
203.8亿!AI视频最大单笔融资,即将诞生
203.8亿!AI视频最大单笔融资,即将诞生《南华早报》援引知情人士消息称,快手旗下视频生成业务“可灵AI”将完成一轮30亿美元(约合人民币203.8亿元)融资,投后估值将达到180亿美元(约合人民币1223亿元),较今年4月最初设定的200亿美元目标估值缩水20亿美元。腾讯参与了可灵AI本轮融资。
来自主题: AI资讯
9015 点击 2026-07-02 01:41
 搜索
搜索
《南华早报》援引知情人士消息称,快手旗下视频生成业务“可灵AI”将完成一轮30亿美元(约合人民币203.8亿元)融资,投后估值将达到180亿美元(约合人民币1223亿元),较今年4月最初设定的200亿美元目标估值缩水20亿美元。腾讯参与了可灵AI本轮融资。
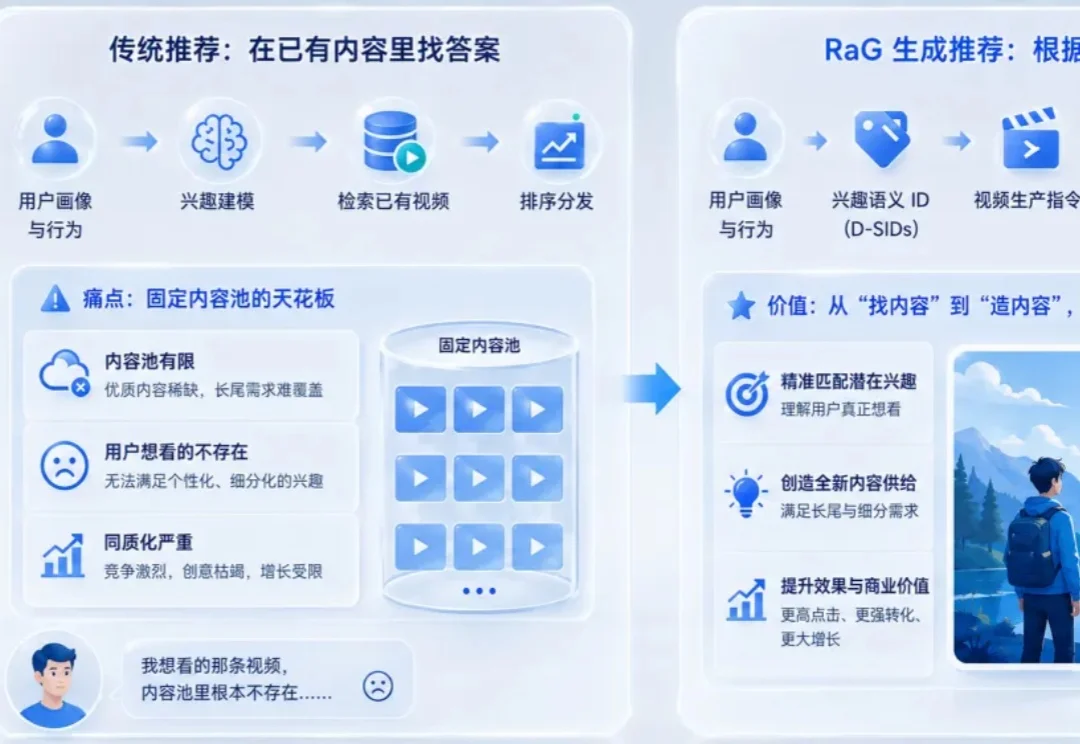
过去十年,推荐系统最核心的动作可以概括成一个字:找。

如今,CameraSquad 的出现,让这种多视角一致的视频生成与 3D 世界状态构建成为现实。近日,中国科学院大学高林研究员团队联合卡迪夫大学、香港科技大学和快手可灵团队,提出了一种面向多轨迹并行生成的相机可控视频生成方法 CameraSquad [1],相关论文已被 ACM SIGGRAPH 2026 录用。
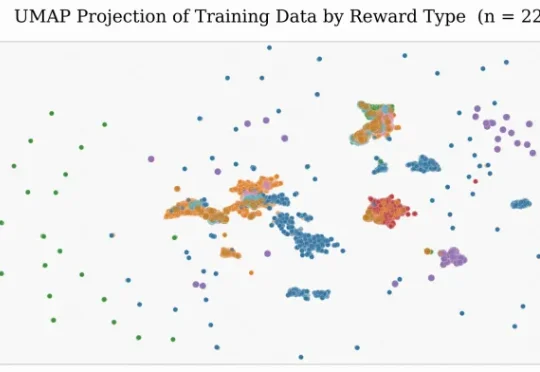
本研究由快手科技语言大模型团队完成,核心作者吕民轩、梅铁桦、杜坦隆等。快手科技与中国科学院大学联合提出 GoLongRL,一套完全开源的长上下文强化学习后训练方案,包含 23K 样本 RLVR 数据集
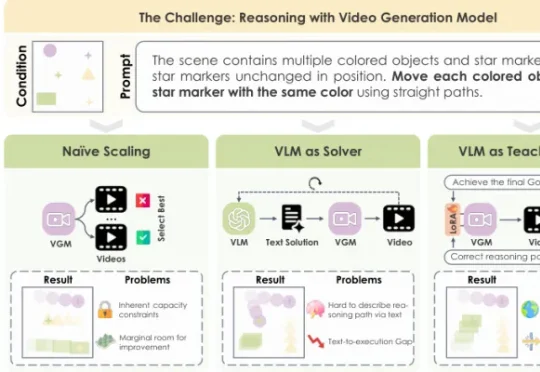
怎么让VGM学会按规则推理?过去主要有两条路。两条路,一个不动模型,一个只写文字,都没真正解决“执行”问题。为此,城大×快手可灵提出了第三条路:VLM-as-Teacher。

《读佳》获知,快手APP已推出“AI购物助手”,并附有一个独立入口,和行业中的主流导购功能类似,快手的AI导购助手也是通过与消费者对话的形式,提供商品推荐、商品评价、商品对比等智能服务。
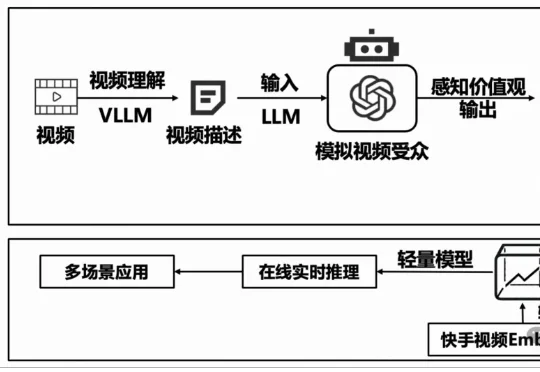
清华大学经济管理学院的陈柯均博士生、张佳音教授、徐心教授与快手消费策略算法部合作探索完成了一项联合实验:从视频传递的价值观的角度,去理解观看视频后用户的行为和心理变化。
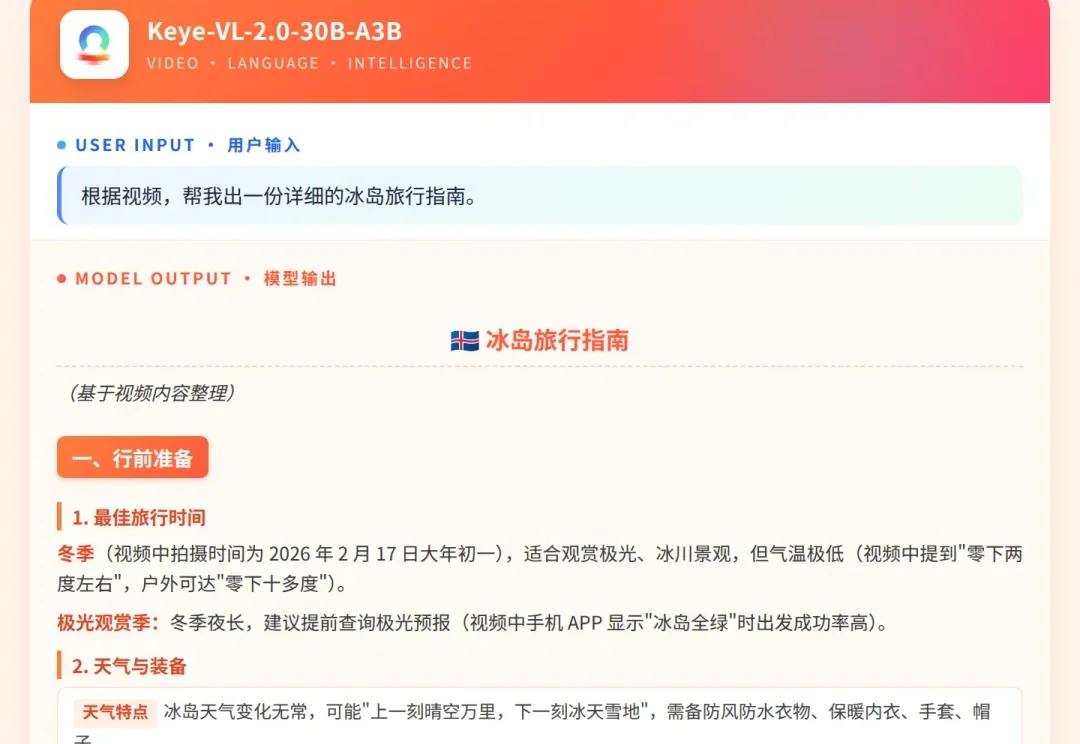
当你把一段长达9分钟、在“晴空万里”与“冰天雪地”间剧烈切换的冰岛旅行Vlog输入给大模型,并要求它做一份旅行攻略时,常规的视觉大模型通常只能给出一份基于字幕和画面标签拼凑的“流水账”。

从来没聊过可灵。
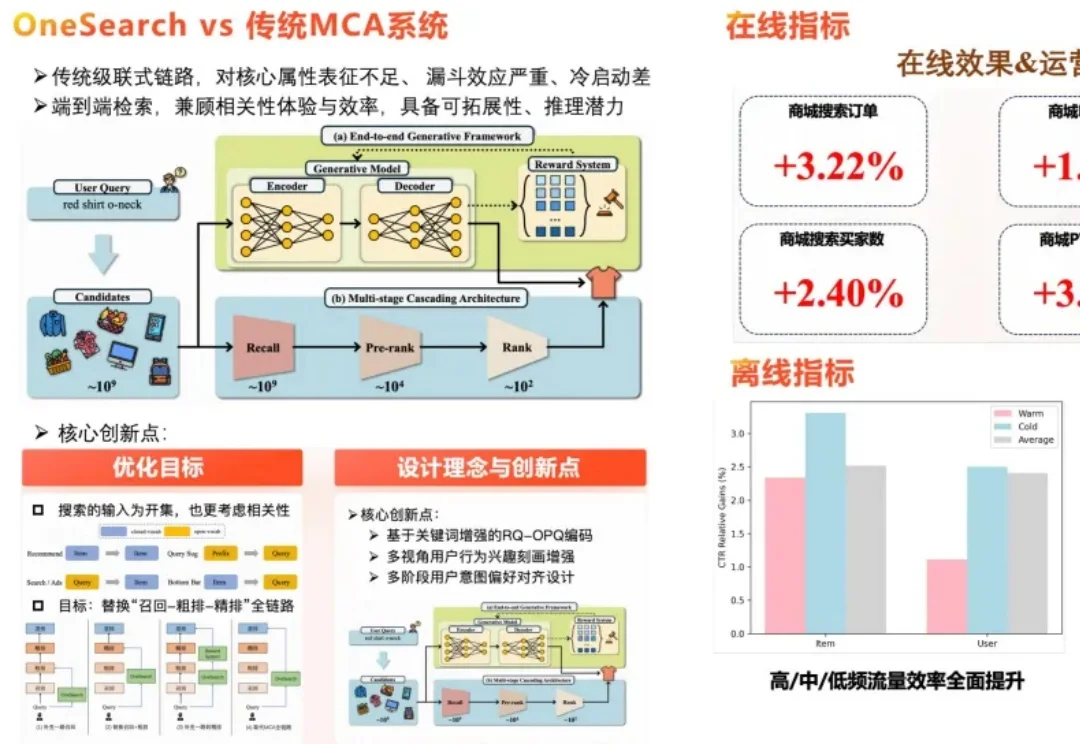
针对生成式检索范式在电商搜索场景下面临的复杂查询理解不足、用户潜在意图挖掘乏力、奖励系统易过拟合历史窄偏好等落地瓶颈,快手技术团队在已规模化部署的工业级生成式搜索框架 OneSearch 基础上,发布了一篇系统性升级的研究论文,正式推出新一代框架 OneSearch-V2。