独家|姚颂三度创业,Striding AI获近亿美元融资入局物理智能
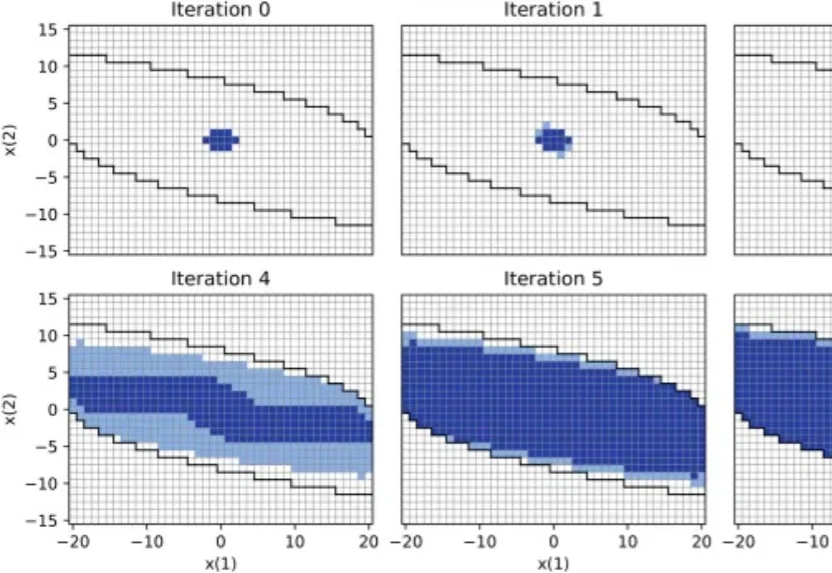
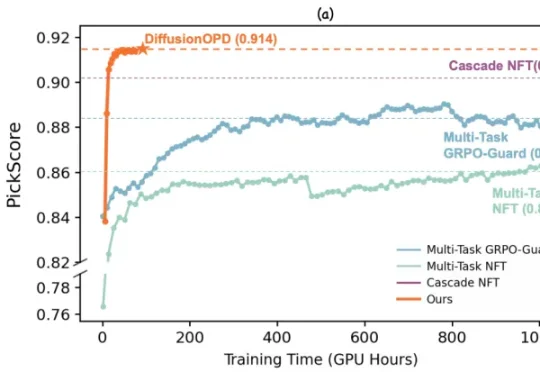
独家|姚颂三度创业,Striding AI获近亿美元融资入局物理智能公司由姚颂联合正大集团、清华青年学者于超共同发起,定位为物理智能系统公司,通过世界动作模型(WAM)与强化学习技术,推动机器人在真实商业与工业场景中落地,最终成为一个可信赖的机器人服务提供商。目前已完成近亿美元天使轮系列融资,投资方包括正大集团、华勤技术、九安医疗等多家上市企业,多位国内与国际知名企业家,以及多家一线投资机构。
来自主题: AI资讯
8208 点击 2026-06-24 21:41