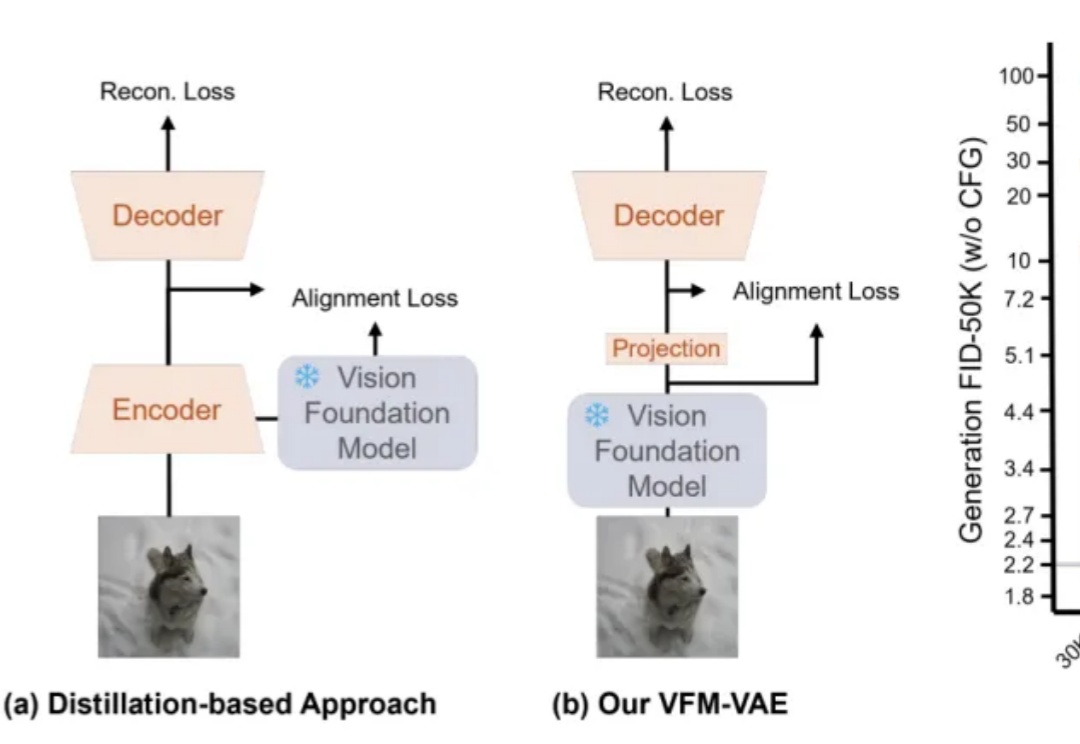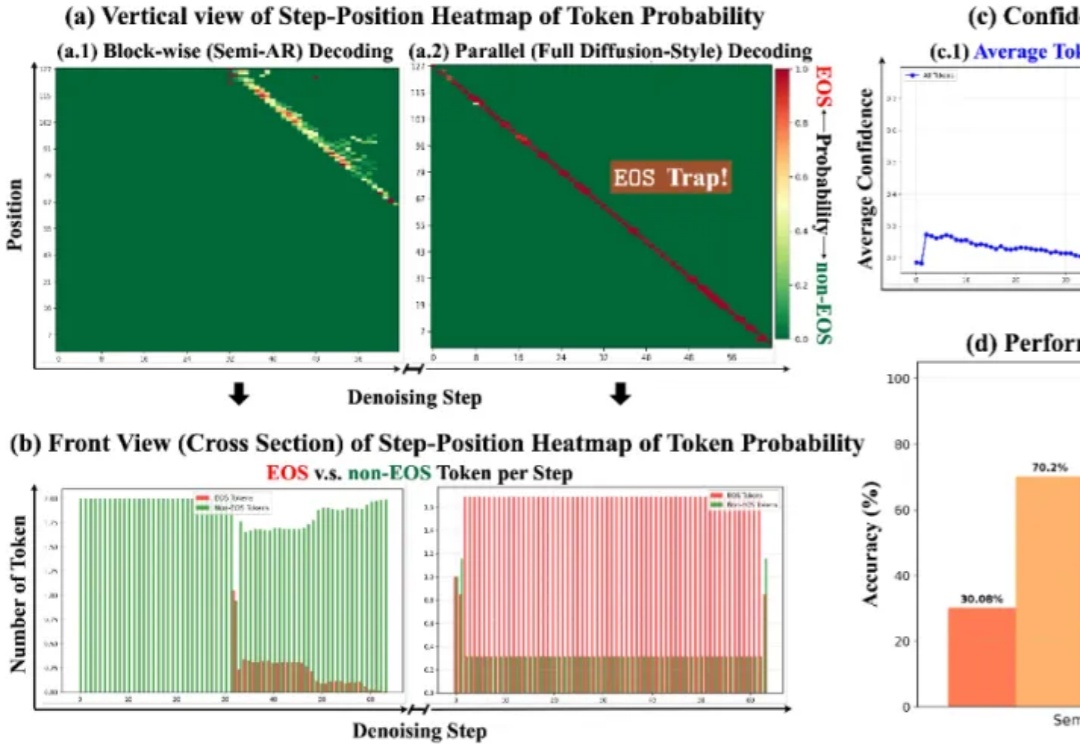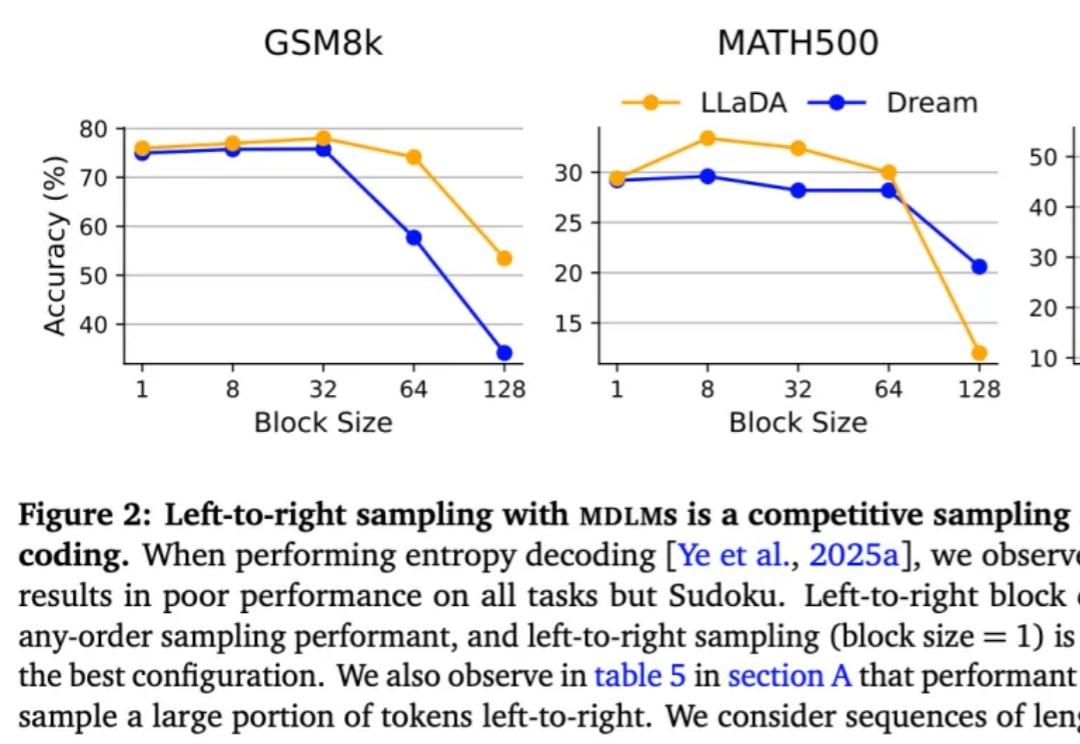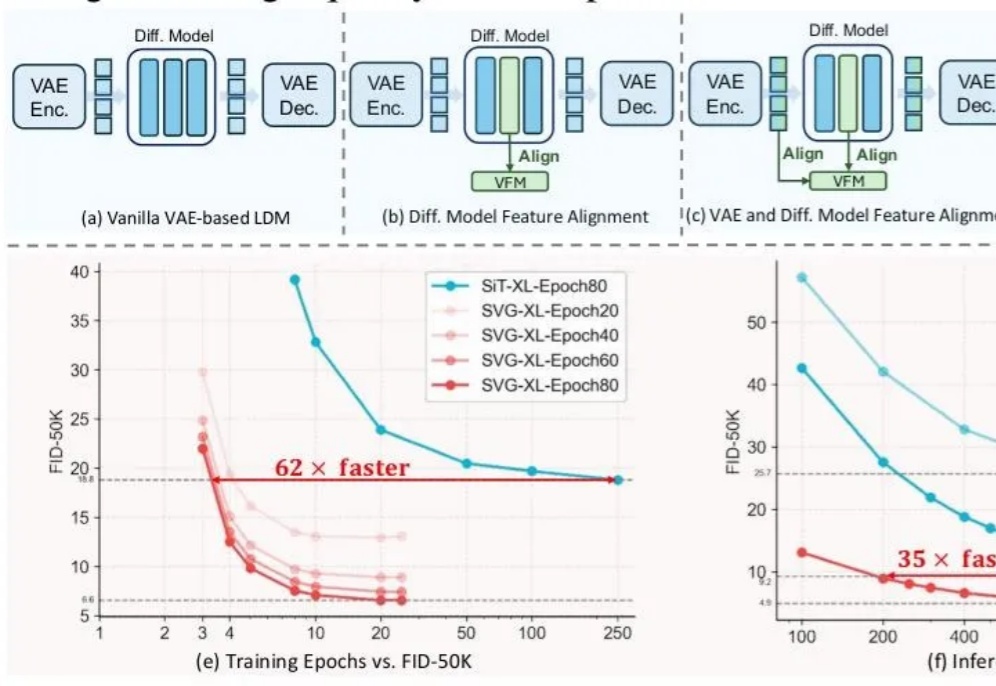
AAAI 2026|教会视频扩散模型「理解科学现象」:从初始帧生成整个物理演化
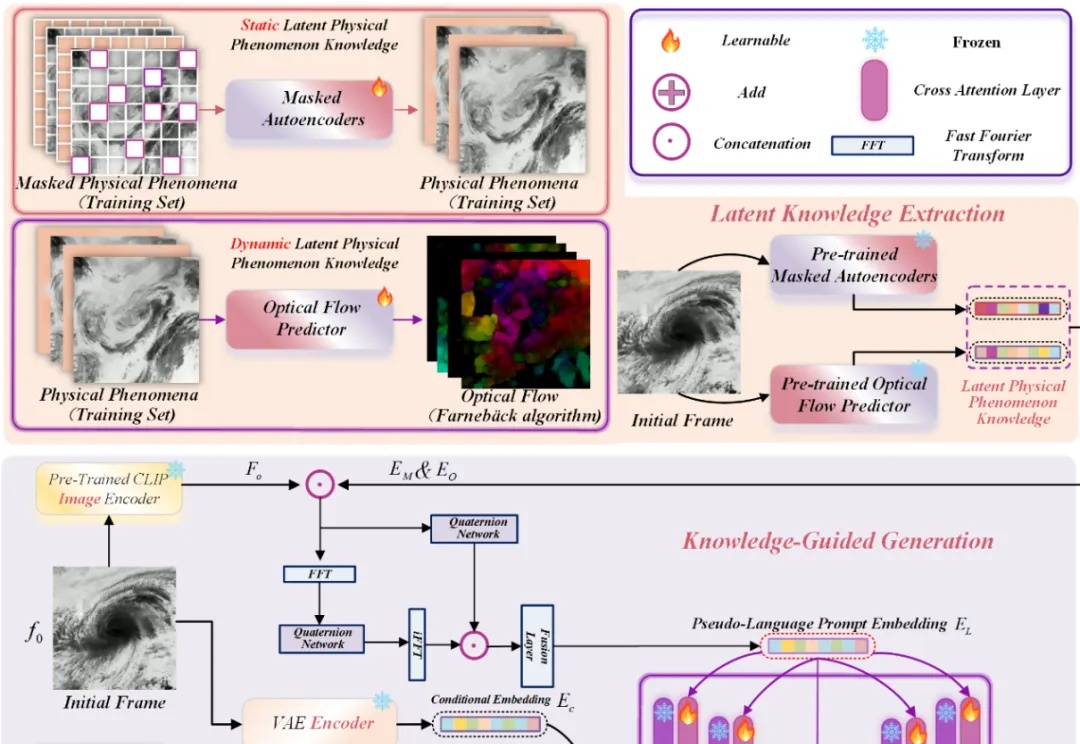
AAAI 2026|教会视频扩散模型「理解科学现象」:从初始帧生成整个物理演化近年来,Stable Diffusion、CogVideoX 等视频生成模型在自然场景中表现惊艳,但面对科学现象 —— 如流体模拟或气象过程 —— 却常常 “乱画”:如下视频所示,生成的流体很容易产生违背物理直觉的现象,比如气旋逆向旋转或整体平移等等。
来自主题: AI技术研报
11913 点击 2025-11-17 09:22