
刚刚,北大&360里程碑式突破!32B安全分碾压千亿巨兽
刚刚,北大&360里程碑式突破!32B安全分碾压千亿巨兽打破思维惯性,「小模型」也能安全又强大!北大-360联合实验室发布TinyR1-32B模型,以仅20k数据的微调,实现了安全性能的里程碑式突破,并兼顾出色的推理与通用能力。
来自主题: AI资讯
8463 点击 2025-09-28 09:54
 搜索
搜索
打破思维惯性,「小模型」也能安全又强大!北大-360联合实验室发布TinyR1-32B模型,以仅20k数据的微调,实现了安全性能的里程碑式突破,并兼顾出色的推理与通用能力。
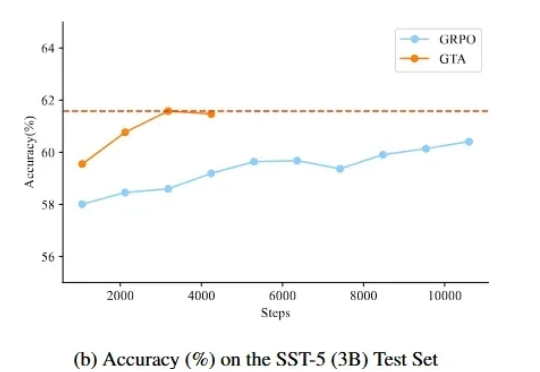
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。

LeCun 这次不是批评 LLM,而是亲自改造。当前 LLM 的训练(包括预训练、微调和评估)主要依赖于在「输入空间」进行重构与生成,例如预测下一个词。 而在 CV 领域,基于「嵌入空间」的训练目标,如联合嵌入预测架构(JEPA),已被证明远优于在输入空间操作的同类方法。

9 月 16 日,OpenAI 正式推出一款新模型 GPT-5-Codex ,这是一个经过微调的 GPT-5 变体,专门为其各种 AI 辅助编程工具而设计。该公司表示,新模型 GPT-5-Codex 的“思考”时间比之前的模型更加动态,完成一项编码任务所需的时间从几秒到七个小时不等。因此,它在代理编码基准测试中表现更佳。
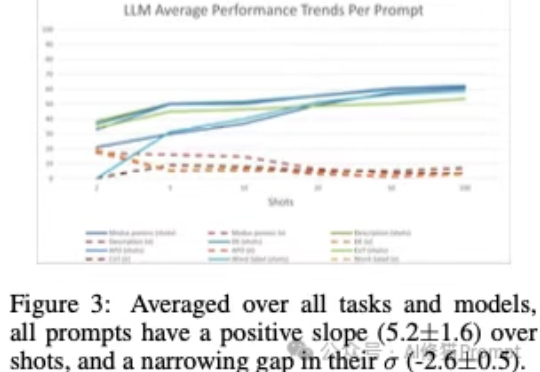
上下文学习”(In-Context Learning,ICL),是大模型不需要微调(fine-tuning),仅通过分析在提示词中给出的几个范例,就能解决当前任务的能力。您可能已经对这个场景再熟悉不过了:您在提示词里扔进去几个例子,然后,哇!大模型似乎瞬间就学会了一项新技能,表现得像个天才。
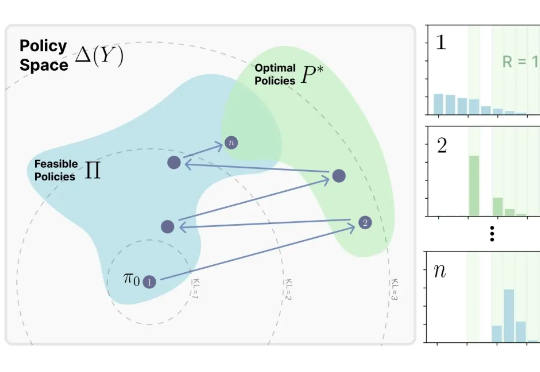
来自MIT Improbable AI Lab的研究者们最近发表了一篇题为《RL's Razor: Why Online Reinforcement Learning Forgets Less》的论文,系统性地回答了这个问题,他们不仅通过大量实验证实了这一现象,更进一步提出了一个简洁而深刻的解释,并将其命名为 “RL's Razor”(RL的剃刀)。
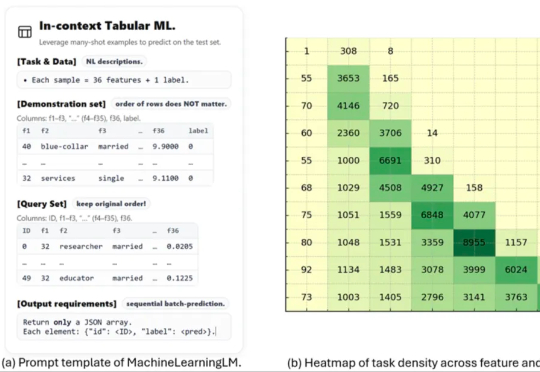
这项名为 MachineLearningLM 的新研究突破了这一瓶颈。该研究提出了一种轻量且可移植的「继续预训练」框架,无需下游微调即可直接通过上下文学习上千条示例,在金融、健康、生物信息、物理等等多个领域的二分类 / 多分类任务中的准确率显著超越基准模型(Qwen-2.5-7B-Instruct)以及最新发布的 GPT-5-mini。
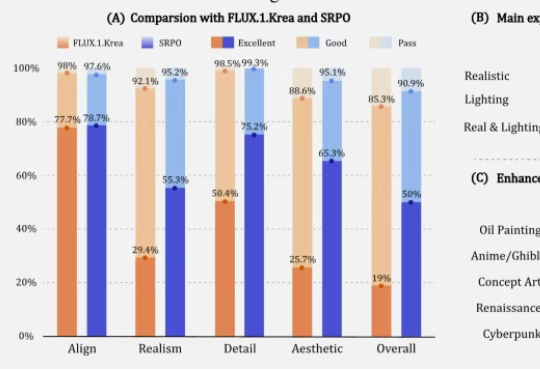
让AI生成的图像更符合人类精细偏好,在32块H20上训练10分钟就能收敛。腾讯混元新方法让微调的FLUX1.dev模型人工评估的真实感和美学评分提高3倍以上。
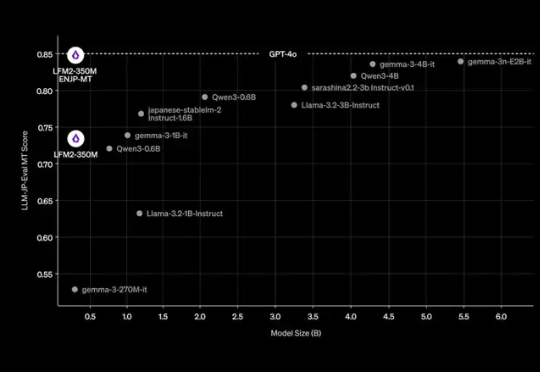
在大模型的竞赛中,参数规模往往被视为性能的决定性因素。但近期,Liquid AI 的研究团队提出了一个不同寻常的案例:一个仅有 3.5 亿参数的模型,经过微调后,竟能在中短上下文的实时日语英语翻译任务上,与 GPT-4o 竞争。
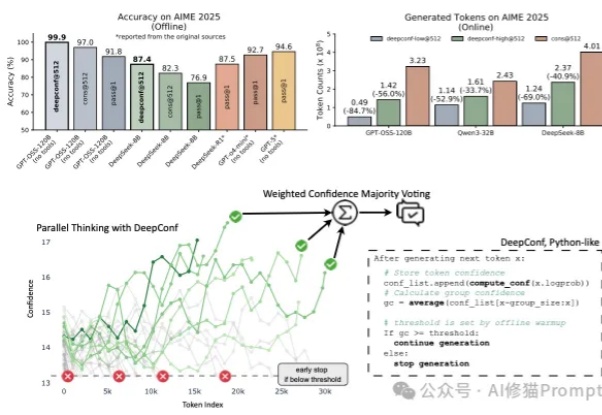
在大型语言模型(LLM)进行数学题、逻辑推理等复杂任务时,一个非常流行且有效的方法叫做 “自洽性”(Self-Consistency),通常也被称为“平行思考”。