
任意条件,「可控」文生图扩散模型综述 | TPAMI'25
任意条件,「可控」文生图扩散模型综述 | TPAMI'25北邮最新综述探讨了文生图扩散模型的可控生成技术,总结了在文本条件之外引入新条件信号的方法,从任务和方法两个层面梳理了可控生成技术。
来自主题: AI技术研报
9282 点击 2026-01-19 08:55
 搜索
搜索
北邮最新综述探讨了文生图扩散模型的可控生成技术,总结了在文本条件之外引入新条件信号的方法,从任务和方法两个层面梳理了可控生成技术。
站在 2026 年的开端回望,LLM 的架构之争似乎进入了一个新的微妙阶段。过去几年,Transformer 架构以绝对的统治力横扫了人工智能领域,但随着算力成本的博弈和对推理效率的极致追求,挑战者们从未停止过脚步。

近年来,视频扩散模型在 “真实感、动态性、可控性” 上进展飞快,但它们大多仍停留在纯 RGB 空间。模型能生成好看的视频,却缺少对三维几何的显式建模。这让许多世界模型(world model)导向的应用(空间推理、具身智能、机器人、自动驾驶仿真等)难以落地,因为这些任务不仅需要像素,还需要完整地模拟 4D 世界。
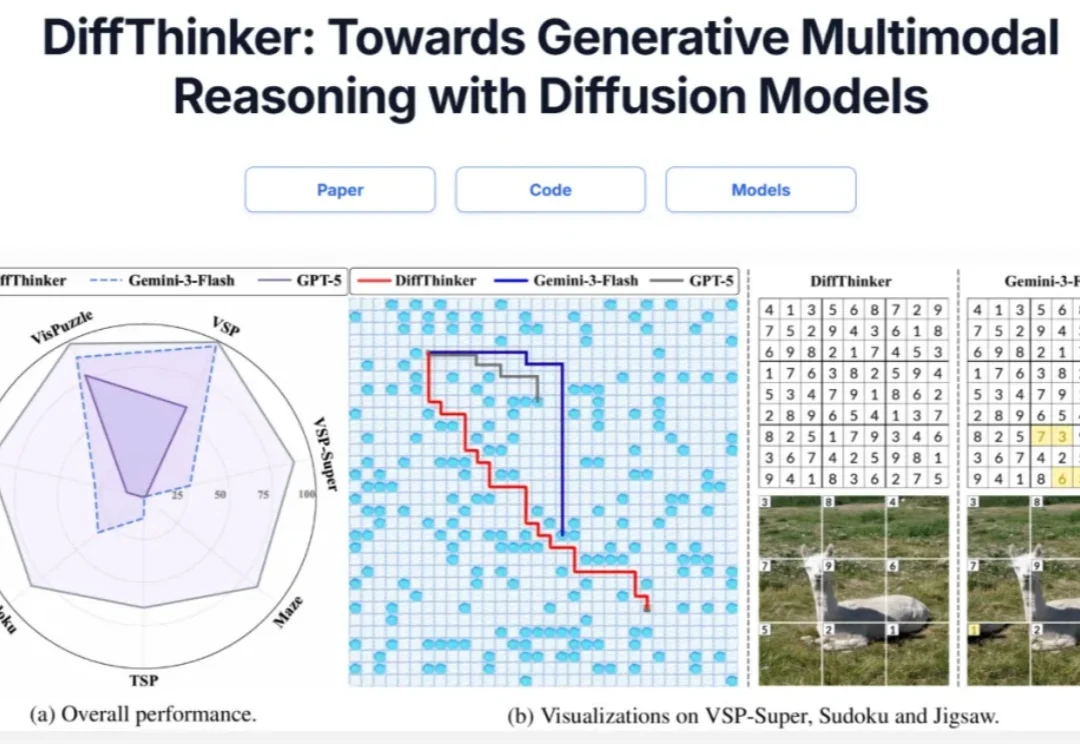
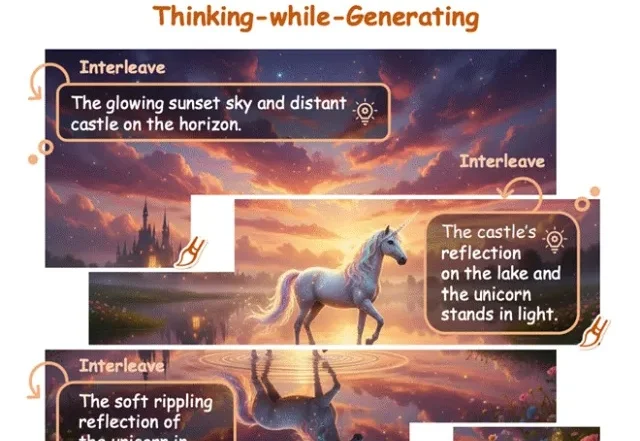
在多模态大模型(MLLMs)领域,思维链(CoT)一直被视为提升推理能力的核心技术。然而,面对复杂的长程、视觉中心任务,这种基于文本生成的推理方式正面临瓶颈:文本难以精确追踪视觉信息的变化。形象地说,模型不知道自己想到哪一步了,对应图像是什么状态。
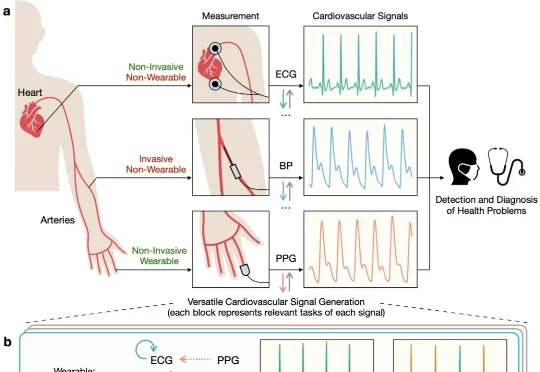
近日,清华朱军等团队提出了一种统一的多模态生成框架 UniCardio,在单扩散模型中同时实现了心血管信号的去噪、插补与跨模态生成,为真实场景下的人工智能辅助医疗提供了一种新的解决思路。
在文生图(Text-to-Image)和视频生成领域,以FLUX.1、Emu3为代表的扩散模型与自回归模型已经能生成极其逼真的画面。

尽管扩散模型在单图像生成上已经日渐成熟,但当任务升级为高度定制化的多实例图像生成(Multi-Instance Image Generation, MIG)时,挑战随之显现:

过去三年,扩散模型席卷图像生成领域。以 DiT (Diffusion Transformer) 为代表的新一代架构不断刷新图像质量的极限,让模型愈发接近真实世界的视觉规律。
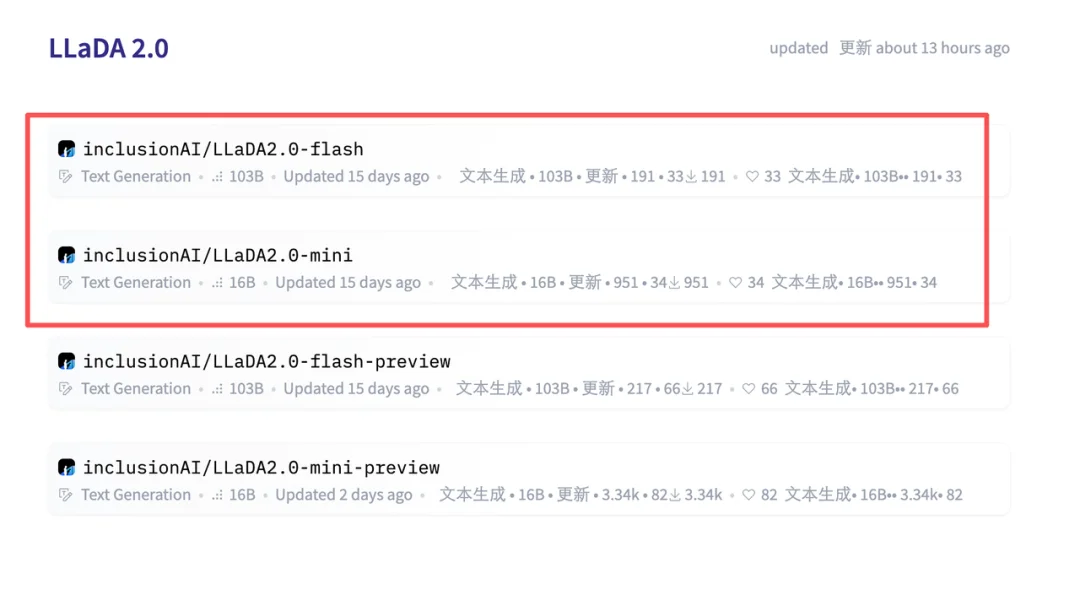
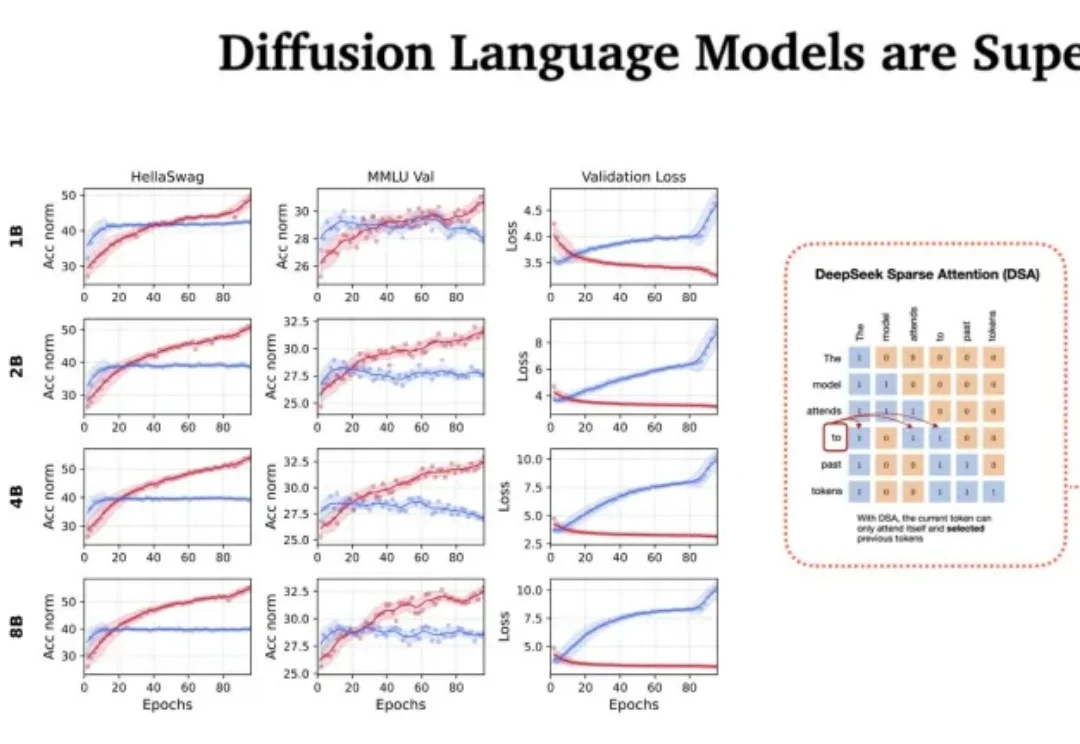
前段时间,我们在 HuggingFace 页面发现了两个新模型:LLaDA2.0-mini 和 LLaDA2.0-flash。它们来自蚂蚁集团与人大、浙大、西湖大学组成的联合团队,都采用了 MoE 架构。前者总参数量为 16B,后者总参数量则高达 100B—— 在「扩散语言模型」这个领域,这是从未见过的规模。
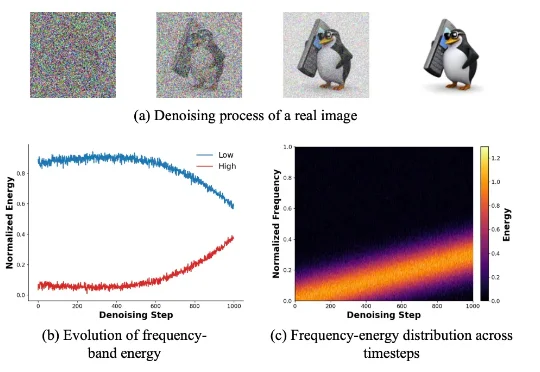
新加坡国立大学 LV Lab(颜水成团队) 联合电子科技大学、浙江大学等机构提出 FeRA (Frequency-Energy Constrained Routing) 框架:首次从频域能量的第一性原理出发,揭示了扩散去噪过程具有显著的「低频到高频」演变规律,并据此设计了动态路由机制。