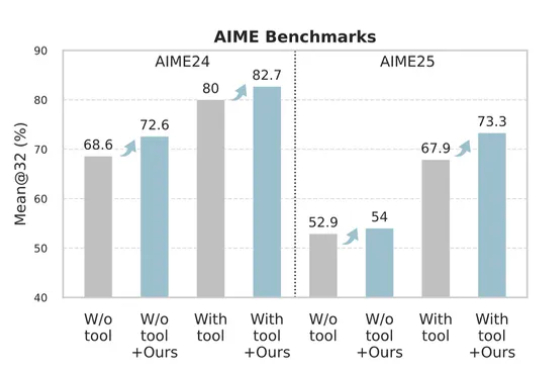
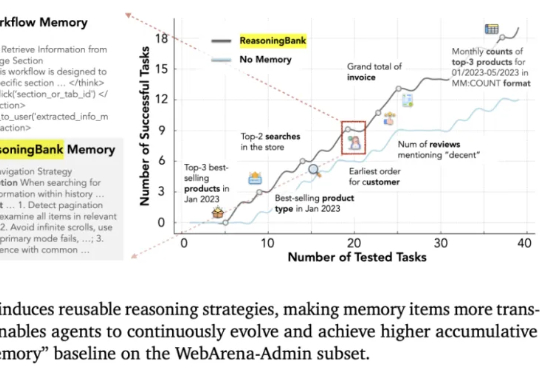
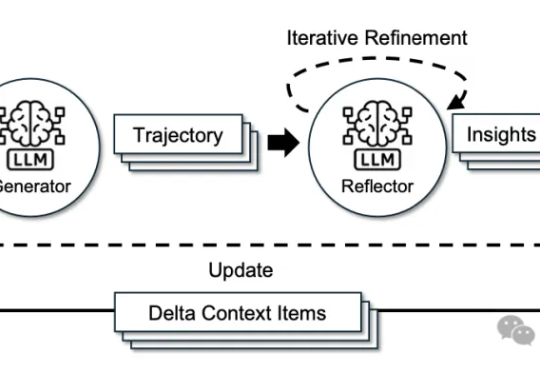
RL微调,关键在前10%奖励!基于评分准则,Scale AI等提出新方法
RL微调,关键在前10%奖励!基于评分准则,Scale AI等提出新方法大模型强化学习总是「用力过猛」?Scale AI联合UCLA、芝加哥大学的研究团队提出了一种基于评分准则(rubric)的奖励建模新方法,从理论和实验两个维度证明:要想让大模型对齐效果好,关键在于准确区分「优秀」和「卓越」的回答。这项研究不仅揭示了奖励过度优化的根源,还提供了实用的解决方案。
来自主题: AI技术研报
8799 点击 2025-10-17 09:48