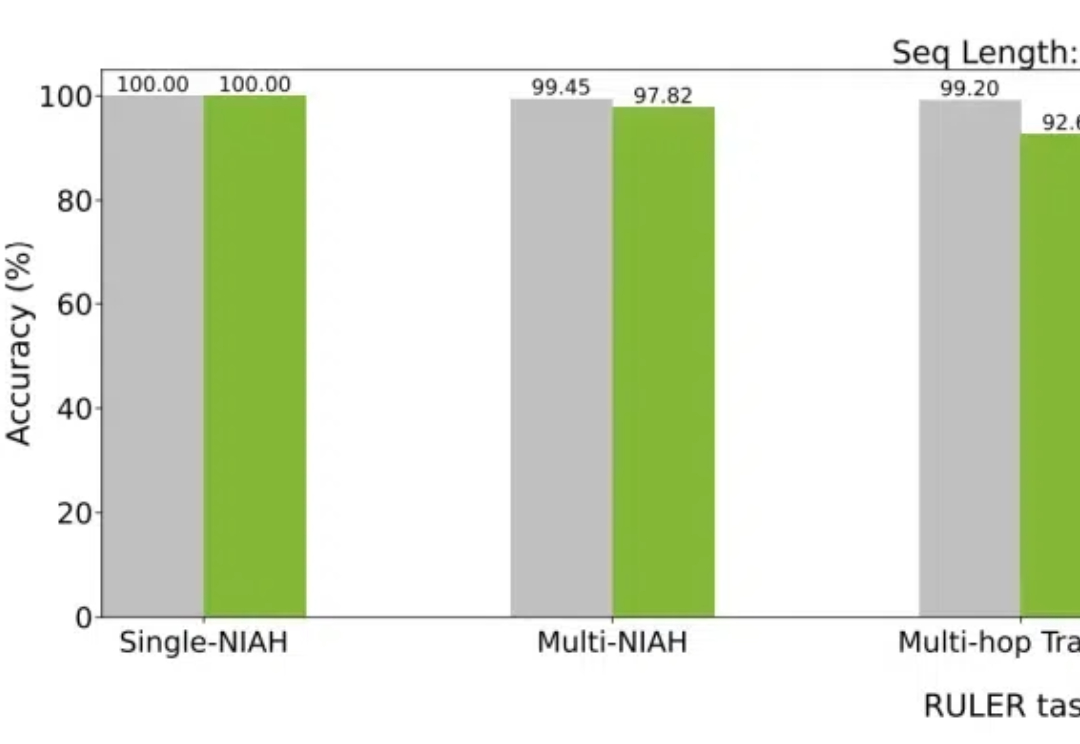
英伟达提出全新Star Attention,10倍加速LLM推理!登顶Hugging Face论文榜
英伟达提出全新Star Attention,10倍加速LLM推理!登顶Hugging Face论文榜大模型如今已具有越来越长的上下文,而与之相伴的是推理成本的上升。英伟达最新提出的Star Attention,能够在不损失精度的同时,显著减少推理计算量,从而助力边缘计算。
来自主题: AI技术研报
8287 点击 2024-12-05 11:27
 搜索
搜索
大模型如今已具有越来越长的上下文,而与之相伴的是推理成本的上升。英伟达最新提出的Star Attention,能够在不损失精度的同时,显著减少推理计算量,从而助力边缘计算。
近日,DeepMind 团队将水印技术和投机采样(speculative sampling)结合,在为大语言模型加入水印的同时,提升其推理效率,降低推理成本,因此适合用于大规模生产环境。

大模型热,企业落地难?就在刚刚,百川智能推出「1+3」产品矩阵,一站式解决大模型商业化难题。「系列优质通用数据+领域增强训练工具链」,仅需10分钟就能让企业自主成为模型定制增强专家,实现行业最佳的多场景可用率。

训练代码、中间 checkpoint、训练日志和训练数据都已经开源。

2024年,落地,无疑是大模型最重要的主题。

The Information近日爆出了一则OpenAI的亏损新闻,其中新增的关键数据包括: OpenAI目前单月收入约为2.83mnUSD,全年营收可能在35~45亿美金。 OpenAI 24年推理成本将达到40亿美金,训练成本将达到30亿美金。

本研究评估了先进多模态基础模型在 10 个数据集上的多样本上下文学习,揭示了持续的性能提升。批量查询显著降低了每个示例的延迟和推理成本而不牺牲性能。这些发现表明:利用大量演示示例可以快速适应新任务和新领域,而无需传统的微调。

随着深度学习大语言模型的越来越火爆,大语言模型越做越大,使得其推理成本也水涨船高。模型量化,成为一个热门的研究课题。

基于 Transformer 架构的大语言模型在 NLP 领域取得了令人惊艳的效果,然而,Transformer 中自注意力带来的二次复杂度使得大模型的推理成本和内存占用十分巨大,特别是在长序列的场景中。
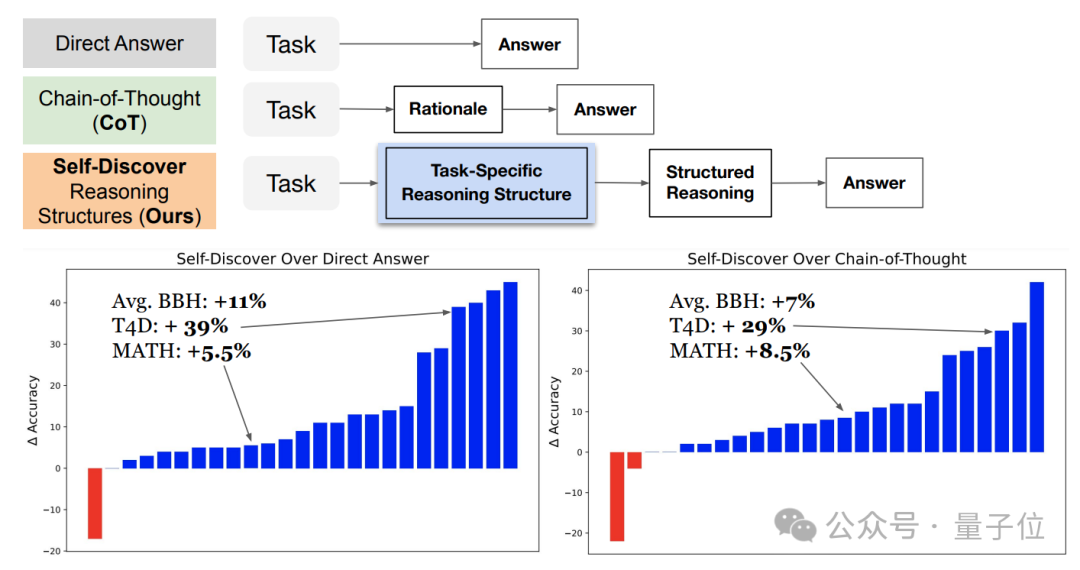
谷歌&南加大推出最新研究“自我发现”(Self-Discover),重新定义了大模型推理范式。与已成行业标准的思维链(CoT)相比,新方法不仅让模型在面对复杂任务时表现更佳,还把同等效果下的推理成本压缩至1/40。