# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
自回归模型,是 AIGC 领域一块迷人的基石。开发者们一直在探索它在视觉生成领域的边界,从经典的离散序列生成,到结合强大扩散模型的混合范式,每一步都凝聚了社区的智慧。
这些工作,比如 MAR、Fluid、LatentLM 等,为我们带来了巨大的启发,也让我们看到了进一步优化的空间:比如,如何避免离散化带来的信息损失?如何让模型的架构更轻盈、更强大?
带着这些问题,阶跃星辰团队进行了新的尝试,并分享了阶段性成果:NextStep-1。
阶跃星辰的初衷是探索一条新的自回归图像生成的路径。NextStep-1 的核心思想是直接在连续的视觉空间中,以自回归方式进行生成。
为实现这一点,团队采用了一个轻量的「流匹配头」(Flow Matching Head)。它让模型能够:
这一设计带来了另一个显著优势:架构的简洁与纯粹。由于不再需要外部大型扩散模型的 「辅助」,NextStep-1 的整体架构变得高度统一,实现了真正意义上的端到端训练。
阶跃星辰团队认为,NextStep-1 的探索指向了一个有趣且充满潜力的方向。它证明了在不牺牲连续性的前提下,构建一个简洁、高效的自回归模型是完全可行的。
这只是探索的第一步。阶跃星辰选择将 NextStep-1 开源,衷心期待它能引发更多有价值的讨论,并希望能与社区的研究者一起,继续推动生成技术的演进。

整体架构
NextStep-1 的架构如图 1 所示,其核心是一个强大的 Transformer 骨干网络(14B 参数),辅以一个轻量级的流匹配头(Flow Matching Head,157M 参数),用于直接生成连续的图像 Patch。
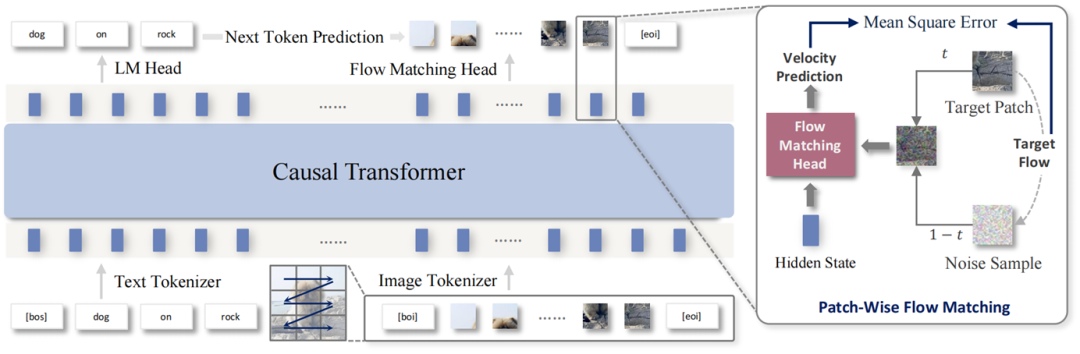
图 1 NextStep-1 的架构图
这一结构极其简洁、纯粹,它带来了两大解放:
核心发现
在探索 NextStep-1 的过程中,阶跃星辰团队获得了两个关键发现,它们不仅解释了模型为何高效,也为未来的研究提供了新的思路。
发现一:真正的「艺术家」 是 Transformer
在阶跃星辰的框架中,Transformer 是 「主创」,流匹配头更像是「画笔」。团队通过实验发现,流匹配头的尺寸大小( 157M -> 528M),对最终图像质量影响很小。这有力地证明了,核心的生成建模与逻辑推理等 「重活」,完全由 Transformer 承担。流匹配头则作为一个高效轻量的采样器,忠实地将 Transformer 的潜在预测 「翻译」 成图像 Patch。
发现二:Tokenizer 的「炼金术」—— 稳定与质量的关键
在连续视觉 Token 上的操作带来了独特的稳定性挑战,团队发现两个关键 「炼金术」:
NextStep-1 实现了高保真的文生图的生成,同时具有强大的图像编辑能力,覆盖多种编辑操作(如物体增删、背景修改、动作修改、风格迁移等),并能理解用户的日常语言指令,实现形式自由的图像编辑。

图 2 展示 NextStep-1 全面的图像生成和编辑能力
硬核实力:权威 Benchmark 下的表现
除了直观的视觉效果,阶跃星辰团队也在多个行业公认的 Benchmark 上对 NextStep-1 进行了严格的评估。结果表明,
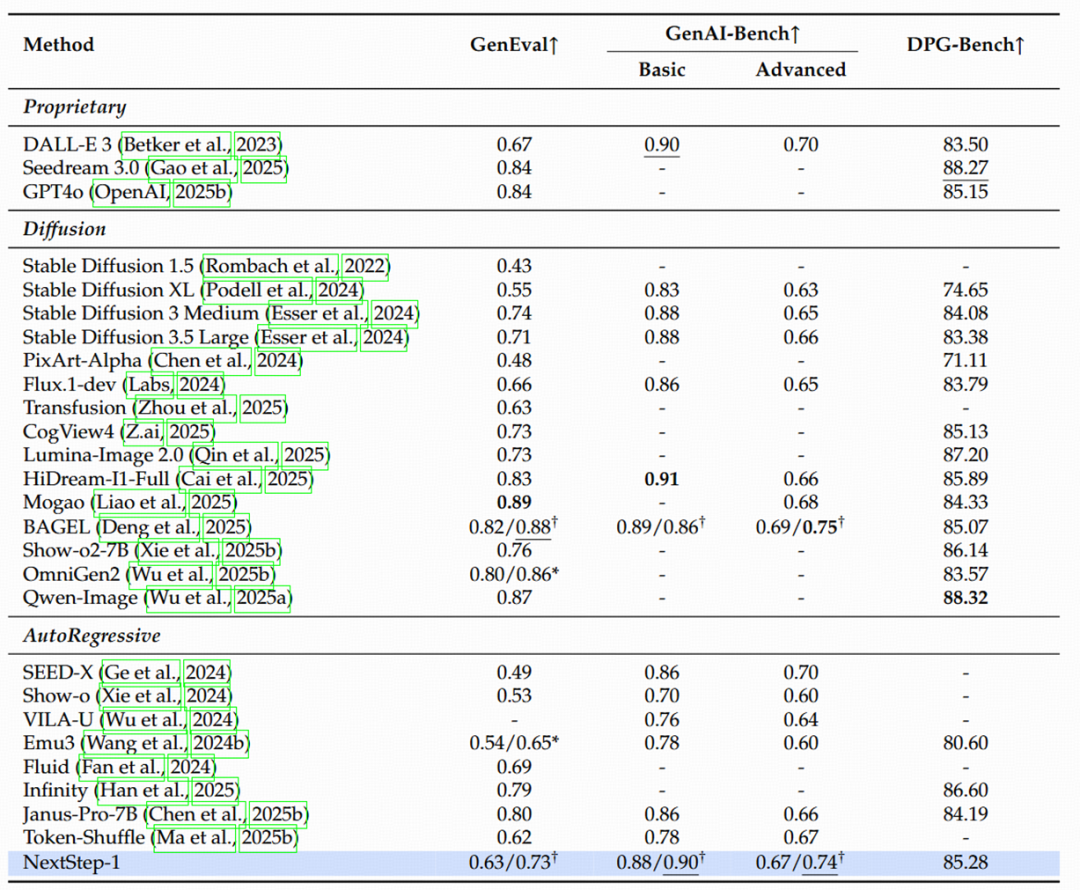
表 1 NextStep-1 在 GenEval、GenAI-Bench 和 DPG-Bench 上的性能
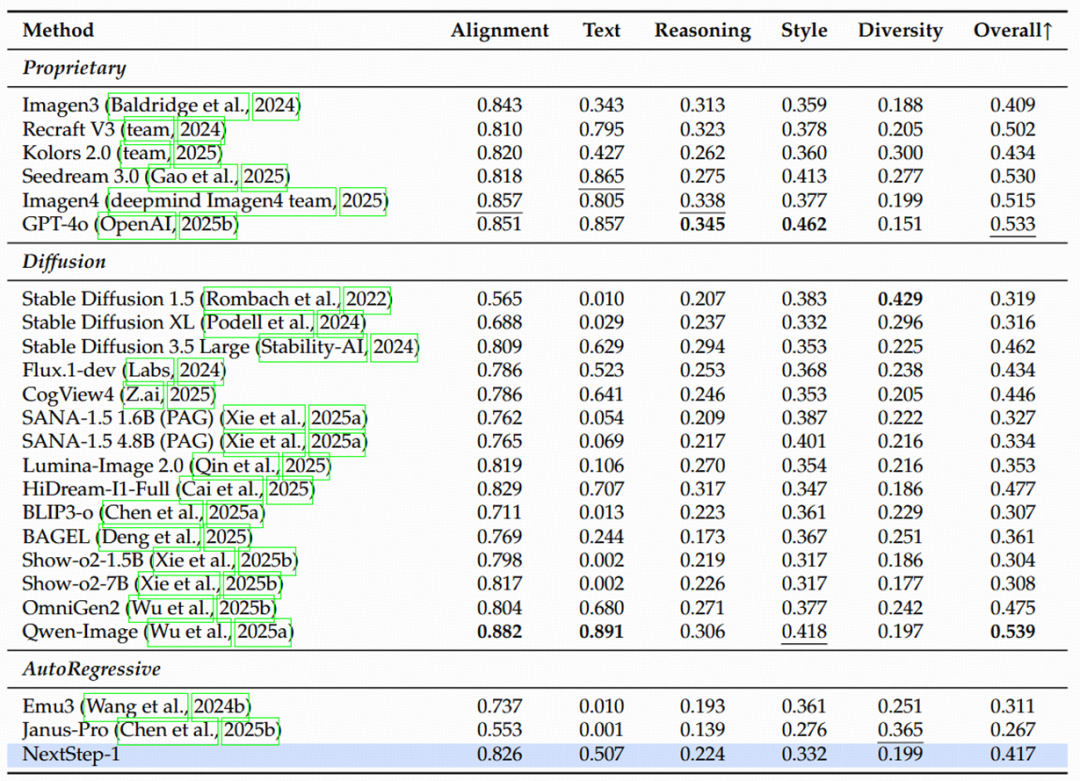
表 2 NextStep-1 在 OneIG 上的性能
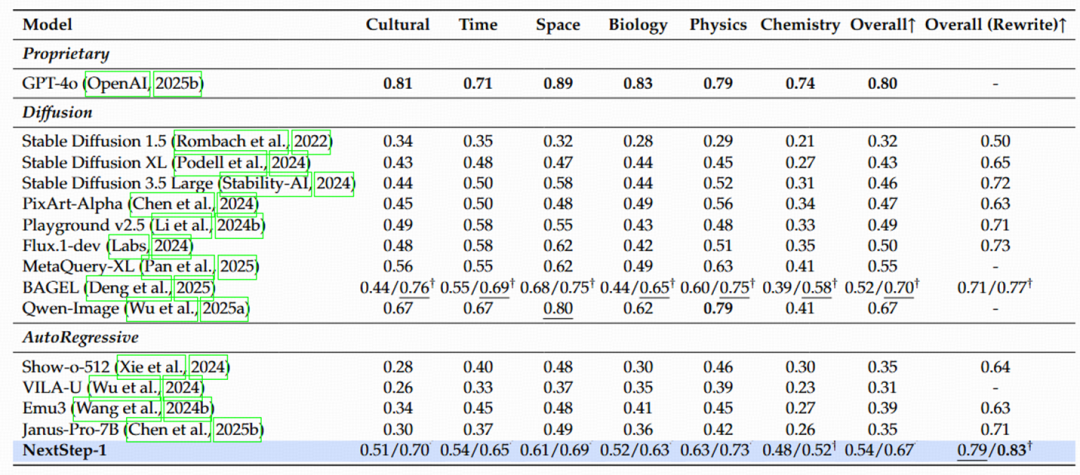
表 3 NextStep-1 在 WISE 上的性能
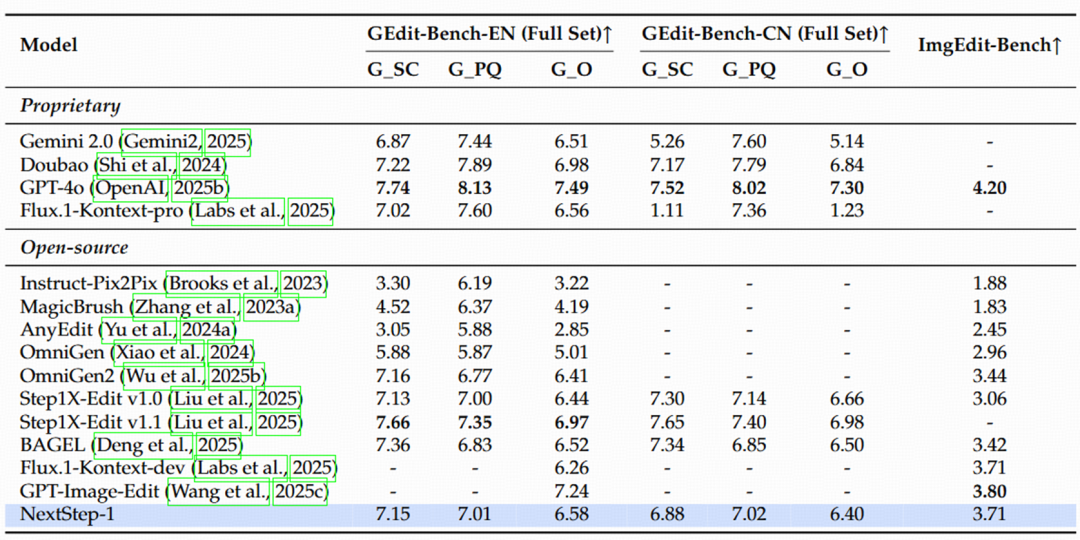
表 4 NextStep-1 在 GEdit-Bench 和 ImgEdit-Bench 上的性能
NextStep-1 是阶跃星辰团队对构建简洁的高保真生成模型的一次真诚探索。它证明了,在不牺牲连续性的前提下,构建一个纯粹的端到端自回归模型是完全可行的。阶跃星辰相信,这条 「简洁」 的道路,为多模态生成领域提供了有价值的新视角。
阶跃星辰团队深知这只是探索的开始,前路依然广阔。作为一个对新范式的初步探索,NextStep-1 在展现出巨大潜力的同时,也让团队识别出了一些亟待解决的挑战。我们在此坦诚地列出这些观察,并视其为未来工作的重要方向。
生成过程中不稳定
NextStep-1 成功证明了自回归模型可以在高维连续潜在空间中运行,并达到媲美扩散模型的生成质量,但这条路径也带来了独特的稳定性挑战。观察到,当模型的潜在空间从低维(如 4 通道)扩展到更高维(如 16 通道)时,尽管后者能表达更丰富的细节,但也偶发性地出现了一些生成 「翻车」的情况(如图 3 所示)。

图 3 失败的例子,展示图像生成过程中一些暴露出的问题
虽然其根本原因仍有待进一步探究,但团队推测可能存在以下因素:
顺序解码带来的推理延迟
自回归模型的顺序解码特性,是其推理速度的主要瓶颈。研究团队对单个 Token 在 H100 GPU 上的延迟进行了理论分析(如表 5 所示),结果表明:
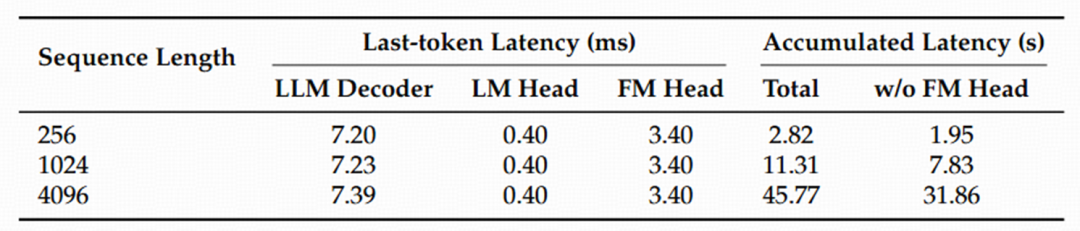
表 5 H100 上生成每个 token 的理论延迟速度 ( batch size 为 1 )
这一观察指明了两个明确的加速方向:
高分辨率生成的挑战
在扩展到高分辨率图像生成方面,与技术生态已相当成熟的扩散模型相比,阶跃星辰团队的框架面临两大挑战:
因此,基于 patch-wise 的图像自回归模型的高分辨率生成是一个重要探索方向。
监督微调(SFT)的独特挑战
团队观察到,当使用小规模、高质量的数据集进行微调时,训练动态会变得极不稳定。
扩散模型通常仅需数千个样本,就能稳定地适应目标数据分布,同时保持良好的泛化生成能力。相比之下,阶跃星辰的 SFT 过程:
因此,如何在一个小规模数据集上,找到一个既能对齐目标风格、又能保留通用生成能力的 「甜蜜点」(sweet spot)检查点,对阶跃星辰团队而言仍然是一个重大的挑战。
阶跃星辰团队相信,坦诚地面对这些挑战,是推动领域前进的第一步。
NextStep-1 的开源是团队为此付出的努力,也希望能成为社区进一步研究的基石。阶跃星辰团队期待与全球的研究者和开发者交流与合作,共同推动自回归生成技术向前发展。
文章来自于微信公众号“机器之心”。


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
