官宣:IOI金牌收入囊中! 其推理模型在今年IOI线上竞赛中成绩刷新纪录: 总分533.29,在全球330名人类选手中总排名位列第六;而在所有AI参赛者中,稳居第一。

一觉醒来,OpenAI 的大模型又完成了一项壮举!在全球顶级编程赛事之一 ——2025 年国际信息学奥林匹克(IOI)中,OpenAI 的推理模型取得了足以摘得金牌的高分,并在 AI 参赛者中排名第一!

智谱基于GLM-4.5打造的开源多模态视觉推理模型GLM-4.5V,在42个公开榜单中41项夺得SOTA!其功能涵盖图像、视频、文档理解、Grounding、地图定位、空间关系推理、UI转Code等。
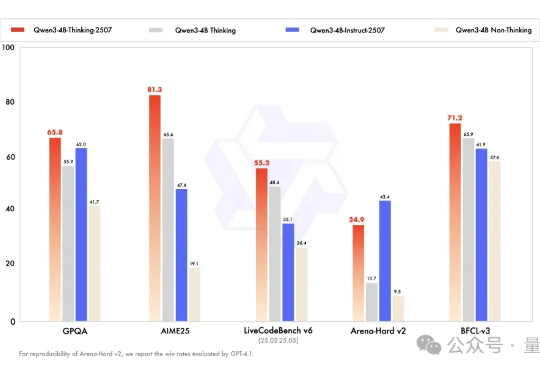
三天不开源,Qwen团队手就痒。 昨天深夜再次放出两个端侧模型: Qwen3-4B-Instruct-2507:非推理模型,大幅提升通用能力 Qwen3-4B-Thinking-2507:高级推理模型,专为专家级任务设计
你会掏钱吗?你说巧不巧,就在 Sam Altman 官宣两个开源推理模型之前的半个小时,却被 Anthropic 抢先一步,发布了新模型 Claude Opus 4.1。

GPT-5,曾经差点难产?这条诞生路,简直是烈火炼真金。一边是人才出走、小扎截胡、团队内部陷入混乱,另一边,推理模型魔咒让研究者苦恼不已,项目甚至一度停摆。外媒曝出这期GPT-5诞生内幕,可谓亮点满满,干货十足。
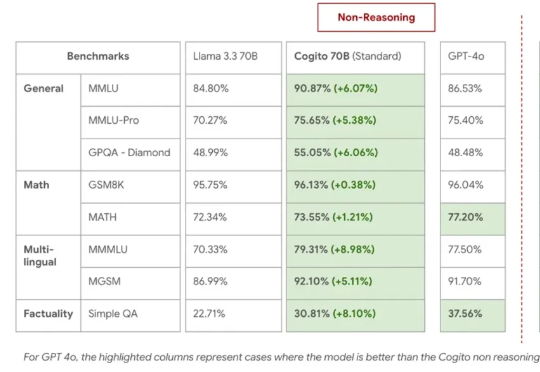
Deep Cogito,一家鲜为人知的 AI 初创公司,总部位于旧金山,由前谷歌员工创立,如今开源的四款混合推理模型,受到大家广泛关注。
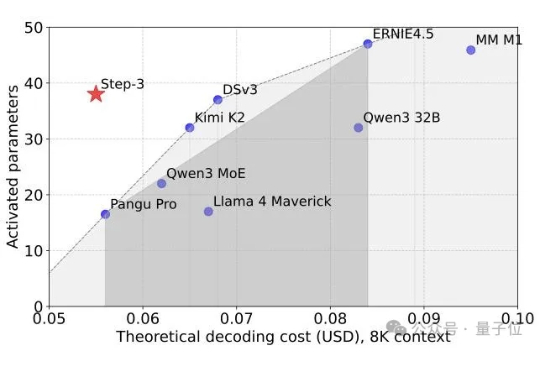
又一个SOTA基础模型开源,而且依然是国产。 刚刚,阶跃星辰兑现了WAIC上的承诺,将最新多模态推理模型Step-3正式开源! 在MMMU等多个多模态榜单上,它一现身就取得了开源多模态推理模型新SOTA的成绩。
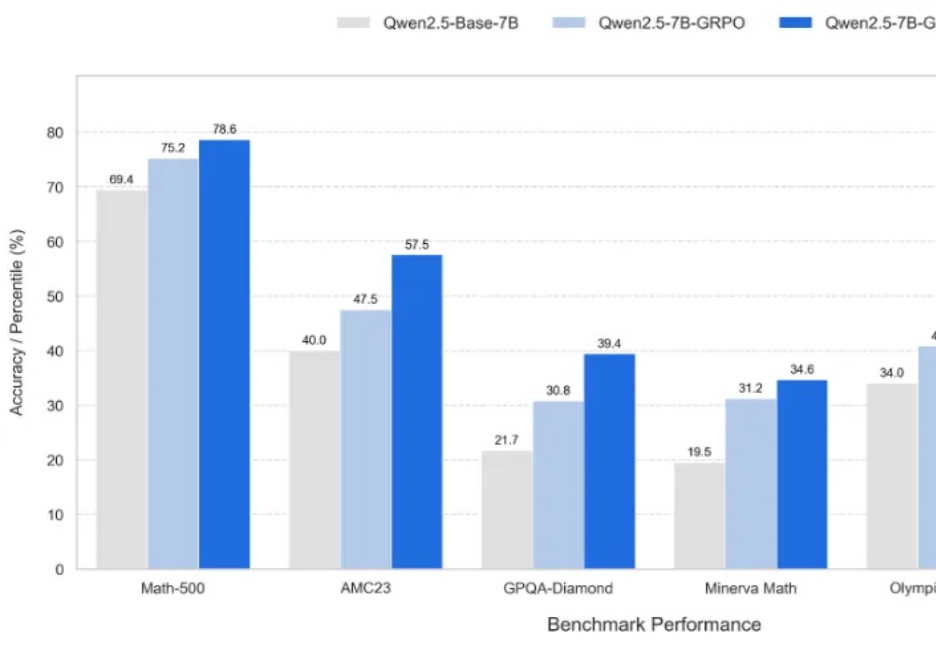
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。