ICML 2026|传统UED瓶颈被打破,强化学习也能精准定位「最近发展区」
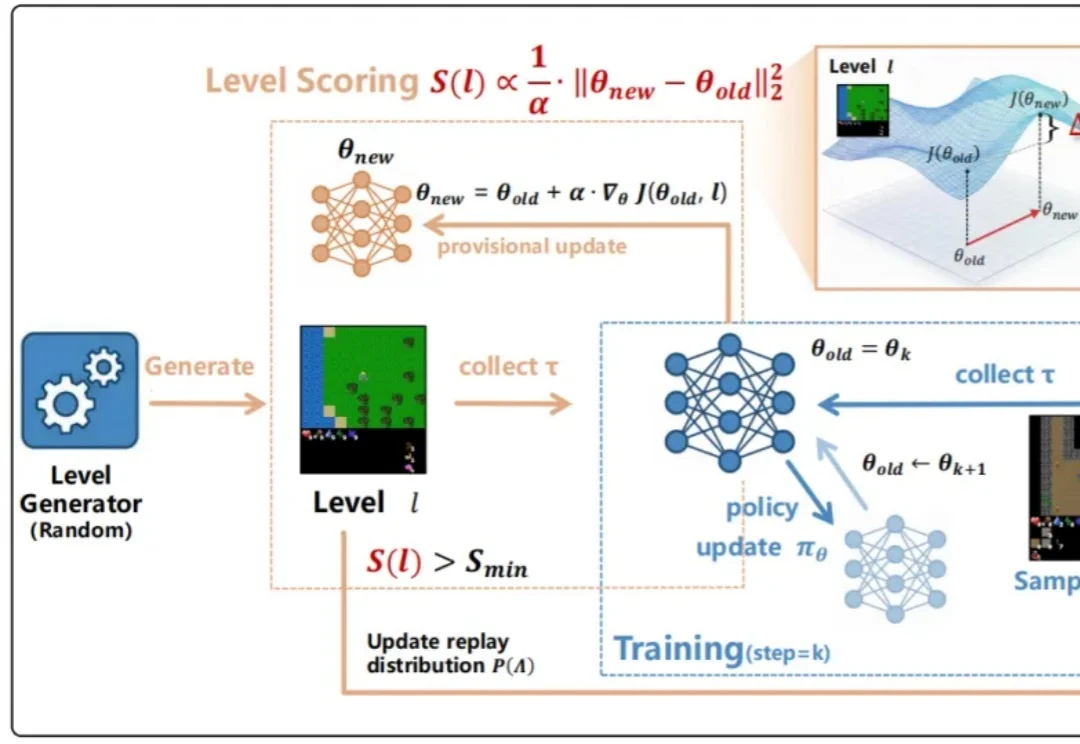
ICML 2026|传统UED瓶颈被打破,强化学习也能精准定位「最近发展区」训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。
来自主题: AI技术研报
9019 点击 2026-05-22 08:45
 搜索
搜索
训练强化学习智能体时,一个常见问题是:有些 level 太简单,智能体跑几遍就会;有些 level 又太难,智能体几乎得不到有效反馈。前者只是在重复已有能力,后者则会把训练预算消耗在无效探索上。真正有价值的训练环境,往往位于二者之间。
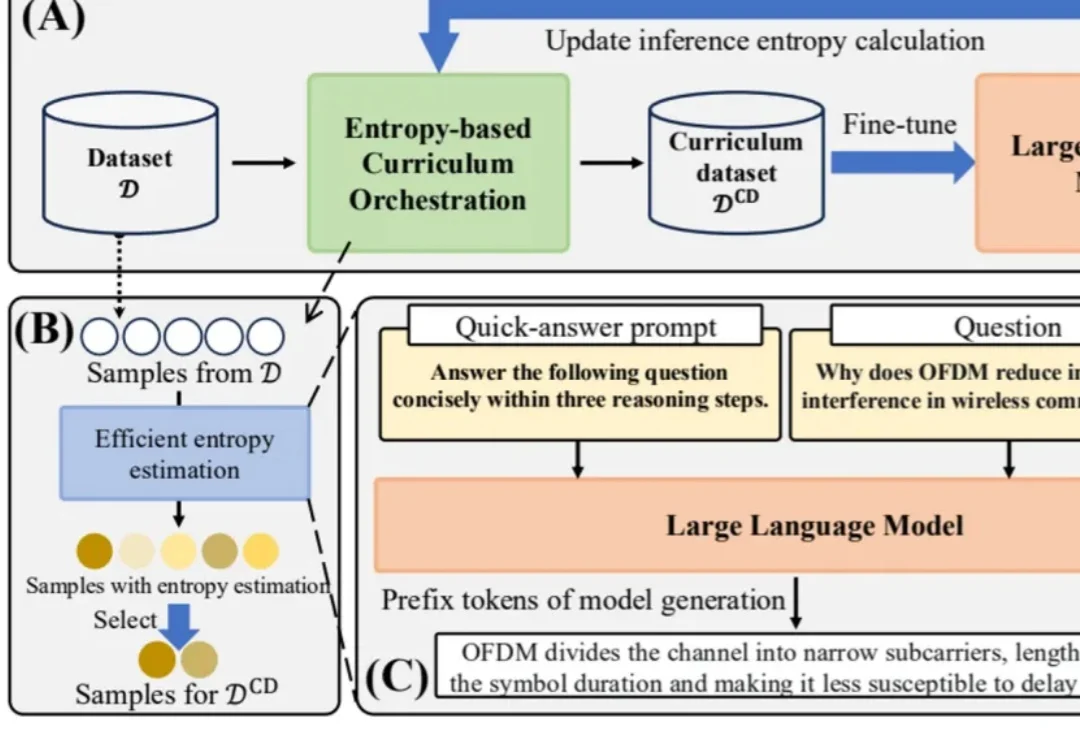
在大模型后训练中,数据不再只是 “越多越好”,而是要像人类学习一样,动态选择最合适难度的样本。华为提出的 EDCO 方法,将样本难度估计与动态课程编排引入领域大模型微调;数月后,由 Rutgers、Amazon、Google 等作者参与的 DARE 论文即引用 EDCO,并将其作为难度感知强化学习训练的重要对比基线。

浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。World-R1 的出发点很简单:预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。

当下的大模型后训练(Post-training)pipeline 中,On-Policy Distillation(OPD)已经成为了明星技术。从 Qwen3、MiMo 到 GLM-5,业界纷纷采用 OPD 并报告了巨大的性能提升。相比于强化学习(RL)稀疏的结果奖励,OPD 提供了密集的 Token 级别监督信号,看起来就像是一顿「免费的午餐」。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。

近日,原力灵机开源的具身智能原生框架 Dexbotic 宣布正式支持以 RLinf 作为其分布式强化学习后端。对具身智能开发者而言,这不仅是一次普通的工程适配,更意味着 VLA 模型研发中长期存在的「SFT 与 RL 割裂」问题,正在被真正打通。

没有训练梯度的AI,打破了Atari游戏满分纪录。OpenAI核心研究员翁家翌提出了一个强化学习新范式——启发式学习(Heuristic Learning, HL)。

大模型时代的「炼金术师」们,或许都曾面临一个共同的困扰:当我们试图将 DeepSeek-R1、OpenAI-o1 那种惊艳的推理能力迁移到小规模语言模型(SLMs)时,效果却总是差强人意。现有的强化学习方法如 GRPO 在 7B+ 的大模型上效果显著,但一旦应用到 1.7B 甚至更小参数的模型上,性能提升就微乎其微。

用强化学习(RL)优化文生图模型的 prompt following 能力,是一条被广泛验证的路径 —— 让模型根据 prompt 用不同随机种子生成多张图片,通过 reward model 计算 reward,再利用相关 RL 算法优化模型。

智元机器人的办公室里,最近员工们一上班就能看到机器人熟练地切着水果:这么全面的能力是如何做到的?答案是直接在真实环境中搞大规模分布式强化学习训练。它们使用的是全新的具身智能训练范式:面向通用机器人策略的分布式多机强化学习(LWD)。这一套技术捅破了当前VLA的「天花板」。