联通破解扩散模型速度质量零和博弈,推理速度提升5倍丨CVPR 2025 Highlight
联通破解扩散模型速度质量零和博弈,推理速度提升5倍丨CVPR 2025 Highlight从“在线训练”到“离线建图”,扩散模型速度再突破!
来自主题: AI技术研报
8992 点击 2025-12-01 14:27
 搜索
搜索
从“在线训练”到“离线建图”,扩散模型速度再突破!

当前,视频生成模型性能正在快速提升,尤其是基于Transformer架构的DiT模型,在视频生成领域的表现已经逐渐接近真实拍摄效果。然而,这些扩散模型也面临一个共同的瓶颈:推理时间长、算力成本高、生成速度难以提升。随着视频生成长度持续增加、分辨率不断提高,这个瓶颈正在成为影响视频创作体验的主要障碍之一。

图像与视频重光照(Relighting)技术在计算机视觉与图形学中备受关注,尤其在电影、游戏及增强现实等领域应用广泛。当前,基于扩散模型的方法能够生成多样且可控的光照效果,但其优化过程通常依赖于语义空间,而语义上的相似性无法保证视觉空间中的物理合理性,导致生成结果常出现高光过曝、阴影错位、遮挡关系错误等不合理现象。

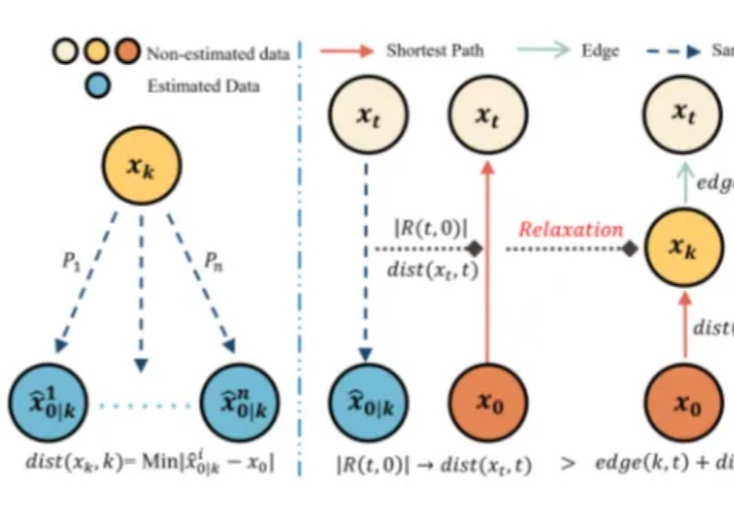
扩散概率生成模型(Diffusion Models)已成为AIGC时代的重要基础,但其推理速度慢、训练与推理之间的差异大,以及优化困难,始终是制约其广泛应用的关键问题。近日,被NeurIPS 2025接收的一篇重磅论文EVODiff给出了全新解法:来自华南理工大学曾德炉教授「统计推断,数据科学与人工智能」研究团队跳出了传统的数值求解思维,首次从信息感知的推理视角,将去噪过程重构为实时熵减优化问题。
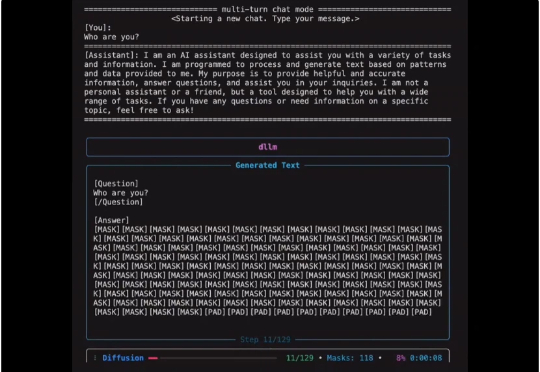
扩散式语言模型(Diffusion Language Model, DLM)虽近期受关注,但社区长期受限于(1)缺乏易用开发框架与(2)高昂训练成本,导致多数 DLM 难以在合理预算下复现,初学者也难以真正理解其训练与生成机制。

就在一周前,全宇宙最火爆的推理框架 SGLang 官宣支持了 Diffusion 模型,好评如潮。团队成员将原本在大语言模型推理中表现突出的高性能调度与内核优化,扩展到图像与视频扩散模型上,相较于先前的视频和图像生成框架,速度提升最高可达 57%:

扩散模型「去噪」,是不是反而忘了真正去噪?何恺明携弟子出手,回归本源!
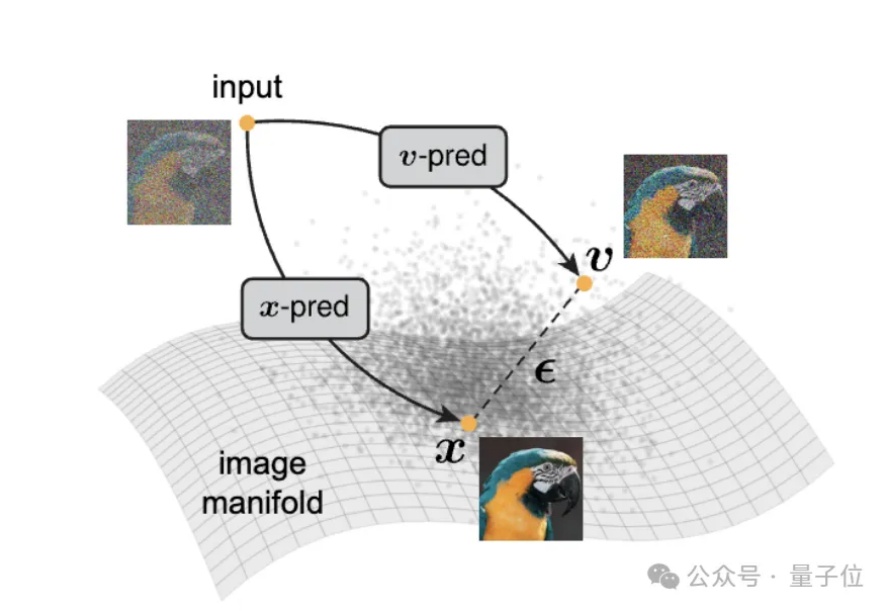
何恺明又一次返璞归真。
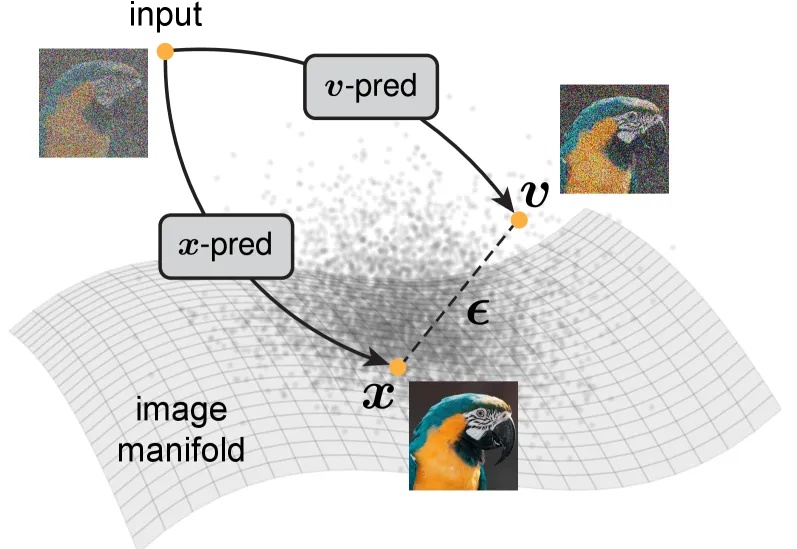
大家都知道,图像生成和去噪扩散模型是密不可分的。高质量的图像生成都通过扩散模型实现。
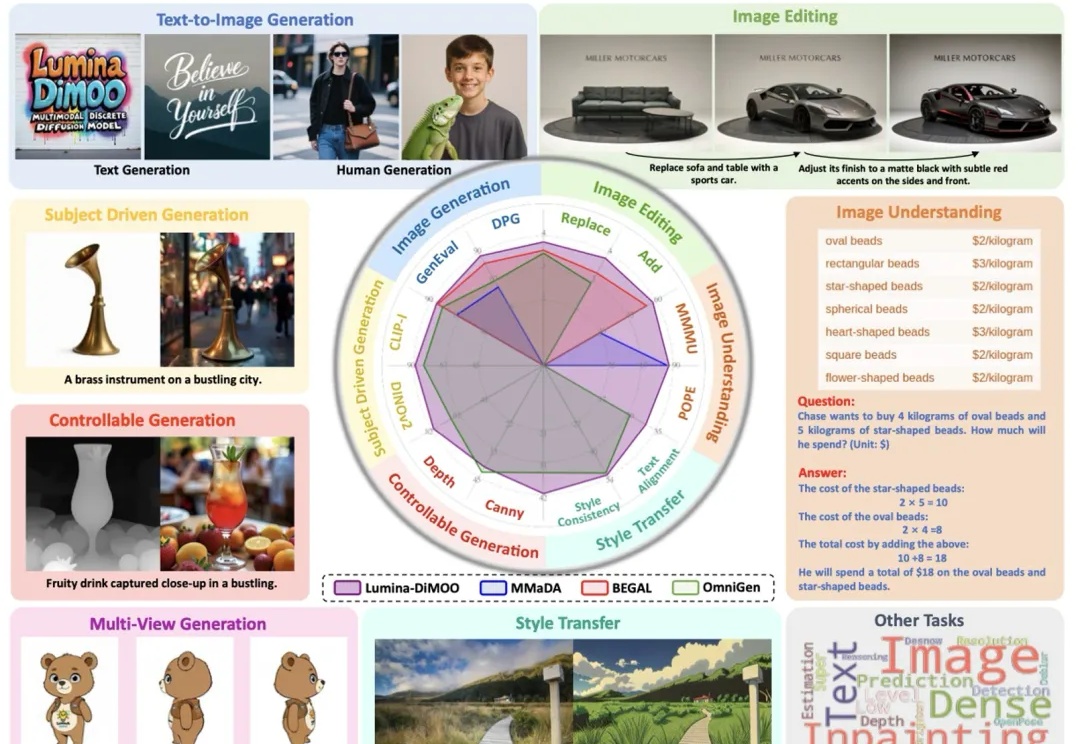
上海人工智能实验室推出了一款革新的多模态生成理解一体化的扩散语言模型 ——Lumina-DiMOO。基于离散扩散建模(Discrete Diffusion Modeling),Lumina-DiMOO 打破了多模态任务之间的壁垒,在同一离散扩散框架下,完成从 文本→图像、图像→图像、图像→文本的全栈能力闭环。