
20 岁创始人,招 18 岁员工,被 19 岁的人投资
20 岁创始人,招 18 岁员工,被 19 岁的人投资“这个时代对非凡的奖励从未如此丰厚,对平凡的惩罚从未如此严厉。”
来自主题: AI资讯
7413 点击 2026-06-23 10:23
 搜索
搜索
“这个时代对非凡的奖励从未如此丰厚,对平凡的惩罚从未如此严厉。”
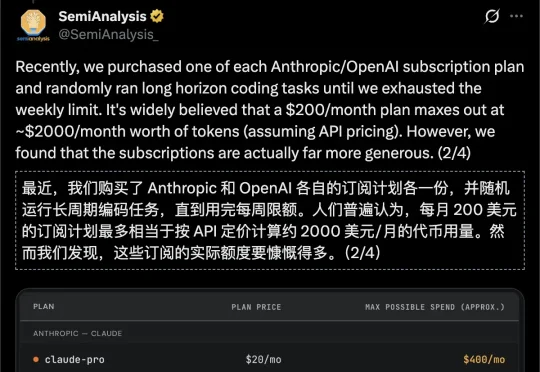
你以为自己在薅AI羊毛?OpenAI和Anthropic却在笑看账本。200美元的个人订阅,根本不是在卖服务,而是在批量培养「病毒式销售员」。

有人欢呼,这是OpenAI「最开放」的一次。给Codex装上能随便换模型的插座,等于亲手填平自己模型的护城河。它图什么?
数据库自动调参,一直是大模型Agent的“看似完美、实则翻车”名场面。

数学界的“最强大脑”,快被AI出的证明淹没了。

三星电子正在全球范围内向员工部署 ChatGPT Enterprise 和 Codex,以加速公司内部人工智能的采用。根据协议,ChatGPT 和 Codex 将面向三星电子韩国的所有员工以及其设备体验 (DX) 部门的全球所有员工开放。这是 OpenAI 迄今为止规模最大的企业级部署之一。

好你个微软,当起大模型“倒爷”来了?!

近日,香港特区政府教育局公布《中小学数字教育发展蓝图》。与过去侧重设备建设和数字工具应用的信息化政策不同,这份文件把课程框架、教师培训、学校治理和资源投入放进同一套制度设计之中,为未来几年香港中小学推进人工智能教育划出了具体路线图。

刚刚,豆包悄然上线打车服务。智东西发现,获得灰测资格的用户已经可以直接在豆包App内使用打车功能,底层运力由曹操出行提供。从体验来看,整个流程与传统打车软件相比进一步简化。

家人们,硅谷这次真的把抽象玩明白了。