
EMNLP2025 | 通研院揭秘MoE可解释性,提升Context忠实性!
EMNLP2025 | 通研院揭秘MoE可解释性,提升Context忠实性!在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。
来自主题: AI技术研报
10440 点击 2025-11-17 09:25
 搜索
搜索
在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。
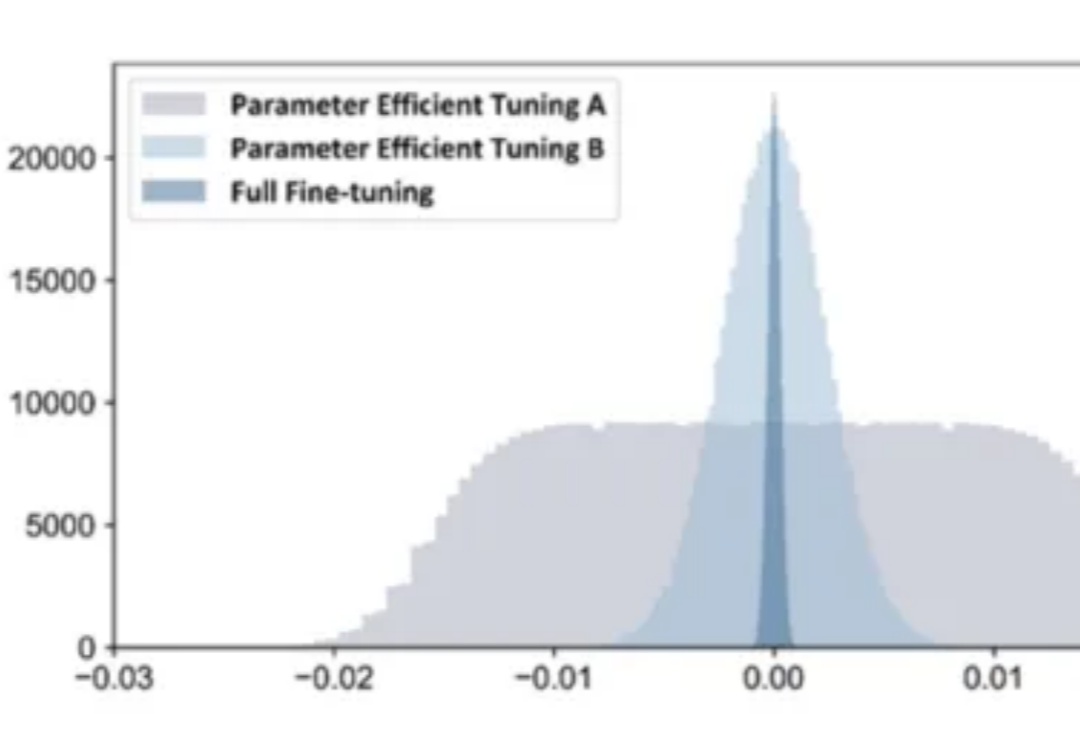
在 AI 技术飞速发展的今天,如何高效地将多个专业模型的能力融合到一个通用模型中,是当前大模型应用面临的关键挑战。全量微调领域已经有许多开创性的工作,但是在高效微调领域,尚未有对模型合并范式清晰的指引。
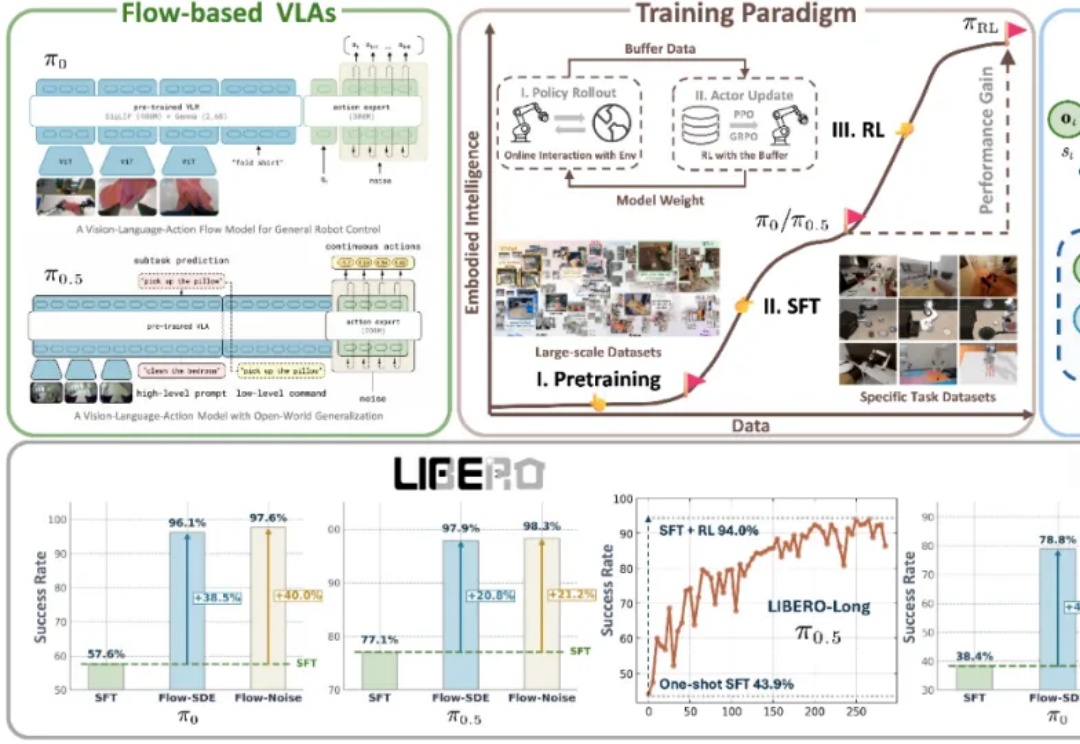
近年来,基于流匹配的 VLA 模型,特别是 Physical Intelligence 发布的 π0 和 π0.5,已经成为机器人领域备受关注的前沿技术路线。流匹配以极简方式建模多峰分布,能够生成高维且平滑的连续动作序列,在应对复杂操控任务时展现出显著优势。

微调超大参数模型,现在的“打开方式”已经大变样了: 仅需2-4 张消费级显卡(4090),就能在本地对DeepSeek 671B乃至Kimi K2 1TB这样的超大模型进行微调了。
在大数据和大模型推动下,微调技术凭借成本低、效率高优势,成为应对小样本、长尾目标等复杂场景的利器。从早期全参数微调到参数高效微调(PEFT),再到如今融合多种PEFT技术的混合微调,遥感微调技术不断进化。清华大学等团队在CVMJ期刊上系统梳理了技术脉络,并指出了九个潜在研究方向,助力遥感技术在农业监测、天气预报等关键领域发挥更大作用。

用 iPhone 本地跑大模型已经不是新鲜事了,但能不能在 iPhone 上微调模型呢?

2023 年的秋天,当全世界都在为 ChatGPT 和大语言模型疯狂的时候,远在澳大利亚悉尼的一对兄弟却在为一个看似简单的问题发愁:为什么微调一个开源模型要花这么长时间,还要用那么昂贵的 GPU?

在大模型微调实践中,SFT(监督微调)几乎成为主流流程的一部分,被广泛应用于各类下游任务和专用场景。比如,在医疗领域,研究人员往往会用领域专属数据对大模型进行微调,从而显著提升模型在该领域特定任务上的表现。
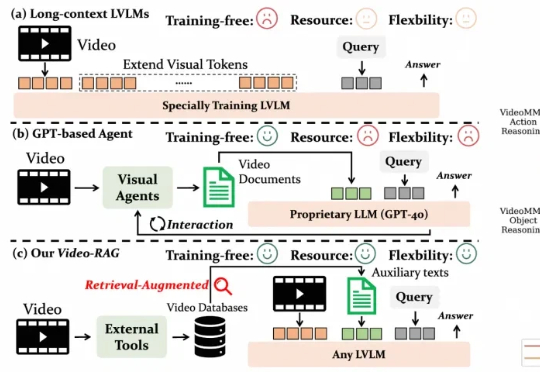
尽管视觉语言模型(LVLMs)在图像与短视频理解中已取得显著进展,但在处理长时序、复杂语义的视频内容时仍面临巨大挑战 —— 上下文长度限制、跨模态对齐困难、计算成本高昂等问题制约着其实际应用。针对这一难题,厦门大学、罗切斯特大学与南京大学联合提出了一种轻量高效、无需微调的创新框架 ——Video-RAG。

今年,流匹配无疑是机器人学习领域的大热门:作为扩散模型的一种优雅的变体,流匹配凭借简单、好用的特点,成为了机器人底层操作策略的主流手段,并被广泛应用于先进的 VLA 模型之中 —— 无论是 Physical Intelligence 的 ,LeRobot 的 SmolVLA, 英伟达的 GR00T 和近期清华大学发布的 RDT2。