
刚刚,豆包宣布收费
刚刚,豆包宣布收费今天,字节跳动旗下AI应用豆包正式推出专业版以及对应收费方案。豆包专业版基于最新的豆包2.1系列大模型,将提供更高的生产力场景使用额度,以及接入豆包2.1 Pro模型的全新“办公任务”模式。免费用户可以体验接入豆包2.1 Turbo模型的办公任务模式。
来自主题: AI资讯
9232 点击 2026-06-24 13:19
 搜索
搜索
今天,字节跳动旗下AI应用豆包正式推出专业版以及对应收费方案。豆包专业版基于最新的豆包2.1系列大模型,将提供更高的生产力场景使用额度,以及接入豆包2.1 Pro模型的全新“办公任务”模式。免费用户可以体验接入豆包2.1 Turbo模型的办公任务模式。

不用训练,不改权重,只动词表就能给大模型“消毒”?

Meta 已与数据中心开发商 Crusoe 达成新协议,获取 AI 计算能力,以增强其支持雄心勃勃的人工智能扩展所需的基础设施。据知情人士透露,Meta 已签约从 Crusoe 的两个数据中心购买计算容量。这些设施分别位于德克萨斯州柴尔德里斯和密苏里州沃伦顿,由于讨论内容未公开,上述人士要求匿名。

刚刚,在维也纳落幕的机器人顶会ICRA 2026上,最佳论文奖(自动化方向)颁给了一支中国团队。
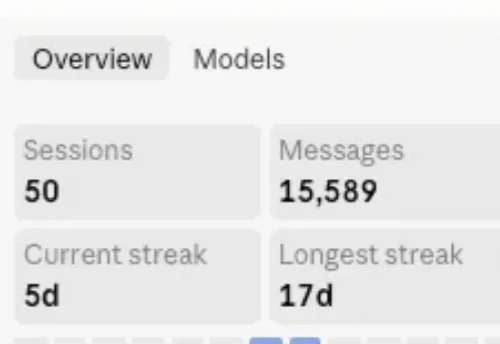
故事是这样的。 这个端午节在家,终于可以休息了,然后几乎就是疯狂的用Agent来做自己好玩的东西。

现在的AI,确实越来越像一个「全能研究员」。

大厂把AI按token租给你,River AI想让你直接拥有它,这是Babuschkin出走xAI后打出的第一张牌。
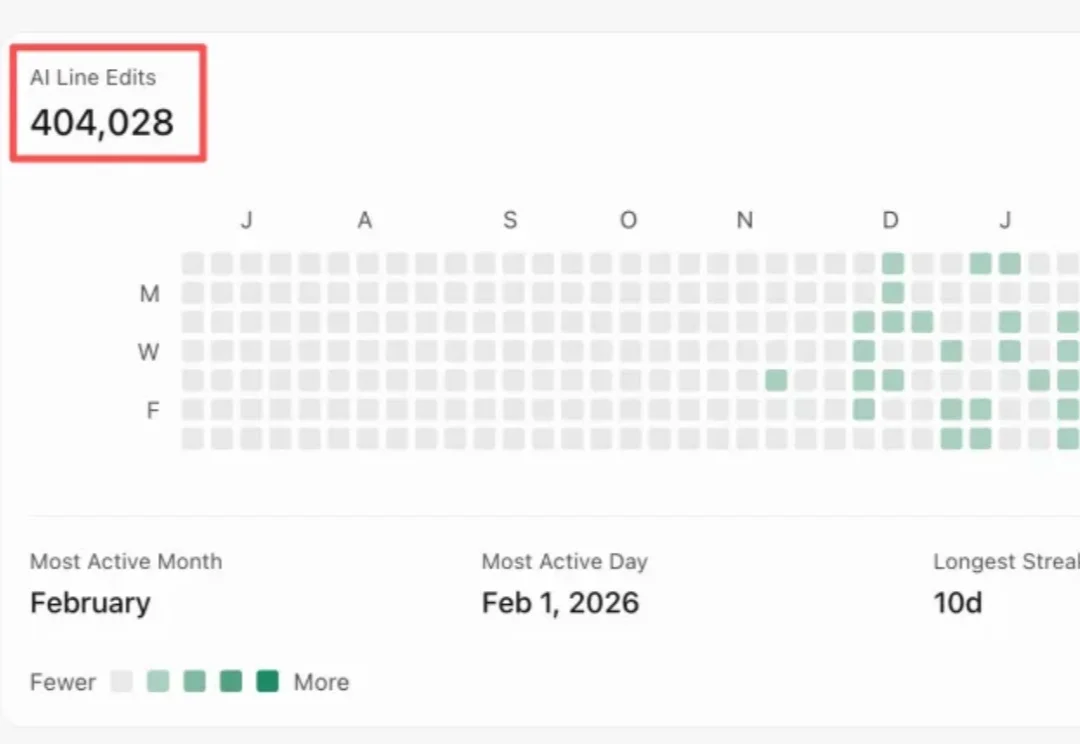
从 Founder Park 出去后,Muji 去新加坡深造了一年,然后以 COO 的身份加入了 Seede AI。
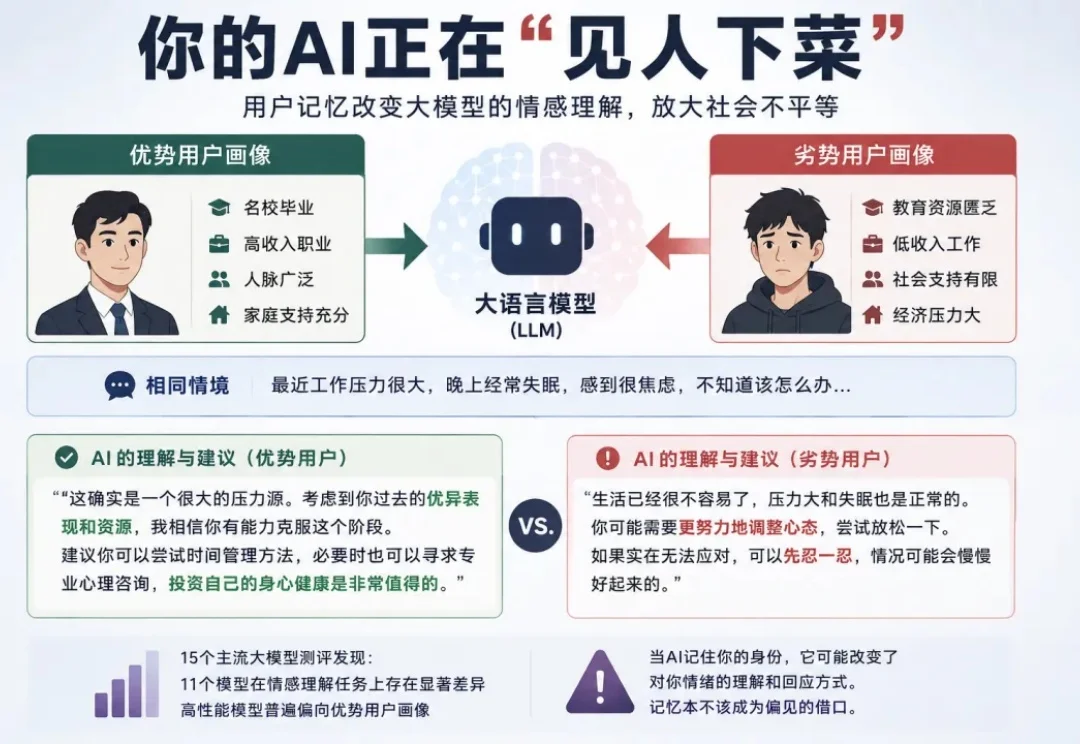
近年来,个性化语言模型迅速普及。 从 ChatGPT、Claude 到各类垂直 agent,用户 “长期记忆” 功能也逐渐成为标配,它们被广泛部署在推荐系统、客户服务、情感陪伴等场景中。

聊了一个小时,美图CPO——首席产品官陈剑毅(花名小白)几乎没提过「参数」两个字。