国内首个!最火的MoE大模型APP来了,免费下载,人人可玩
国内首个!最火的MoE大模型APP来了,免费下载,人人可玩MoE(混合专家)作为当下最顶尖、最前沿的大模型技术方向,MoE能在不增加推理成本的前提下,为大模型带来性能激增。比如,在MoE的加持之下,GPT-4带来的用户体验较之GPT-3.5有着革命性的飞升。
来自主题: AI资讯
11228 点击 2024-02-06 17:53
 搜索
搜索
MoE(混合专家)作为当下最顶尖、最前沿的大模型技术方向,MoE能在不增加推理成本的前提下,为大模型带来性能激增。比如,在MoE的加持之下,GPT-4带来的用户体验较之GPT-3.5有着革命性的飞升。

在 AI 赛道中,与动辄上千亿参数的模型相比,最近,小模型开始受到大家的青睐。比如法国 AI 初创公司发布的 Mistral-7B 模型,其在每个基准测试中,都优于 Llama 2 13B,并且在代码、数学和推理方面也优于 LLaMA 1 34B。

对于大型视觉语言模型(LVLM)而言,扩展模型可以有效提高模型性能。然而,扩大参数规模会显著增加训练和推理成本,因为计算中每个 token 都会激活所有模型参数。
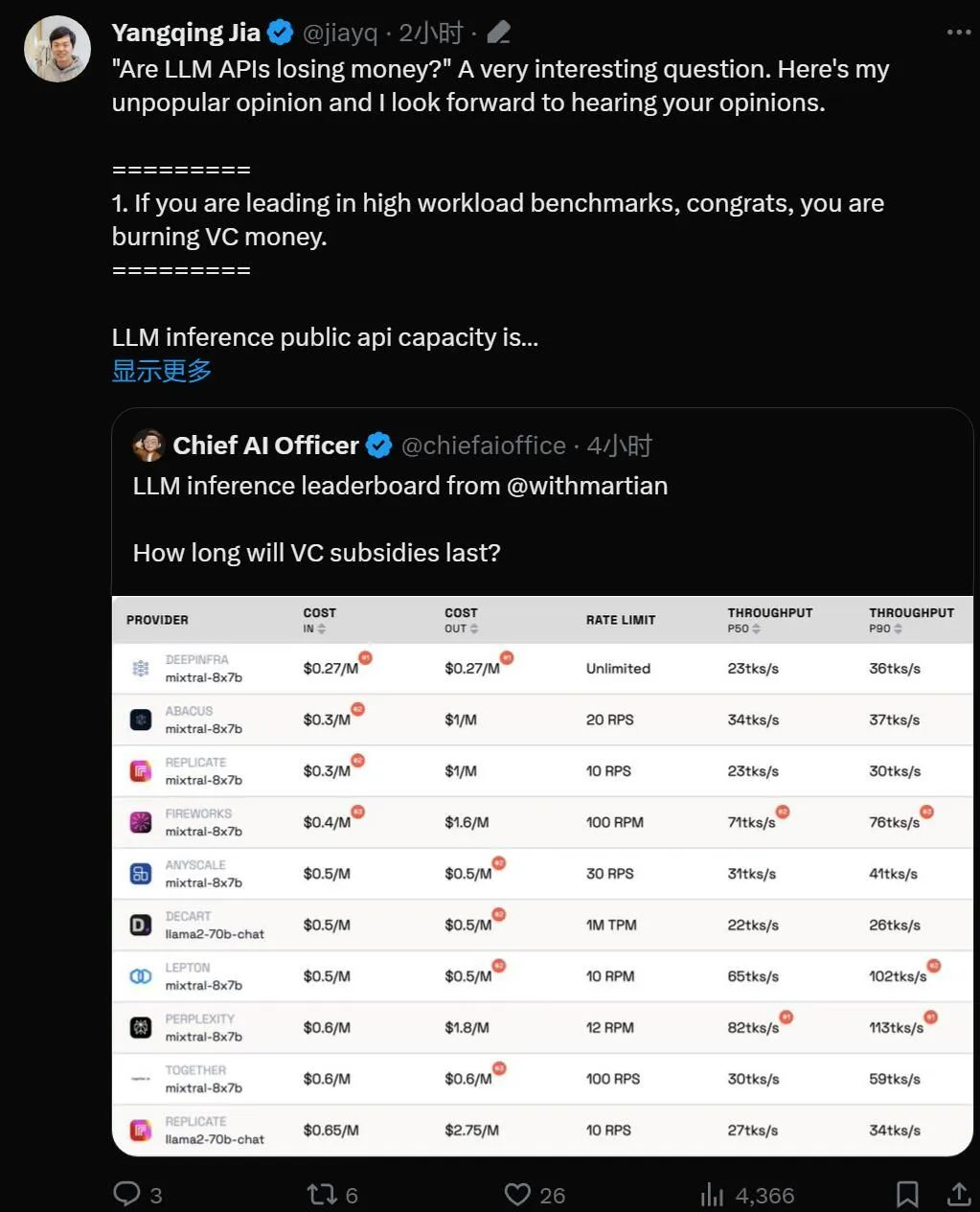
风投烧完之后,哪些大模型创业公司会开始盈利?
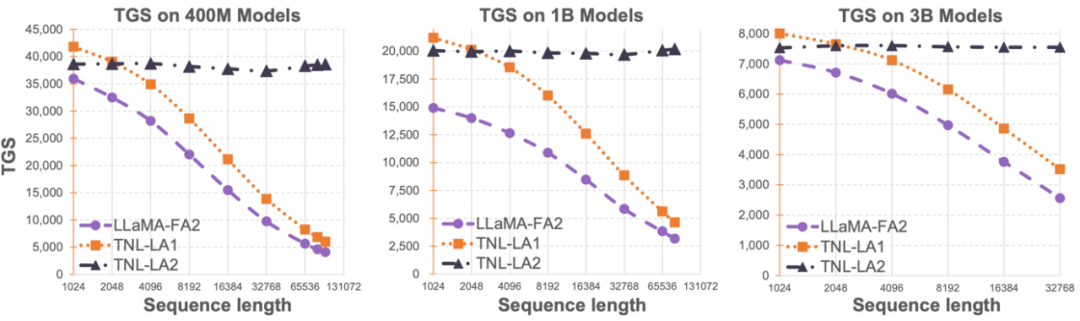
Lightning Attention-2 是一种新型的线性注意力机制,让长序列的训练和推理成本与 1K 序列长度的一致。
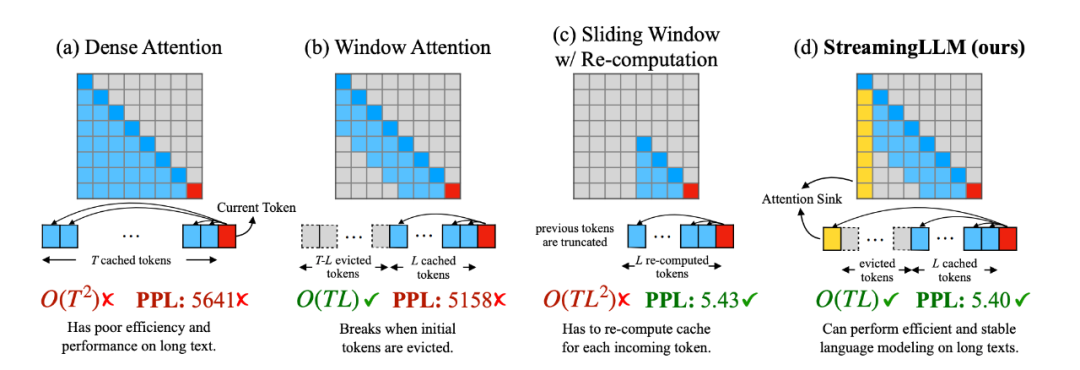
22倍加速还不够,再来提升46%,而且方法直接开源!这就是开源社区改进MIT爆火项目StreamingLLM的最新成果。